 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Monocular Depth Estimation via Token-Sharing Transformer
Jun 09, 2023Depth estimation is an important task in various robotics systems and applications. In mobile robotics systems, monocular depth estimation is desirable since a single RGB camera can be deployable at a low cost and compact size. Due to its significant and growing needs, many lightweight monocular depth estimation networks have been proposed for mobile robotics systems. While most lightweight monocular depth estimation methods have been developed using convolution neural networks, the Transformer has been gradually utilized in monocular depth estimation recently. However, massive parameters and large computational costs in the Transformer disturb the deployment to embedded devices. In this paper, we present a Token-Sharing Transformer (TST), an architecture using the Transformer for monocular depth estimation, optimized especially in embedded devices. The proposed TST utilizes global token sharing, which enables the model to obtain an accurate depth prediction with high throughput in embedded devices. Experimental results show that TST outperforms the existing lightweight monocular depth estimation methods. On the NYU Depth v2 dataset, TST can deliver depth maps up to 63.4 FPS in NVIDIA Jetson nano and 142.6 FPS in NVIDIA Jetson TX2, with lower errors than the existing methods. Furthermore, TST achieves real-time depth estimation of high-resolution images on Jetson TX2 with competitive results.
Enhanced Prototypical Learning for Unsupervised Domain Adaptation in LiDAR Semantic Segmentation
May 23, 2022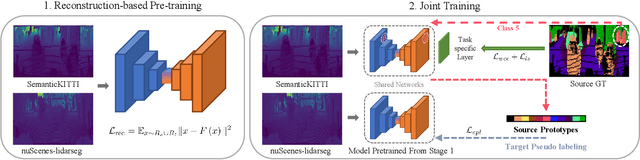



Despite its importance, unsupervised domain adaptation (UDA) on LiDAR semantic segmentation is a task that has not received much attention from the research community. Only recently, a completion-based 3D method has been proposed to tackle the problem and formally set up the adaptive scenarios. However, the proposed pipeline is complex, voxel-based and requires multi-stage inference, which inhibits it for real-time inference. We propose a range image-based, effective and efficient method for solving UDA on LiDAR segmentation. The method exploits class prototypes from the source domain to pseudo label target domain pixels, which is a research direction showing good performance in UDA for natural image semantic segmentation. Applying such approaches to LiDAR scans has not been considered because of the severe domain shift and lack of pre-trained feature extractor that is unavailable in the LiDAR segmentation setup. However, we show that proper strategies, including reconstruction-based pre-training, enhanced prototypes, and selective pseudo labeling based on distance to prototypes, is sufficient enough to enable the use of prototypical approaches. We evaluate the performance of our method on the recently proposed LiDAR segmentation UDA scenarios. Our method achieves remarkable performance among contemporary methods.
Projection-based Point Convolution for Efficient Point Cloud Segmentation
Feb 04, 2022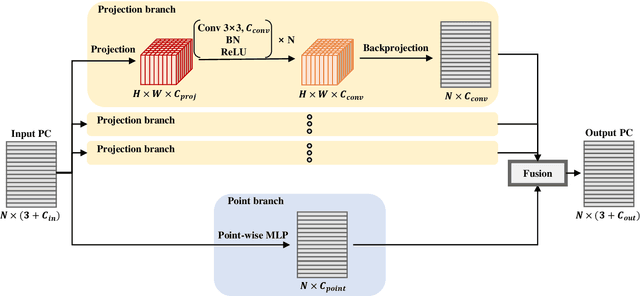
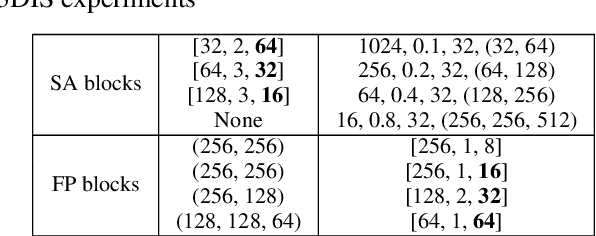
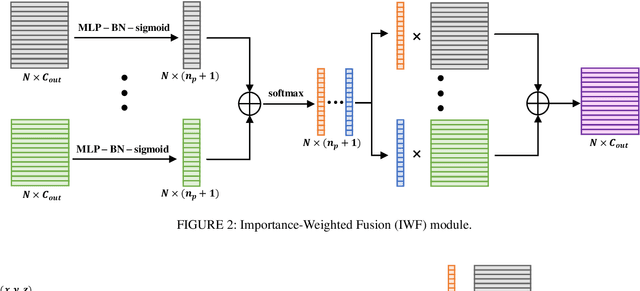
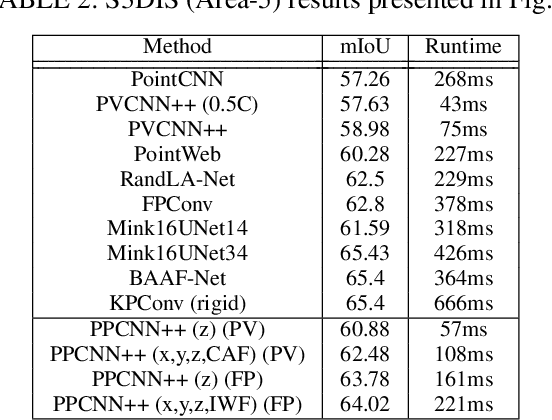
Understanding point cloud has recently gained huge interests following the development of 3D scanning devices and the accumulation of large-scale 3D data. Most point cloud processing algorithms can be classified as either point-based or voxel-based methods, both of which have severe limitations in processing time or memory, or both. To overcome these limitations, we propose Projection-based Point Convolution (PPConv), a point convolutional module that uses 2D convolutions and multi-layer perceptrons (MLPs) as its components. In PPConv, point features are processed through two branches: point branch and projection branch. Point branch consists of MLPs, while projection branch transforms point features into a 2D feature map and then apply 2D convolutions. As PPConv does not use point-based or voxel-based convolutions, it has advantages in fast point cloud processing. When combined with a learnable projection and effective feature fusion strategy, PPConv achieves superior efficiency compared to state-of-the-art methods, even with a simple architecture based on PointNet++. We demonstrate the efficiency of PPConv in terms of the trade-off between inference time and segmentation performance. The experimental results on S3DIS and ShapeNetPart show that PPConv is the most efficient method among the compared ones. The code is available at github.com/pahn04/PPConv.
PBP-Net: Point Projection and Back-Projection Network for 3D Point Cloud Segmentation
Nov 02, 2020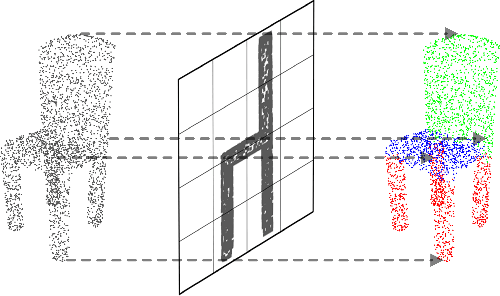
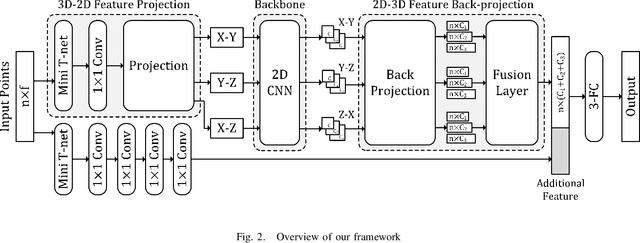
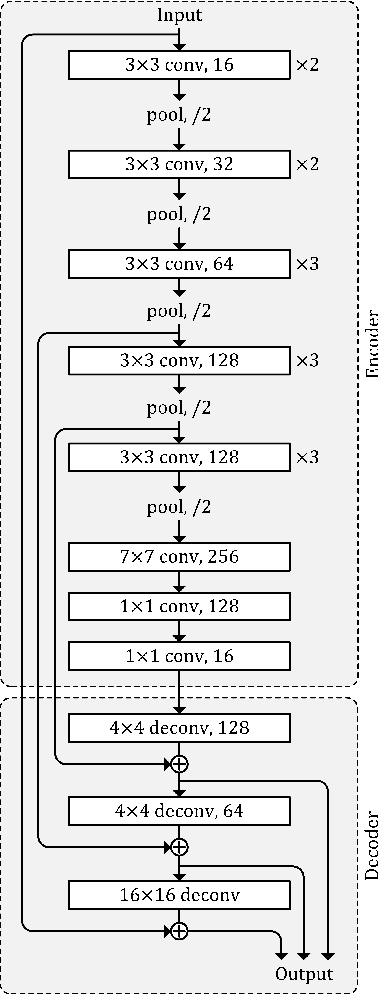

Following considerable development in 3D scanning technologies, many studies have recently been proposed with various approaches for 3D vision tasks, including some methods that utilize 2D convolutional neural networks (CNNs). However, even though 2D CNNs have achieved high performance in many 2D vision tasks, existing works have not effectively applied them onto 3D vision tasks. In particular, segmentation has not been well studied because of the difficulty of dense prediction for each point, which requires rich feature representation. In this paper, we propose a simple and efficient architecture named point projection and back-projection network (PBP-Net), which leverages 2D CNNs for the 3D point cloud segmentation. 3 modules are introduced, each of which projects 3D point cloud onto 2D planes, extracts features using a 2D CNN backbone, and back-projects features onto the original 3D point cloud. To demonstrate effective 3D feature extraction using 2D CNN, we perform various experiments including comparison to recent methods. We analyze the proposed modules through ablation studies and perform experiments on object part segmentation (ShapeNet-Part dataset) and indoor scene semantic segmentation (S3DIS dataset). The experimental results show that proposed PBP-Net achieves comparable performance to existing state-of-the-art methods.