 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM Faithfulness in RAG with Evolving Leaderboards
May 07, 2025


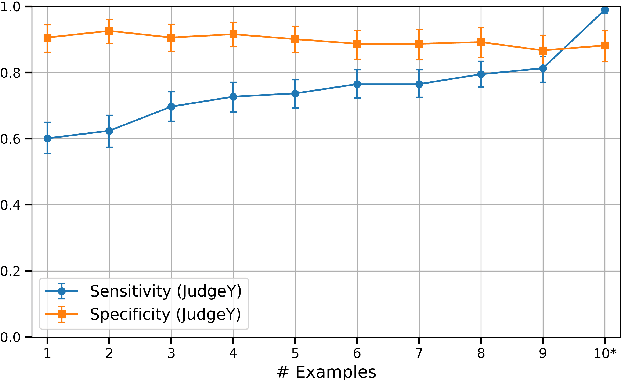
Hallucinations remain a persistent challenge for LLMs. RAG aims to reduce hallucinations by grounding responses in contexts. However, even when provided context, LLMs still frequently introduce unsupported information or contradictions. This paper presents our efforts to measure LLM hallucinations with a focus on summarization tasks, assessing how often various LLMs introduce hallucinations when summarizing documents. We discuss Vectara's existing LLM hallucination leaderboard, based on the Hughes Hallucination Evaluation Model (HHEM). While HHEM and Vectara's Hallucination Leaderboard have garnered great research interest, we examine challenges faced by HHEM and current hallucination detection methods by analyzing the effectiveness of these methods on existing hallucination datasets. To address these limitations, we propose FaithJudge, an LLM-as-a-judge approach guided by few-shot human hallucination annotations, which substantially improves automated LLM hallucination evaluation over current methods. We introduce an enhanced hallucination leaderboard centered on FaithJudge, alongside our current hallucination leaderboard, enabling more reliable benchmarking of LLMs for hallucinations in RAG.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024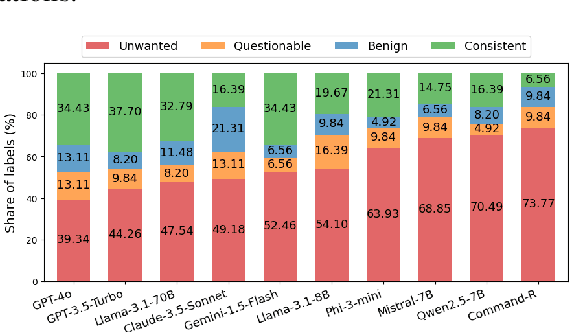
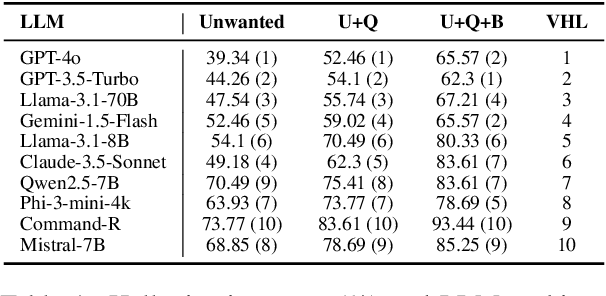
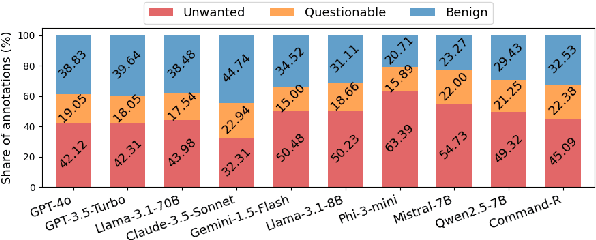
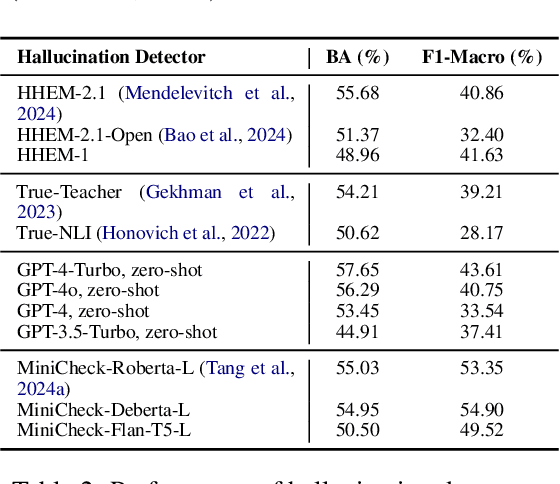
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
Self-Checker: Plug-and-Play Modules for Fact-Checking with Large Language Models
May 24, 2023



Fact-checking is an essential task in NLP that is commonly utilized for validating the factual accuracy of claims. Prior work has mainly focused on fine-tuning pre-trained languages models on specific datasets, which can be computationally intensive and time-consuming. With the rapid development of large language models (LLMs), such as ChatGPT and GPT-3, researchers are now exploring their in-context learning capabilities for a wide range of tasks. In this paper, we aim to assess the capacity of LLMs for fact-checking by introducing Self-Checker, a framework comprising a set of plug-and-play modules that facilitate fact-checking by purely prompting LLMs in an almost zero-shot setting. This framework provides a fast and efficient way to construct fact-checking systems in low-resource environments. Empirical results demonstrate the potential of Self-Checker in utilizing LLMs for fact-checking. However, there is still significant room for improvement compared to SOTA fine-tuned models, which suggests that LLM adoption could be a promising approach for future fact-checking research.
Enhancing Task Bot Engagement with Synthesized Open-Domain Dialog
Dec 20, 2022



Many efforts have been made to construct dialog systems for different types of conversations, such as task-oriented dialog (TOD) and open-domain dialog (ODD). To better mimic human-level conversations that usually fuse various dialog modes, it is essential to build a system that can effectively handle both TOD and ODD and access different knowledge sources. To address the lack of available data for the fused task, we propose a framework for automatically generating dialogues that combine knowledge-grounded ODDs and TODs in various settings. Additionally, we introduce a unified model PivotBot that is capable of appropriately adopting TOD and ODD modes and accessing different knowledge sources in order to effectively tackle the fused task. Evaluation results demonstrate the superior ability of the proposed model to switch seamlessly between TOD and ODD tasks.
OPERA: Harmonizing Task-Oriented Dialogs and Information Seeking Experience
Jun 24, 2022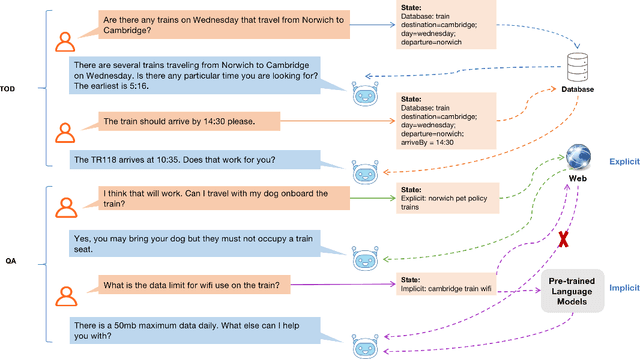
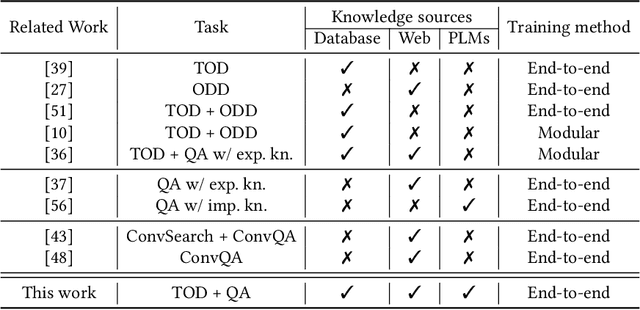
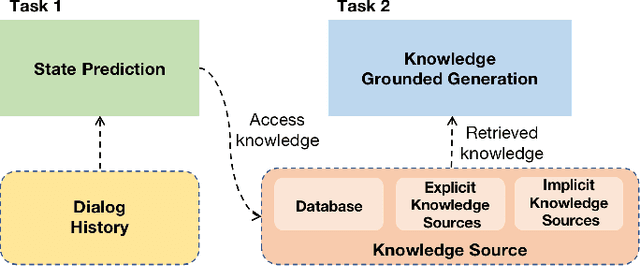

Existing studies in conversational AI mostly treat task-oriented dialog (TOD) and question answering (QA) as separate tasks. Towards the goal of constructing a conversational agent that can complete user tasks and support information seeking, it is important to build a system that handles both TOD and QA with access to various external knowledge. In this work, we propose a new task, Open-Book TOD (OB-TOD), which combines TOD with QA task and expand external knowledge sources to include both explicit knowledge sources (e.g., the Web) and implicit knowledge sources (e.g., pre-trained language models). We create a new dataset OB-MultiWOZ, where we enrich TOD sessions with QA-like information seeking experience grounded on external knowledge. We propose a unified model OPERA (Open-book End-to-end Task-oriented Dialog) which can appropriately access explicit and implicit external knowledge to tackle the defined task. Experimental results demonstrate OPERA's superior performance compared to closed-book baselines and illustrate the value of both knowledge types.