 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutaGReP: Execution-Free Repository-Grounded Plan Search for Code-Use
Feb 21, 2025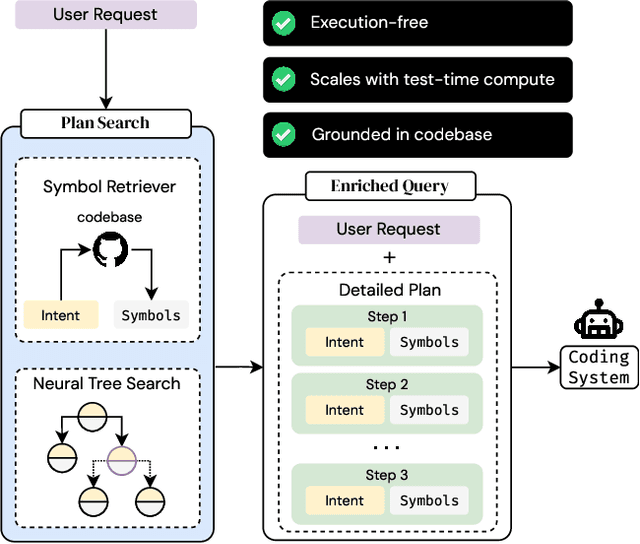



When a human requests an LLM to complete a coding task using functionality from a large code repository, how do we provide context from the repo to the LLM? One approach is to add the entire repo to the LLM's context window. However, most tasks involve only fraction of symbols from a repo, longer contexts are detrimental to the LLM's reasoning abilities, and context windows are not unlimited. Alternatively, we could emulate the human ability to navigate a large repo, pick out the right functionality, and form a plan to solve the task. We propose MutaGReP (Mutation-guided Grounded Repository Plan Search), an approach to search for plans that decompose a user request into natural language steps grounded in the codebase. MutaGReP performs neural tree search in plan space, exploring by mutating plans and using a symbol retriever for grounding. On the challenging LongCodeArena benchmark, our plans use less than 5% of the 128K context window for GPT-4o but rival the coding performance of GPT-4o with a context window filled with the repo. Plans produced by MutaGReP allow Qwen 2.5 Coder 32B and 72B to match the performance of GPT-4o with full repo context and enable progress on the hardest LongCodeArena tasks. Project page: zaidkhan.me/MutaGReP
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
Feb 20, 2025Reasoning about images with rich text, such as charts and documents, is a critical application of vision-language models (VLMs). However, VLMs often struggle in these domains due to the scarcity of diverse text-rich vision-language data. To address this challenge, we present CoSyn, a framework that leverages the coding capabilities of text-only large language models (LLMs) to automatically create synthetic text-rich multimodal data. Given input text describing a target domain (e.g., "nutrition fact labels"), CoSyn prompts an LLM to generate code (Python, HTML, LaTeX, etc.) for rendering synthetic images. With the underlying code as textual representations of the synthetic images, CoSyn can generate high-quality instruction-tuning data, again relying on a text-only LLM. Using CoSyn, we constructed a dataset comprising 400K images and 2.7M rows of vision-language instruction-tuning data. Comprehensive experiments on seven benchmarks demonstrate that models trained on our synthetic data achieve state-of-the-art performance among competitive open-source models, including Llama 3.2, and surpass proprietary models such as GPT-4V and Gemini 1.5 Flash. Furthermore, CoSyn can produce synthetic pointing data, enabling VLMs to ground information within input images, showcasing its potential for developing multimodal agents capable of acting in real-world environments.
The One RING: a Robotic Indoor Navigation Generalist
Dec 18, 2024



Modern robots vary significantly in shape, size, and sensor configurations used to perceive and interact with their environments. However, most navigation policies are embodiment-specific; a policy learned using one robot's configuration does not typically gracefully generalize to another. Even small changes in the body size or camera viewpoint may cause failures. With the recent surge in custom hardware developments, it is necessary to learn a single policy that can be transferred to other embodiments, eliminating the need to (re)train for each specific robot. In this paper, we introduce RING (Robotic Indoor Navigation Generalist), an embodiment-agnostic policy, trained solely in simulation with diverse randomly initialized embodiments at scale. Specifically, we augment the AI2-THOR simulator with the ability to instantiate robot embodiments with controllable configurations, varying across body size, rotation pivot point, and camera configurations. In the visual object-goal navigation task, RING achieves robust performance on real unseen robot platforms (Stretch RE-1, LoCoBot, Unitree's Go1), achieving an average of 72.1% and 78.9% success rate across 5 embodiments in simulation and 4 robot platforms in the real world. (project website: https://one-ring-policy.allen.ai/)
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
Jun 28, 2024



We present PoliFormer (Policy Transformer), an RGB-only indoor navigation agent trained end-to-end with reinforcement learning at scale that generalizes to the real-world without adaptation despite being trained purely in simulation. PoliFormer uses a foundational vision transformer encoder with a causal transformer decoder enabling long-term memory and reasoning. It is trained for hundreds of millions of interactions across diverse environments, leveraging parallelized, multi-machine rollouts for efficient training with high throughput. PoliFormer is a masterful navigator, producing state-of-the-art results across two distinct embodiments, the LoCoBot and Stretch RE-1 robots, and four navigation benchmarks. It breaks through the plateaus of previous work, achieving an unprecedented 85.5% success rate in object goal navigation on the CHORES-S benchmark, a 28.5% absolute improvement. PoliFormer can also be trivially extended to a variety of downstream applications such as object tracking, multi-object navigation, and open-vocabulary navigation with no finetuning.
CodeNav: Beyond tool-use to using real-world codebases with LLM agents
Jun 18, 2024



We present CodeNav, an LLM agent that navigates and leverages previously unseen code repositories to solve user queries. In contrast to tool-use LLM agents that require ``registration'' of all relevant tools via manual descriptions within the LLM context, CodeNav automatically indexes and searches over code blocks in the target codebase, finds relevant code snippets, imports them, and uses them to iteratively generate a solution with execution feedback. To highlight the core-capabilities of CodeNav, we first showcase three case studies where we use CodeNav for solving complex user queries using three diverse codebases. Next, on three benchmarks, we quantitatively compare the effectiveness of code-use (which only has access to the target codebase) to tool-use (which has privileged access to all tool names and descriptions). Finally, we study the effect of varying kinds of tool and library descriptions on code-use performance, as well as investigate the advantage of the agent seeing source code as opposed to natural descriptions of code. All code will be made open source under a permissive license.
Seeing the Unseen: Visual Common Sense for Semantic Placement
Jan 15, 2024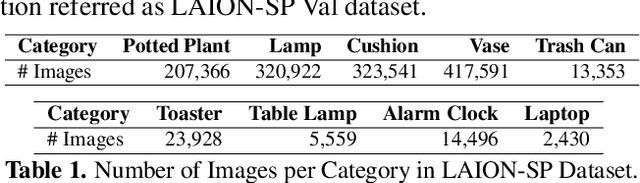
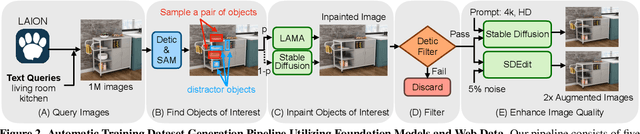
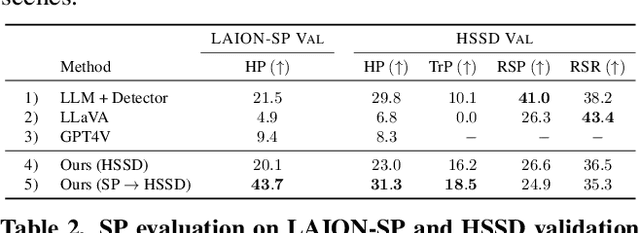

Computer vision tasks typically involve describing what is present in an image (e.g. classification, detection, segmentation, and captioning). We study a visual common sense task that requires understanding what is not present. Specifically, given an image (e.g. of a living room) and name of an object ("cushion"), a vision system is asked to predict semantically-meaningful regions (masks or bounding boxes) in the image where that object could be placed or is likely be placed by humans (e.g. on the sofa). We call this task: Semantic Placement (SP) and believe that such common-sense visual understanding is critical for assitive robots (tidying a house), and AR devices (automatically rendering an object in the user's space). Studying the invisible is hard. Datasets for image description are typically constructed by curating relevant images and asking humans to annotate the contents of the image; neither of those two steps are straightforward for objects not present in the image. We overcome this challenge by operating in the opposite direction: we start with an image of an object in context from web, and then remove that object from the image via inpainting. This automated pipeline converts unstructured web data into a dataset comprising pairs of images with/without the object. Using this, we collect a novel dataset, with ${\sim}1.3$M images across $9$ object categories, and train a SP prediction model called CLIP-UNet. CLIP-UNet outperforms existing VLMs and baselines that combine semantic priors with object detectors on real-world and simulated images. In our user studies, we find that the SP masks predicted by CLIP-UNet are favored $43.7\%$ and $31.3\%$ times when comparing against the $4$ SP baselines on real and simulated images. In addition, we demonstrate leveraging SP mask predictions from CLIP-UNet enables downstream applications like building tidying robots in indoor environments.
Promptable Behaviors: Personalizing Multi-Objective Rewards from Human Preferences
Dec 14, 2023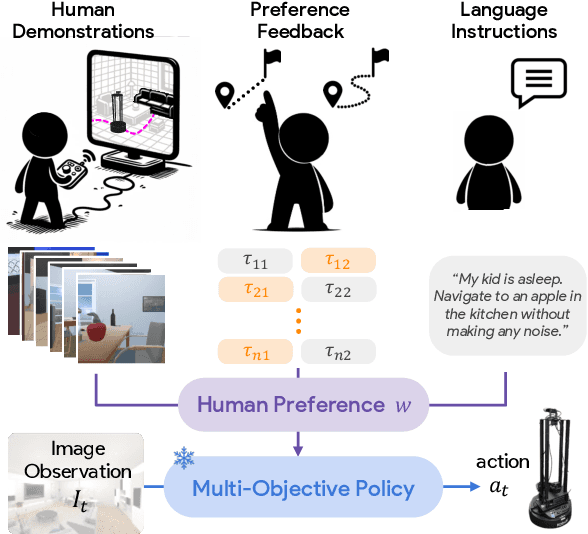
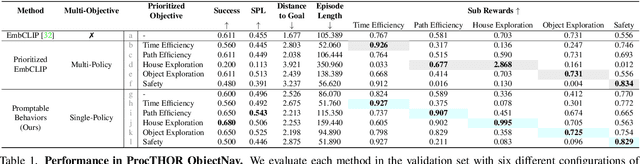
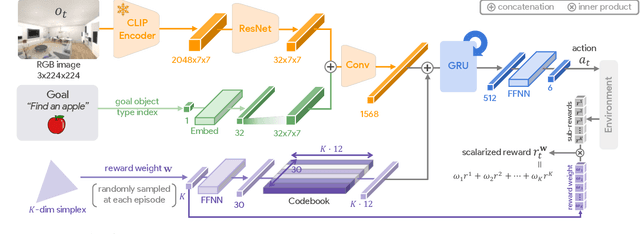
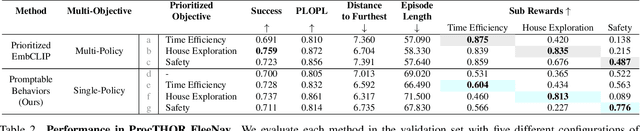
Customizing robotic behaviors to be aligned with diverse human preferences is an underexplored challenge in the field of embodied AI. In this paper, we present Promptable Behaviors, a novel framework that facilitates efficient personalization of robotic agents to diverse human preferences in complex environments. We use multi-objective reinforcement learning to train a single policy adaptable to a broad spectrum of preferences. We introduce three distinct methods to infer human preferences by leveraging different types of interactions: (1) human demonstrations, (2) preference feedback on trajectory comparisons, and (3) language instructions. We evaluate the proposed method in personalized object-goal navigation and flee navigation tasks in ProcTHOR and RoboTHOR, demonstrating the ability to prompt agent behaviors to satisfy human preferences in various scenarios. Project page: https://promptable-behaviors.github.io
Holodeck: Language Guided Generation of 3D Embodied AI Environments
Dec 14, 20233D simulated environments play a critical role in Embodied AI, but their creation requires expertise and extensive manual effort, restricting their diversity and scope. To mitigate this limitation, we present Holodeck, a system that generates 3D environments to match a user-supplied prompt fully automatedly. Holodeck can generate diverse scenes, e.g., arcades, spas, and museums, adjust the designs for styles, and can capture the semantics of complex queries such as "apartment for a researcher with a cat" and "office of a professor who is a fan of Star Wars". Holodeck leverages a large language model (GPT-4) for common sense knowledge about what the scene might look like and uses a large collection of 3D assets from Objaverse to populate the scene with diverse objects. To address the challenge of positioning objects correctly, we prompt GPT-4 to generate spatial relational constraints between objects and then optimize the layout to satisfy those constraints. Our large-scale human evaluation shows that annotators prefer Holodeck over manually designed procedural baselines in residential scenes and that Holodeck can produce high-quality outputs for diverse scene types. We also demonstrate an exciting application of Holodeck in Embodied AI, training agents to navigate in novel scenes like music rooms and daycares without human-constructed data, which is a significant step forward in developing general-purpose embodied agents.
Understanding Representations Pretrained with Auxiliary Losses for Embodied Agent Planning
Dec 06, 2023Pretrained representations from large-scale vision models have boosted the performance of downstream embodied policy learning. We look to understand whether additional self-supervised pretraining on exploration trajectories can build on these general-purpose visual representations to better support embodied planning in realistic environments. We evaluated four common auxiliary losses in embodied AI, two hindsight-based losses, and a standard imitation learning loss, by pretraining the agent's visual compression module and state belief representations with each objective and using CLIP as a representative visual backbone. The learned representations are then frozen for downstream multi-step evaluation on two goal-directed tasks. Surprisingly, we find that imitation learning on these exploration trajectories out-performs all other auxiliary losses even despite the exploration trajectories being dissimilar from the downstream tasks. This suggests that imitation of exploration may be ''all you need'' for building powerful planning representations. Additionally, we find that popular auxiliary losses can benefit from simple modifications to improve their support for downstream planning ability.