 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
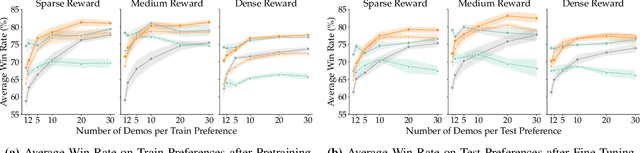
Mar 02, 2026General-purpose robot reward models are typically trained to predict absolute task progress from expert demonstrations, providing only local, frame-level supervision. While effective for expert demonstrations, this paradigm scales poorly to large-scale robotics datasets where failed and suboptimal trajectories are abundant and assigning dense progress labels is ambiguous. We introduce Robometer, a scalable reward modeling framework that combines intra-trajectory progress supervision with inter-trajectory preference supervision. Robometer is trained with a dual objective: a frame-level progress loss that anchors reward magnitude on expert data, and a trajectory-comparison preference loss that imposes global ordering constraints across trajectories of the same task, enabling effective learning from both real and augmented failed trajectories. To support this formulation at scale, we curate RBM-1M, a reward-learning dataset comprising over one million trajectories spanning diverse robot embodiments and tasks, including substantial suboptimal and failure data. Across benchmarks and real-world evaluations, Robometer learns more generalizable reward functions than prior methods and improves robot learning performance across a diverse set of downstream applications. Code, model weights, and videos at https://robometer.github.io/.
Masked IRL: LLM-Guided Reward Disambiguation from Demonstrations and Language
Nov 18, 2025


Robots can adapt to user preferences by learning reward functions from demonstrations, but with limited data, reward models often overfit to spurious correlations and fail to generalize. This happens because demonstrations show robots how to do a task but not what matters for that task, causing the model to focus on irrelevant state details. Natural language can more directly specify what the robot should focus on, and, in principle, disambiguate between many reward functions consistent with the demonstrations. However, existing language-conditioned reward learning methods typically treat instructions as simple conditioning signals, without fully exploiting their potential to resolve ambiguity. Moreover, real instructions are often ambiguous themselves, so naive conditioning is unreliable. Our key insight is that these two input types carry complementary information: demonstrations show how to act, while language specifies what is important. We propose Masked Inverse Reinforcement Learning (Masked IRL), a framework that uses large language models (LLMs) to combine the strengths of both input types. Masked IRL infers state-relevance masks from language instructions and enforces invariance to irrelevant state components. When instructions are ambiguous, it uses LLM reasoning to clarify them in the context of the demonstrations. In simulation and on a real robot, Masked IRL outperforms prior language-conditioned IRL methods by up to 15% while using up to 4.7 times less data, demonstrating improved sample-efficiency, generalization, and robustness to ambiguous language. Project page: https://MIT-CLEAR-Lab.github.io/Masked-IRL and Code: https://github.com/MIT-CLEAR-Lab/Masked-IRL
MotIF: Motion Instruction Fine-tuning
Sep 16, 2024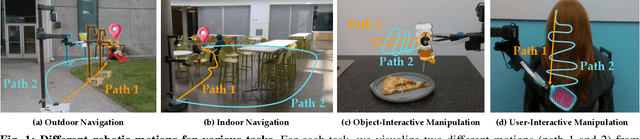

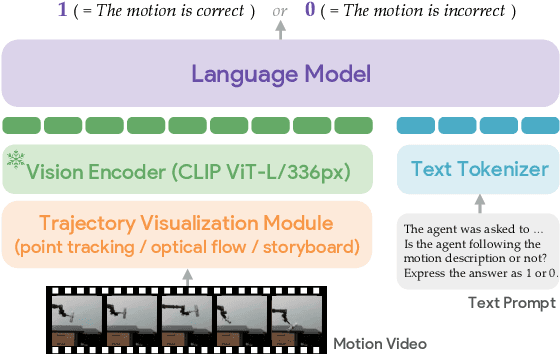

While success in many robotics tasks can be determined by only observing the final state and how it differs from the initial state - e.g., if an apple is picked up - many tasks require observing the full motion of the robot to correctly determine success. For example, brushing hair requires repeated strokes that correspond to the contours and type of hair. Prior works often use off-the-shelf vision-language models (VLMs) as success detectors; however, when success depends on the full trajectory, VLMs struggle to make correct judgments for two reasons. First, modern VLMs are trained only on single frames, and cannot capture changes over a full trajectory. Second, even if we provide state-of-the-art VLMs with an aggregate input of multiple frames, they still fail to detect success due to a lack of robot data. Our key idea is to fine-tune VLMs using abstract representations that are able to capture trajectory-level information such as the path the robot takes by overlaying keypoint trajectories on the final image. We propose motion instruction fine-tuning (MotIF), a method that fine-tunes VLMs using the aforementioned abstract representations to semantically ground the robot's behavior in the environment. To benchmark and fine-tune VLMs for robotic motion understanding, we introduce the MotIF-1K dataset containing 653 human and 369 robot demonstrations across 13 task categories. MotIF assesses the success of robot motion given the image observation of the trajectory, task instruction, and motion description. Our model significantly outperforms state-of-the-art VLMs by at least twice in precision and 56.1% in recall, generalizing across unseen motions, tasks, and environments. Finally, we demonstrate practical applications of MotIF in refining and terminating robot planning, and ranking trajectories on how they align with task and motion descriptions. Project page: https://motif-1k.github.io
Promptable Behaviors: Personalizing Multi-Objective Rewards from Human Preferences
Dec 14, 2023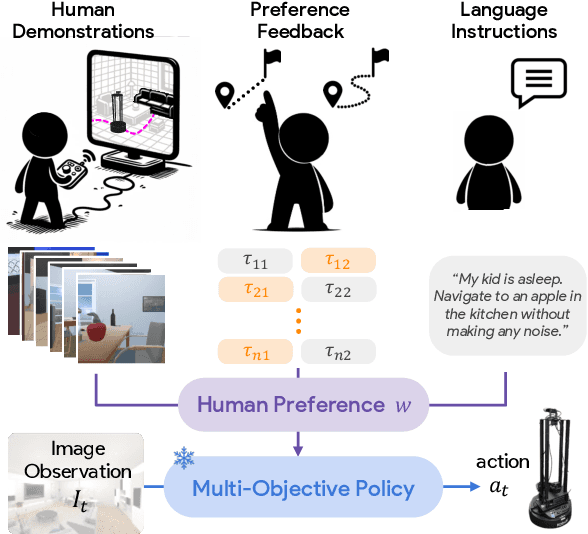
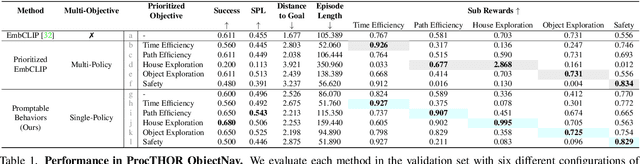
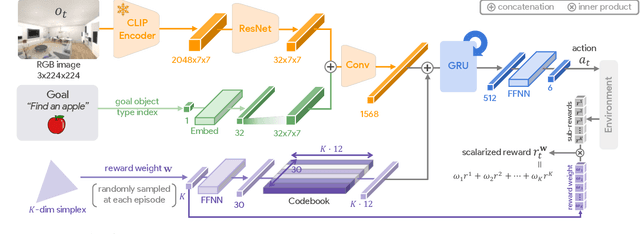
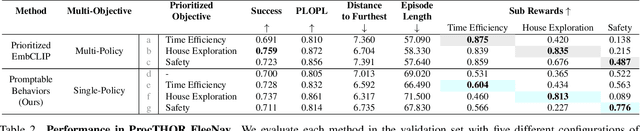
Customizing robotic behaviors to be aligned with diverse human preferences is an underexplored challenge in the field of embodied AI. In this paper, we present Promptable Behaviors, a novel framework that facilitates efficient personalization of robotic agents to diverse human preferences in complex environments. We use multi-objective reinforcement learning to train a single policy adaptable to a broad spectrum of preferences. We introduce three distinct methods to infer human preferences by leveraging different types of interactions: (1) human demonstrations, (2) preference feedback on trajectory comparisons, and (3) language instructions. We evaluate the proposed method in personalized object-goal navigation and flee navigation tasks in ProcTHOR and RoboTHOR, demonstrating the ability to prompt agent behaviors to satisfy human preferences in various scenarios. Project page: https://promptable-behaviors.github.io
Meta-Explore: Exploratory Hierarchical Vision-and-Language Navigation Using Scene Object Spectrum Grounding
Mar 07, 2023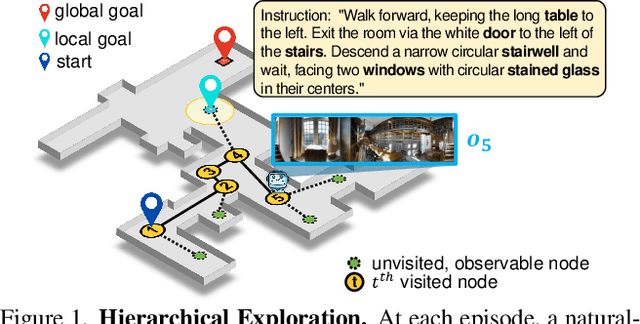
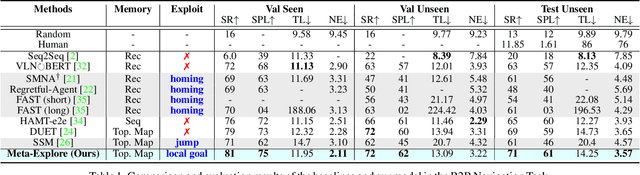
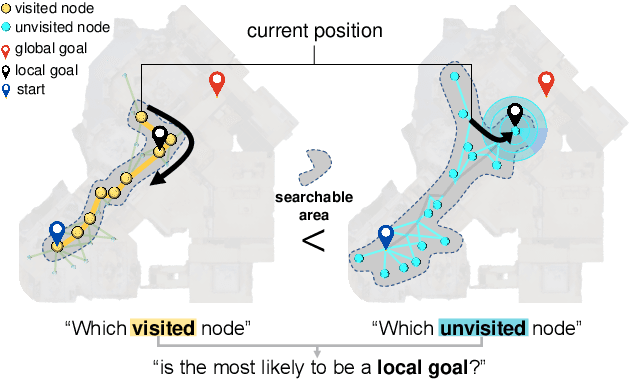
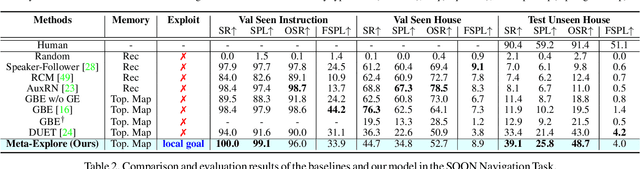
The main challenge in vision-and-language navigation (VLN) is how to understand natural-language instructions in an unseen environment. The main limitation of conventional VLN algorithms is that if an action is mistaken, the agent fails to follow the instructions or explores unnecessary regions, leading the agent to an irrecoverable path. To tackle this problem, we propose Meta-Explore, a hierarchical navigation method deploying an exploitation policy to correct misled recent actions. We show that an exploitation policy, which moves the agent toward a well-chosen local goal among unvisited but observable states, outperforms a method which moves the agent to a previously visited state. We also highlight the demand for imagining regretful explorations with semantically meaningful clues. The key to our approach is understanding the object placements around the agent in spectral-domain. Specifically, we present a novel visual representation, called scene object spectrum (SOS), which performs category-wise 2D Fourier transform of detected objects. Combining exploitation policy and SOS features, the agent can correct its path by choosing a promising local goal. We evaluate our method in three VLN benchmarks: R2R, SOON, and REVERIE. Meta-Explore outperforms other baselines and shows significant generalization performance. In addition, local goal search using the proposed spectral-domain SOS features significantly improves the success rate by 17.1% and SPL by 20.6% for the SOON benchmark.