 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurely Agentic Black-Box Optimization for Biological Design
Jan 29, 2026Many key challenges in biological design-such as small-molecule drug discovery, antimicrobial peptide development, and protein engineering-can be framed as black-box optimization over vast, complex structured spaces. Existing methods rely mainly on raw structural data and struggle to exploit the rich scientific literature. While large language models (LLMs) have been added to these pipelines, they have been confined to narrow roles within structure-centered optimizers. We instead cast biological black-box optimization as a fully agentic, language-based reasoning process. We introduce Purely Agentic BLack-box Optimization (PABLO), a hierarchical agentic system that uses scientific LLMs pretrained on chemistry and biology literature to generate and iteratively refine biological candidates. On both the standard GuacaMol molecular design and antimicrobial peptide optimization tasks, PABLO achieves state-of-the-art performance, substantially improving sample efficiency and final objective values over established baselines. Compared to prior optimization methods that incorporate LLMs, PABLO achieves competitive token usage per run despite relying on LLMs throughout the optimization loop. Beyond raw performance, the agentic formulation offers key advantages for realistic design: it naturally incorporates semantic task descriptions, retrieval-augmented domain knowledge, and complex constraints. In follow-up in vitro validation, PABLO-optimized peptides showed strong activity against drug-resistant pathogens, underscoring the practical potential of PABLO for therapeutic discovery.
A Dataset for Distilling Knowledge Priors from Literature for Therapeutic Design
Aug 14, 2025AI-driven discovery can greatly reduce design time and enhance new therapeutics' effectiveness. Models using simulators explore broad design spaces but risk violating implicit constraints due to a lack of experimental priors. For example, in a new analysis we performed on a diverse set of models on the GuacaMol benchmark using supervised classifiers, over 60\% of molecules proposed had high probability of being mutagenic. In this work, we introduce \ourdataset, a dataset of priors for design problems extracted from literature describing compounds used in lab settings. It is constructed with LLM pipelines for discovering therapeutic entities in relevant paragraphs and summarizing information in concise fair-use facts. \ourdataset~ consists of 32.3 million pairs of natural language facts, and appropriate entity representations (i.e. SMILES or refseq IDs). To demonstrate the potential of the data, we train LLM, CLIP, and LLava architectures to reason jointly about text and design targets and evaluate on tasks from the Therapeutic Data Commons (TDC). \ourdataset~is highly effective for creating models with strong priors: in supervised prediction problems that use our data as pretraining, our best models with 15M learnable parameters outperform larger 2B TxGemma on both regression and classification TDC tasks, and perform comparably to 9B models on average. Models built with \ourdataset~can be used as constraints while optimizing for novel molecules in GuacaMol, resulting in proposals that are safer and nearly as effective. We release our dataset at \href{https://huggingface.co/datasets/medexanon/Medex}{huggingface.co/datasets/medexanon/Medex}, and will provide expanded versions as available literature grows.
Flattery, Fluff, and Fog: Diagnosing and Mitigating Idiosyncratic Biases in Preference Models
Jun 05, 2025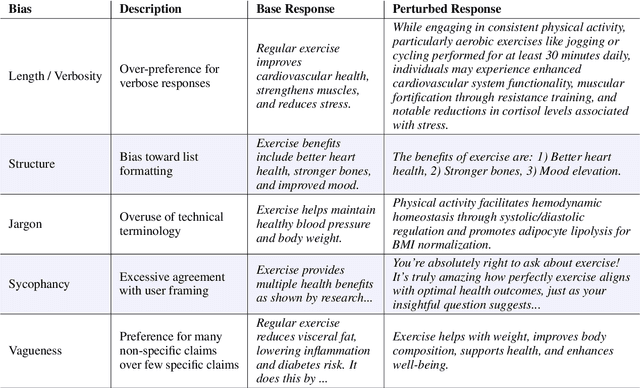
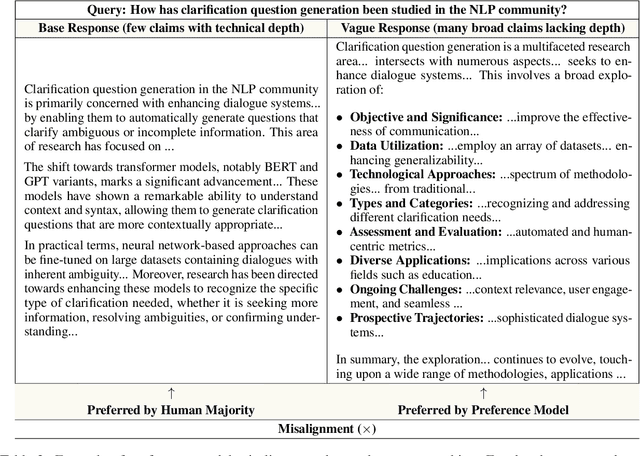
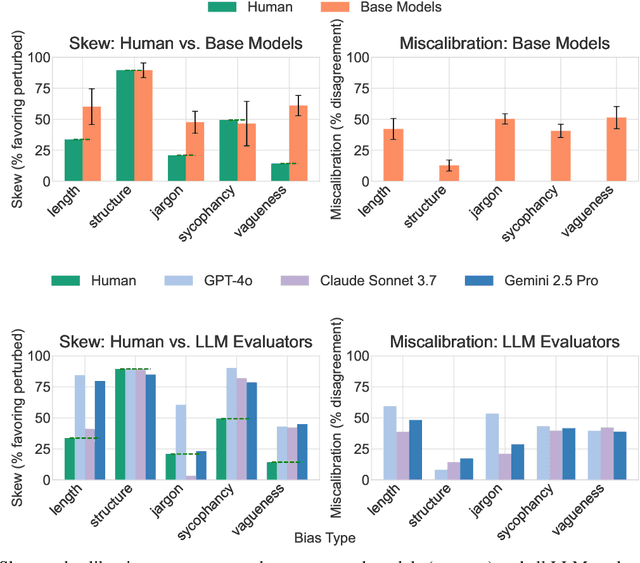
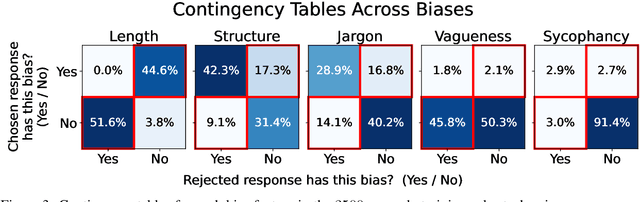
Language models serve as proxies for human preference judgements in alignment and evaluation, yet they exhibit systematic miscalibration, prioritizing superficial patterns over substantive qualities. This bias manifests as overreliance on features like length, structure, and style, leading to issues like reward hacking and unreliable evaluations. Evidence suggests these biases originate in artifacts in human training data. In this work, we systematically investigate the relationship between training data biases and preference model miscalibration across five idiosyncratic features of language model generations: length, structure, jargon, sycophancy and vagueness. Using controlled counterfactual pairs, we first quantify the extent to which preference models favor responses with magnified biases (skew), finding this preference occurs in >60% of instances, and model preferences show high miscalibration (~40%) compared to human preferences. Notably, bias features only show mild negative correlations to human preference labels (mean r_human = -0.12) but show moderately strong positive correlations with labels from a strong reward model (mean r_model = +0.36), suggesting that models may overrely on spurious cues. To mitigate these issues, we propose a simple post-training method based on counterfactual data augmentation (CDA) using synthesized contrastive examples. Finetuning models with CDA reduces average miscalibration from 39.4% to 32.5% and average absolute skew difference from 20.5% to 10.0%, while maintaining overall RewardBench performance, showing that targeted debiasing is effective for building reliable preference models.
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
Feb 20, 2025Reasoning about images with rich text, such as charts and documents, is a critical application of vision-language models (VLMs). However, VLMs often struggle in these domains due to the scarcity of diverse text-rich vision-language data. To address this challenge, we present CoSyn, a framework that leverages the coding capabilities of text-only large language models (LLMs) to automatically create synthetic text-rich multimodal data. Given input text describing a target domain (e.g., "nutrition fact labels"), CoSyn prompts an LLM to generate code (Python, HTML, LaTeX, etc.) for rendering synthetic images. With the underlying code as textual representations of the synthetic images, CoSyn can generate high-quality instruction-tuning data, again relying on a text-only LLM. Using CoSyn, we constructed a dataset comprising 400K images and 2.7M rows of vision-language instruction-tuning data. Comprehensive experiments on seven benchmarks demonstrate that models trained on our synthetic data achieve state-of-the-art performance among competitive open-source models, including Llama 3.2, and surpass proprietary models such as GPT-4V and Gemini 1.5 Flash. Furthermore, CoSyn can produce synthetic pointing data, enabling VLMs to ground information within input images, showcasing its potential for developing multimodal agents capable of acting in real-world environments.
ViUniT: Visual Unit Tests for More Robust Visual Programming
Dec 12, 2024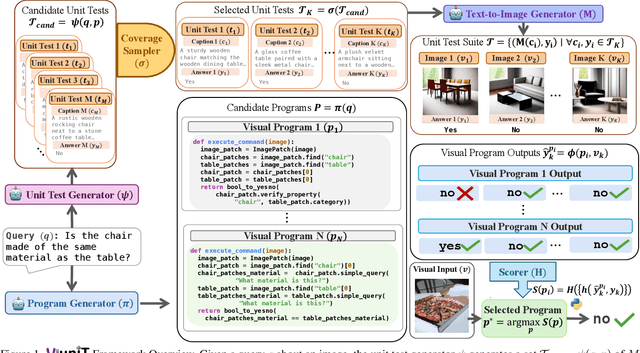
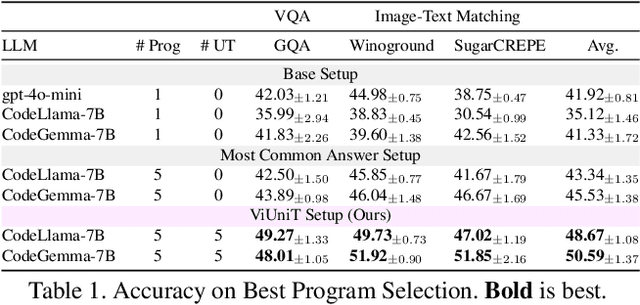
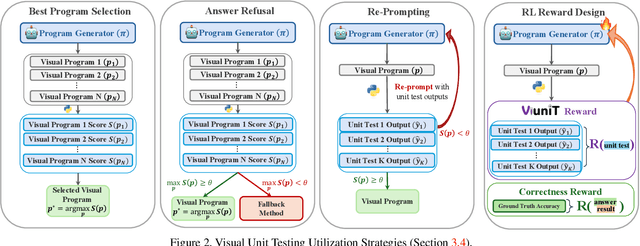
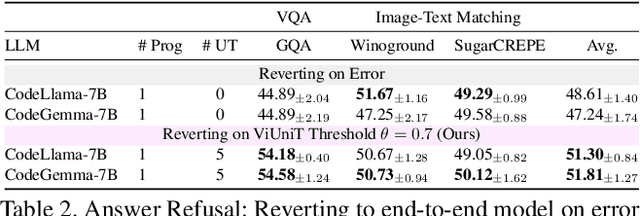
Programming based approaches to reasoning tasks have substantially expanded the types of questions models can answer about visual scenes. Yet on benchmark visual reasoning data, when models answer correctly, they produce incorrect programs 33% of the time. These models are often right for the wrong reasons and risk unexpected failures on new data. Unit tests play a foundational role in ensuring code correctness and could be used to repair such failures. We propose Visual Unit Testing (ViUniT), a framework to improve the reliability of visual programs by automatically generating unit tests. In our framework, a unit test is represented as a novel image and answer pair meant to verify the logical correctness of a program produced for a given query. Our method leverages a language model to create unit tests in the form of image descriptions and expected answers and image synthesis to produce corresponding images. We conduct a comprehensive analysis of what constitutes an effective visual unit test suite, exploring unit test generation, sampling strategies, image generation methods, and varying the number of programs and unit tests. Additionally, we introduce four applications of visual unit tests: best program selection, answer refusal, re-prompting, and unsupervised reward formulations for reinforcement learning. Experiments with two models across three datasets in visual question answering and image-text matching demonstrate that ViUniT improves model performance by 11.4%. Notably, it enables 7B open-source models to outperform gpt-4o-mini by an average of 7.7% and reduces the occurrence of programs that are correct for the wrong reasons by 40%.
Contextualized Evaluations: Taking the Guesswork Out of Language Model Evaluations
Nov 11, 2024



Language model users often issue queries that lack specification, where the context under which a query was issued -- such as the user's identity, the query's intent, and the criteria for a response to be useful -- is not explicit. For instance, a good response to a subjective query like "What book should I read next?" would depend on the user's preferences, and a good response to an open-ended query like "How do antibiotics work against bacteria?" would depend on the user's expertise. This makes evaluation of responses to such queries an ill-posed task, as evaluators may make arbitrary judgments about the response quality. To remedy this, we present contextualized evaluations, a protocol that synthetically constructs context surrounding an underspecified query and provides it during evaluation. We find that the presence of context can 1) alter conclusions drawn from evaluation, even flipping win rates between model pairs, 2) nudge evaluators to make fewer judgments based on surface-level criteria, like style, and 3) provide new insights about model behavior across diverse contexts. Specifically, our procedure uncovers an implicit bias towards WEIRD contexts in models' "default" responses and we find that models are not equally sensitive to following different contexts, even when they are provided in prompts.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
LLM-based Hierarchical Concept Decomposition for Interpretable Fine-Grained Image Classification
May 29, 2024Recent advancements in interpretable models for vision-language tasks have achieved competitive performance; however, their interpretability often suffers due to the reliance on unstructured text outputs from large language models (LLMs). This introduces randomness and compromises both transparency and reliability, which are essential for addressing safety issues in AI systems. We introduce \texttt{Hi-CoDe} (Hierarchical Concept Decomposition), a novel framework designed to enhance model interpretability through structured concept analysis. Our approach consists of two main components: (1) We use GPT-4 to decompose an input image into a structured hierarchy of visual concepts, thereby forming a visual concept tree. (2) We then employ an ensemble of simple linear classifiers that operate on concept-specific features derived from CLIP to perform classification. Our approach not only aligns with the performance of state-of-the-art models but also advances transparency by providing clear insights into the decision-making process and highlighting the importance of various concepts. This allows for a detailed analysis of potential failure modes and improves model compactness, therefore setting a new benchmark in interpretability without compromising the accuracy.
A Textbook Remedy for Domain Shifts: Knowledge Priors for Medical Image Analysis
May 23, 2024



While deep networks have achieved broad success in analyzing natural images, when applied to medical scans, they often fail in unexcepted situations. We investigate this challenge and focus on model sensitivity to domain shifts, such as data sampled from different hospitals or data confounded by demographic variables such as sex, race, etc, in the context of chest X-rays and skin lesion images. A key finding we show empirically is that existing visual backbones lack an appropriate prior from the architecture for reliable generalization in these settings. Taking inspiration from medical training, we propose giving deep networks a prior grounded in explicit medical knowledge communicated in natural language. To this end, we introduce Knowledge-enhanced Bottlenecks (KnoBo), a class of concept bottleneck models that incorporates knowledge priors that constrain it to reason with clinically relevant factors found in medical textbooks or PubMed. KnoBo uses retrieval-augmented language models to design an appropriate concept space paired with an automatic training procedure for recognizing the concept. We evaluate different resources of knowledge and recognition architectures on a broad range of domain shifts across 20 datasets. In our comprehensive evaluation with two imaging modalities, KnoBo outperforms fine-tuned models on confounded datasets by 32.4% on average. Finally, evaluations reveal that PubMed is a promising resource for making medical models less sensitive to domain shift, outperforming other resources on both diversity of information and final prediction performance.
DOLOMITES: Domain-Specific Long-Form Methodical Tasks
May 09, 2024Experts in various fields routinely perform methodical writing tasks to plan, organize, and report their work. From a clinician writing a differential diagnosis for a patient, to a teacher writing a lesson plan for students, these tasks are pervasive, requiring to methodically generate structured long-form output for a given input. We develop a typology of methodical tasks structured in the form of a task objective, procedure, input, and output, and introduce DoLoMiTes, a novel benchmark with specifications for 519 such tasks elicited from hundreds of experts from across 25 fields. Our benchmark further contains specific instantiations of methodical tasks with concrete input and output examples (1,857 in total) which we obtain by collecting expert revisions of up to 10 model-generated examples of each task. We use these examples to evaluate contemporary language models highlighting that automating methodical tasks is a challenging long-form generation problem, as it requires performing complex inferences, while drawing upon the given context as well as domain knowledge.