 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM Faithfulness in RAG with Evolving Leaderboards
May 07, 2025


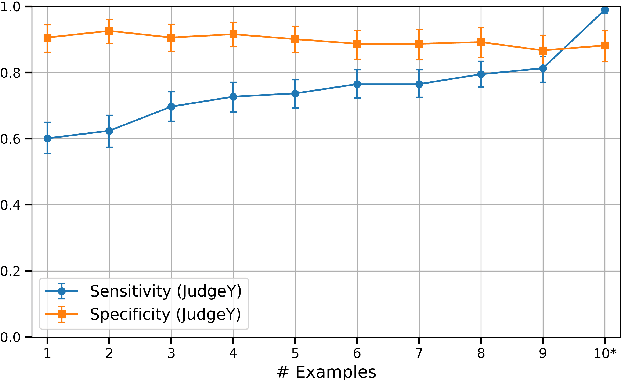
Hallucinations remain a persistent challenge for LLMs. RAG aims to reduce hallucinations by grounding responses in contexts. However, even when provided context, LLMs still frequently introduce unsupported information or contradictions. This paper presents our efforts to measure LLM hallucinations with a focus on summarization tasks, assessing how often various LLMs introduce hallucinations when summarizing documents. We discuss Vectara's existing LLM hallucination leaderboard, based on the Hughes Hallucination Evaluation Model (HHEM). While HHEM and Vectara's Hallucination Leaderboard have garnered great research interest, we examine challenges faced by HHEM and current hallucination detection methods by analyzing the effectiveness of these methods on existing hallucination datasets. To address these limitations, we propose FaithJudge, an LLM-as-a-judge approach guided by few-shot human hallucination annotations, which substantially improves automated LLM hallucination evaluation over current methods. We introduce an enhanced hallucination leaderboard centered on FaithJudge, alongside our current hallucination leaderboard, enabling more reliable benchmarking of LLMs for hallucinations in RAG.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024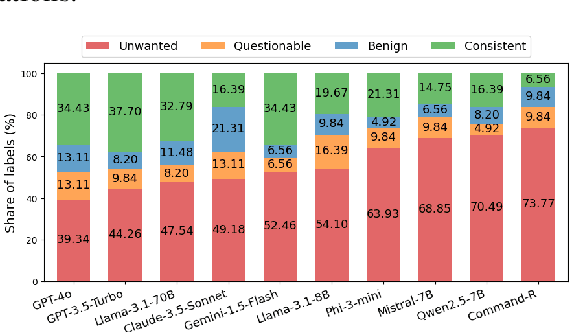
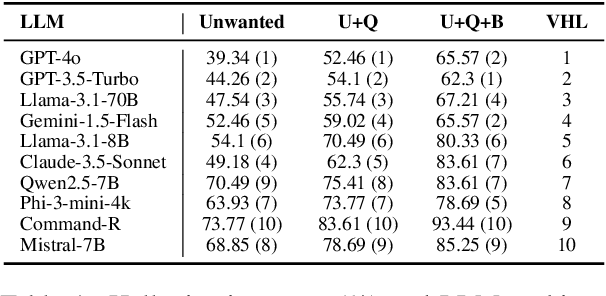
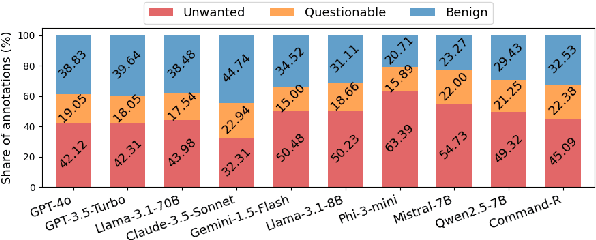
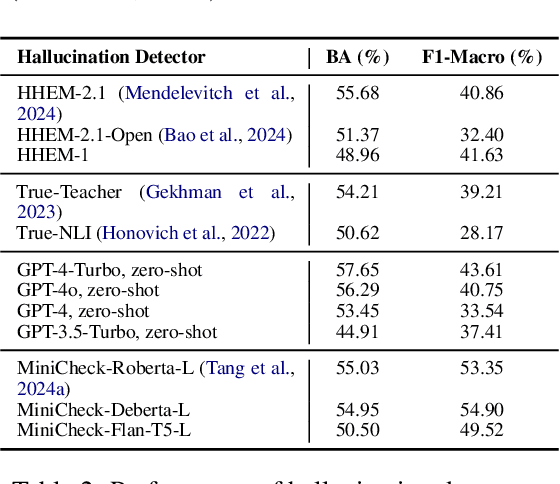
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
Is Semantic Chunking Worth the Computational Cost?
Oct 16, 2024



Recent advances in Retrieval-Augmented Generation (RAG) systems have popularized semantic chunking, which aims to improve retrieval performance by dividing documents into semantically coherent segments. Despite its growing adoption, the actual benefits over simpler fixed-size chunking, where documents are split into consecutive, fixed-size segments, remain unclear. This study systematically evaluates the effectiveness of semantic chunking using three common retrieval-related tasks: document retrieval, evidence retrieval, and retrieval-based answer generation. The results show that the computational costs associated with semantic chunking are not justified by consistent performance gains. These findings challenge the previous assumptions about semantic chunking and highlight the need for more efficient chunking strategies in RAG systems.
LLM-based Hierarchical Concept Decomposition for Interpretable Fine-Grained Image Classification
May 29, 2024Recent advancements in interpretable models for vision-language tasks have achieved competitive performance; however, their interpretability often suffers due to the reliance on unstructured text outputs from large language models (LLMs). This introduces randomness and compromises both transparency and reliability, which are essential for addressing safety issues in AI systems. We introduce \texttt{Hi-CoDe} (Hierarchical Concept Decomposition), a novel framework designed to enhance model interpretability through structured concept analysis. Our approach consists of two main components: (1) We use GPT-4 to decompose an input image into a structured hierarchy of visual concepts, thereby forming a visual concept tree. (2) We then employ an ensemble of simple linear classifiers that operate on concept-specific features derived from CLIP to perform classification. Our approach not only aligns with the performance of state-of-the-art models but also advances transparency by providing clear insights into the decision-making process and highlighting the importance of various concepts. This allows for a detailed analysis of potential failure modes and improves model compactness, therefore setting a new benchmark in interpretability without compromising the accuracy.