 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-Aware Quantized Imitation Learning for Efficient Robotic Control
May 21, 2025



Deep neural network (DNN)-based policy models, such as vision-language-action (VLA) models, excel at automating complex decision-making from multi-modal inputs. However, scaling these models greatly increases computational overhead, complicating deployment in resource-constrained settings like robot manipulation and autonomous driving. To address this, we propose Saliency-Aware Quantized Imitation Learning (SQIL), which combines quantization-aware training with a selective loss-weighting strategy for mission-critical states. By identifying these states via saliency scores and emphasizing them in the training loss, SQIL preserves decision fidelity under low-bit precision. We validate SQIL's generalization capability across extensive simulation benchmarks with environment variations, real-world tasks, and cross-domain tasks (self-driving, physics simulation), consistently recovering full-precision performance. Notably, a 4-bit weight-quantized VLA model for robotic manipulation achieves up to 2.5x speedup and 2.5x energy savings on an edge GPU with minimal accuracy loss. These results underline SQIL's potential for efficiently deploying large IL-based policy models on resource-limited devices.
Quantization-Aware Imitation-Learning for Resource-Efficient Robotic Control
Dec 02, 2024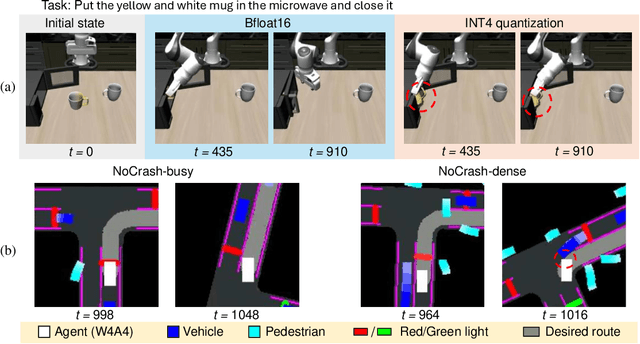
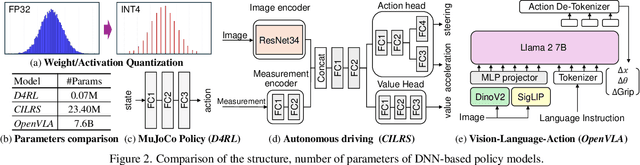
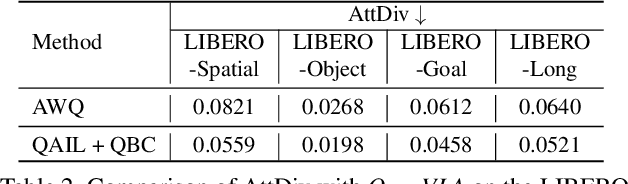
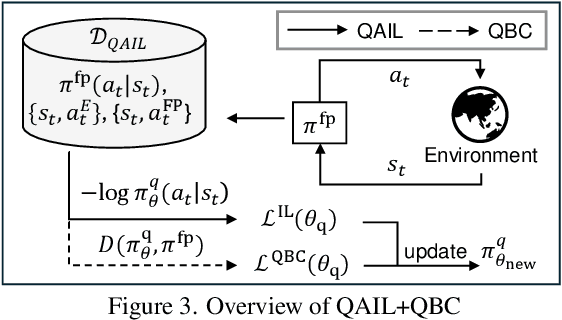
Deep neural network (DNN)-based policy models like vision-language-action (VLA) models are transformative in automating complex decision-making across applications by interpreting multi-modal data. However, scaling these models greatly increases computational costs, which presents challenges in fields like robot manipulation and autonomous driving that require quick, accurate responses. To address the need for deployment on resource-limited hardware, we propose a new quantization framework for IL-based policy models that fine-tunes parameters to enhance robustness against low-bit precision errors during training, thereby maintaining efficiency and reliability under constrained conditions. Our evaluations with representative robot manipulation for 4-bit weight-quantization on a real edge GPU demonstrate that our framework achieves up to 2.5x speedup and 2.5x energy savings while preserving accuracy. For 4-bit weight and activation quantized self-driving models, the framework achieves up to 3.7x speedup and 3.1x energy saving on a low-end GPU. These results highlight the practical potential of deploying IL-based policy models on resource-constrained devices.
Meta-Explore: Exploratory Hierarchical Vision-and-Language Navigation Using Scene Object Spectrum Grounding
Mar 07, 2023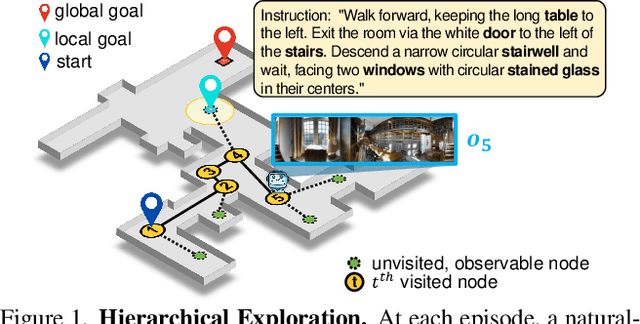
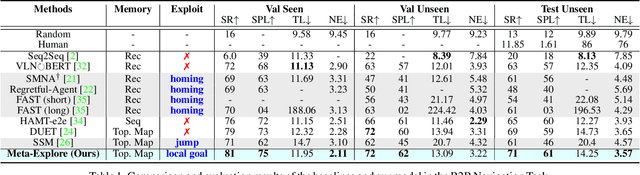
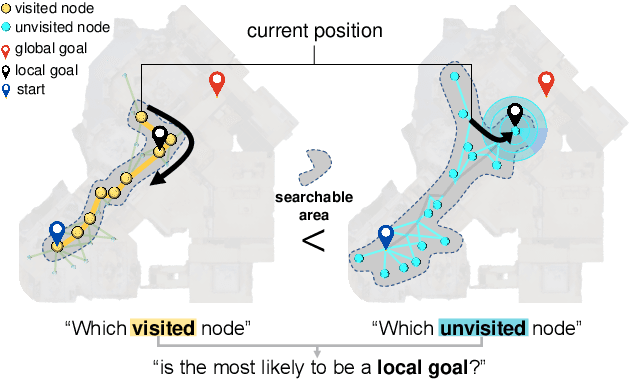
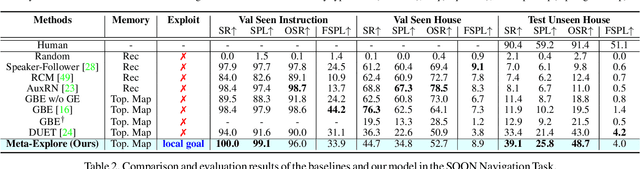
The main challenge in vision-and-language navigation (VLN) is how to understand natural-language instructions in an unseen environment. The main limitation of conventional VLN algorithms is that if an action is mistaken, the agent fails to follow the instructions or explores unnecessary regions, leading the agent to an irrecoverable path. To tackle this problem, we propose Meta-Explore, a hierarchical navigation method deploying an exploitation policy to correct misled recent actions. We show that an exploitation policy, which moves the agent toward a well-chosen local goal among unvisited but observable states, outperforms a method which moves the agent to a previously visited state. We also highlight the demand for imagining regretful explorations with semantically meaningful clues. The key to our approach is understanding the object placements around the agent in spectral-domain. Specifically, we present a novel visual representation, called scene object spectrum (SOS), which performs category-wise 2D Fourier transform of detected objects. Combining exploitation policy and SOS features, the agent can correct its path by choosing a promising local goal. We evaluate our method in three VLN benchmarks: R2R, SOON, and REVERIE. Meta-Explore outperforms other baselines and shows significant generalization performance. In addition, local goal search using the proposed spectral-domain SOS features significantly improves the success rate by 17.1% and SPL by 20.6% for the SOON benchmark.
Planning with State Abstractions for Non-Markovian Task Specifications
May 28, 2019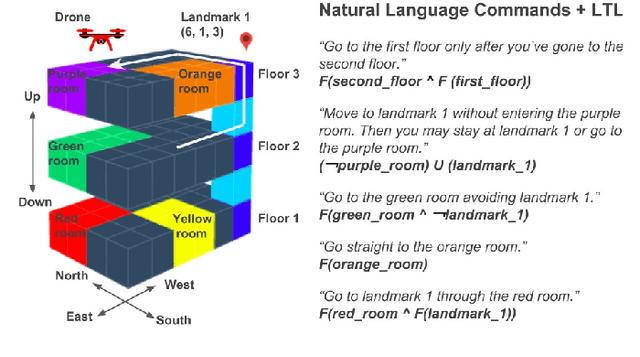
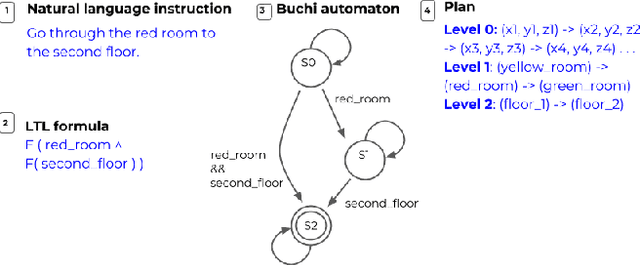
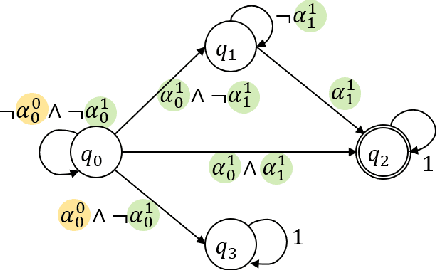
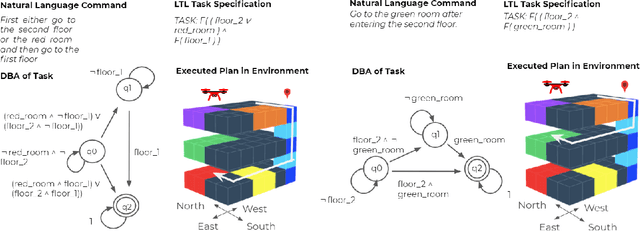
Often times, we specify tasks for a robot using temporal language that can also span different levels of abstraction. The example command ``go to the kitchen before going to the second floor'' contains spatial abstraction, given that ``floor'' consists of individual rooms that can also be referred to in isolation ("kitchen", for example). There is also a temporal ordering of events, defined by the word "before". Previous works have used Linear Temporal Logic (LTL) to interpret temporal language (such as "before"), and Abstract Markov Decision Processes (AMDPs) to interpret hierarchical abstractions (such as "kitchen" and "second floor"), separately. To handle both types of commands at once, we introduce the Abstract Product Markov Decision Process (AP-MDP), a novel approach capable of representing non-Markovian reward functions at different levels of abstractions. The AP-MDP framework translates LTL into its corresponding automata, creates a product Markov Decision Process (MDP) of the LTL specification and the environment MDP, and decomposes the problem into subproblems to enable efficient planning with abstractions. AP-MDP performs faster than a non-hierarchical method of solving LTL problems in over 95% of tasks, and this number only increases as the size of the environment domain increases. We also present a neural sequence-to-sequence model trained to translate language commands into LTL expression, and a new corpus of non-Markovian language commands spanning different levels of abstraction. We test our framework with the collected language commands on a drone, demonstrating that our approach enables a robot to efficiently solve temporal commands at different levels of abstraction.