 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-Aware Quantized Imitation Learning for Efficient Robotic Control
May 21, 2025Deep neural network (DNN)-based policy models, such as vision-language-action (VLA) models, excel at automating complex decision-making from multi-modal inputs. However, scaling these models greatly increases computational overhead, complicating deployment in resource-constrained settings like robot manipulation and autonomous driving. To address this, we propose Saliency-Aware Quantized Imitation Learning (SQIL), which combines quantization-aware training with a selective loss-weighting strategy for mission-critical states. By identifying these states via saliency scores and emphasizing them in the training loss, SQIL preserves decision fidelity under low-bit precision. We validate SQIL's generalization capability across extensive simulation benchmarks with environment variations, real-world tasks, and cross-domain tasks (self-driving, physics simulation), consistently recovering full-precision performance. Notably, a 4-bit weight-quantized VLA model for robotic manipulation achieves up to 2.5x speedup and 2.5x energy savings on an edge GPU with minimal accuracy loss. These results underline SQIL's potential for efficiently deploying large IL-based policy models on resource-limited devices.
Quantization-Aware Imitation-Learning for Resource-Efficient Robotic Control
Dec 02, 2024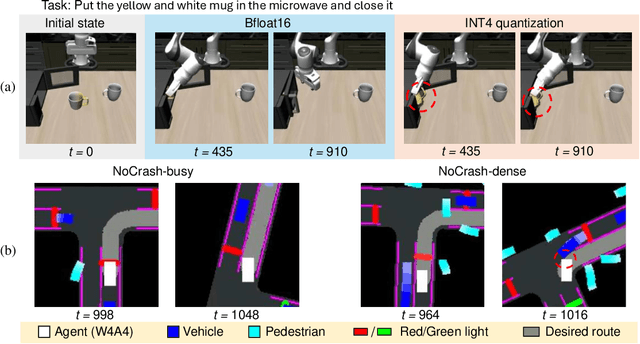
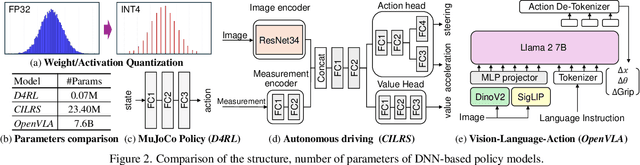
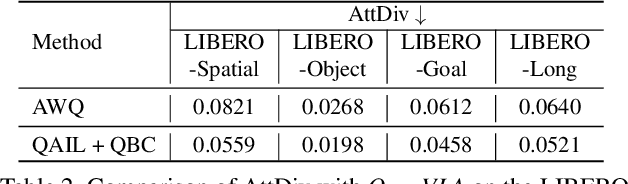
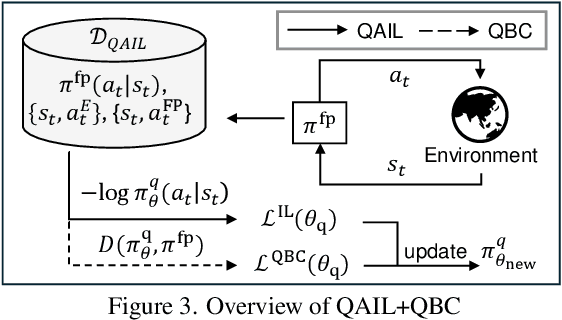
Deep neural network (DNN)-based policy models like vision-language-action (VLA) models are transformative in automating complex decision-making across applications by interpreting multi-modal data. However, scaling these models greatly increases computational costs, which presents challenges in fields like robot manipulation and autonomous driving that require quick, accurate responses. To address the need for deployment on resource-limited hardware, we propose a new quantization framework for IL-based policy models that fine-tunes parameters to enhance robustness against low-bit precision errors during training, thereby maintaining efficiency and reliability under constrained conditions. Our evaluations with representative robot manipulation for 4-bit weight-quantization on a real edge GPU demonstrate that our framework achieves up to 2.5x speedup and 2.5x energy savings while preserving accuracy. For 4-bit weight and activation quantized self-driving models, the framework achieves up to 3.7x speedup and 3.1x energy saving on a low-end GPU. These results highlight the practical potential of deploying IL-based policy models on resource-constrained devices.
Enhanced Prototypical Learning for Unsupervised Domain Adaptation in LiDAR Semantic Segmentation
May 23, 2022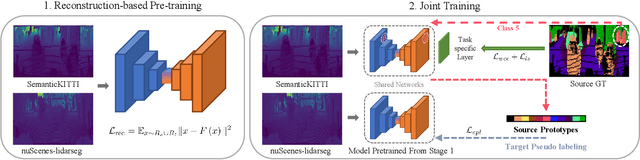



Despite its importance, unsupervised domain adaptation (UDA) on LiDAR semantic segmentation is a task that has not received much attention from the research community. Only recently, a completion-based 3D method has been proposed to tackle the problem and formally set up the adaptive scenarios. However, the proposed pipeline is complex, voxel-based and requires multi-stage inference, which inhibits it for real-time inference. We propose a range image-based, effective and efficient method for solving UDA on LiDAR segmentation. The method exploits class prototypes from the source domain to pseudo label target domain pixels, which is a research direction showing good performance in UDA for natural image semantic segmentation. Applying such approaches to LiDAR scans has not been considered because of the severe domain shift and lack of pre-trained feature extractor that is unavailable in the LiDAR segmentation setup. However, we show that proper strategies, including reconstruction-based pre-training, enhanced prototypes, and selective pseudo labeling based on distance to prototypes, is sufficient enough to enable the use of prototypical approaches. We evaluate the performance of our method on the recently proposed LiDAR segmentation UDA scenarios. Our method achieves remarkable performance among contemporary methods.
Projection-based Point Convolution for Efficient Point Cloud Segmentation
Feb 04, 2022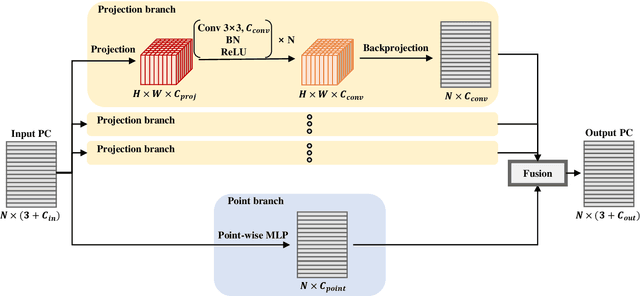
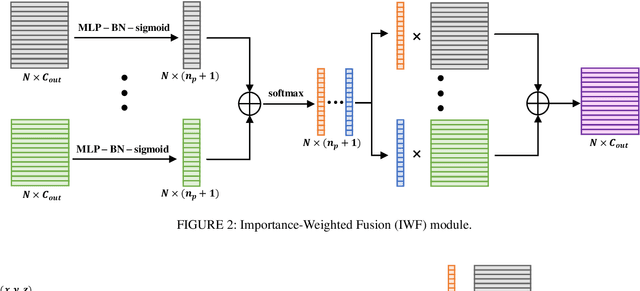
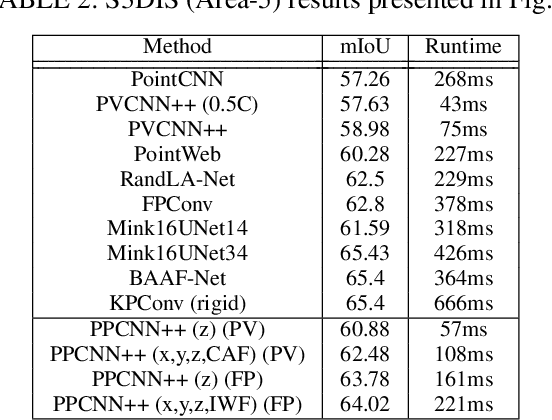
Understanding point cloud has recently gained huge interests following the development of 3D scanning devices and the accumulation of large-scale 3D data. Most point cloud processing algorithms can be classified as either point-based or voxel-based methods, both of which have severe limitations in processing time or memory, or both. To overcome these limitations, we propose Projection-based Point Convolution (PPConv), a point convolutional module that uses 2D convolutions and multi-layer perceptrons (MLPs) as its components. In PPConv, point features are processed through two branches: point branch and projection branch. Point branch consists of MLPs, while projection branch transforms point features into a 2D feature map and then apply 2D convolutions. As PPConv does not use point-based or voxel-based convolutions, it has advantages in fast point cloud processing. When combined with a learnable projection and effective feature fusion strategy, PPConv achieves superior efficiency compared to state-of-the-art methods, even with a simple architecture based on PointNet++. We demonstrate the efficiency of PPConv in terms of the trade-off between inference time and segmentation performance. The experimental results on S3DIS and ShapeNetPart show that PPConv is the most efficient method among the compared ones. The code is available at github.com/pahn04/PPConv.
Progressive Seed Generation Auto-encoder for Unsupervised Point Cloud Learning
Dec 09, 2021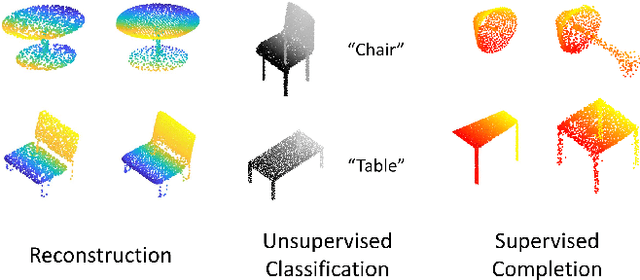
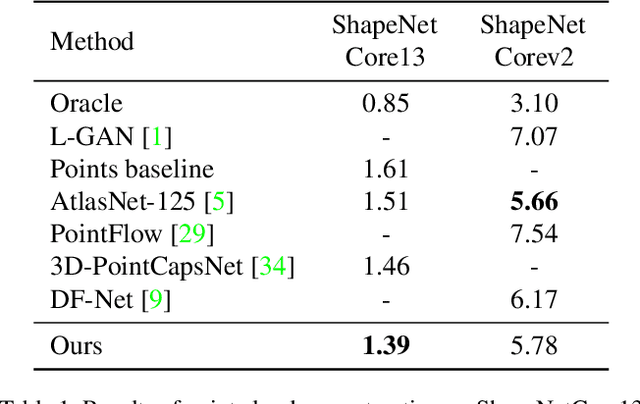
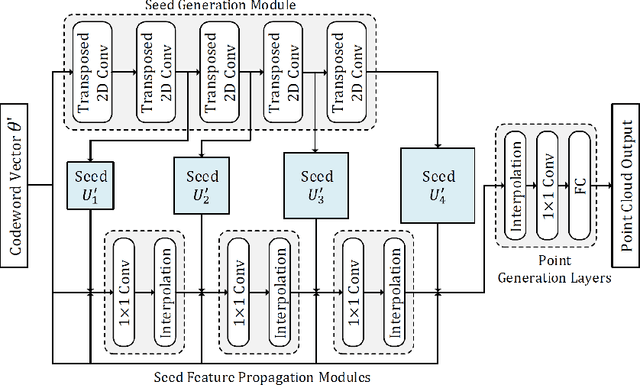
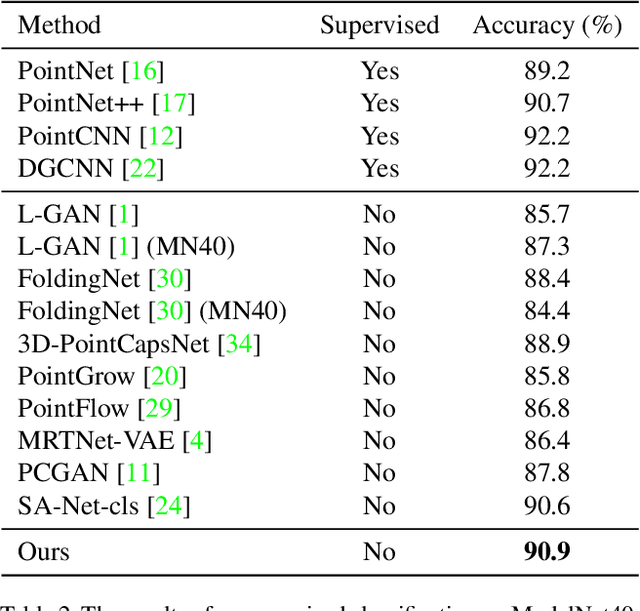
With the development of 3D scanning technologies, 3D vision tasks have become a popular research area. Owing to the large amount of data acquired by sensors, unsupervised learning is essential for understanding and utilizing point clouds without an expensive annotation process. In this paper, we propose a novel framework and an effective auto-encoder architecture named "PSG-Net" for reconstruction-based learning of point clouds. Unlike existing studies that used fixed or random 2D points, our framework generates input-dependent point-wise features for the latent point set. PSG-Net uses the encoded input to produce point-wise features through the seed generation module and extracts richer features in multiple stages with gradually increasing resolution by applying the seed feature propagation module progressively. We prove the effectiveness of PSG-Net experimentally; PSG-Net shows state-of-the-art performances in point cloud reconstruction and unsupervised classification, and achieves comparable performance to counterpart methods in supervised completion.