 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo-Matching Knowledge Distilled Monocular Depth Estimation Filtered by Multiple Disparity Consistency
Jan 23, 2024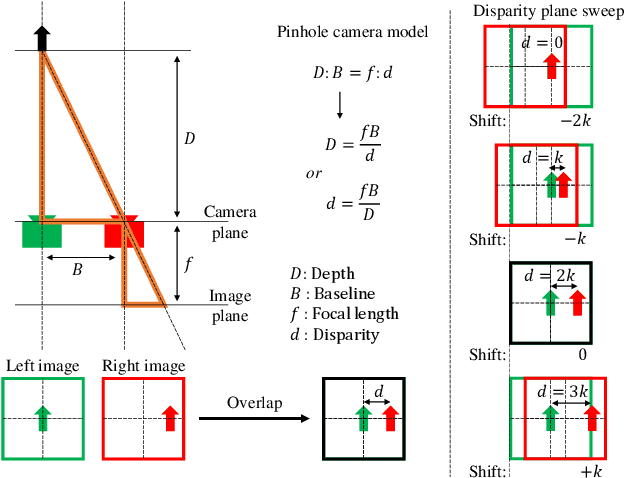
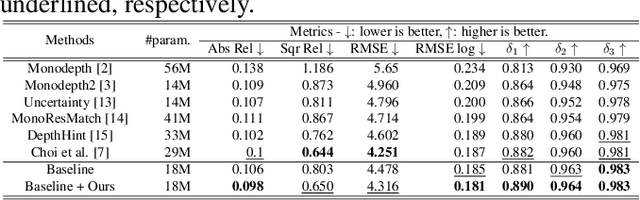
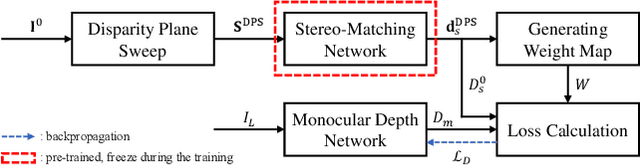
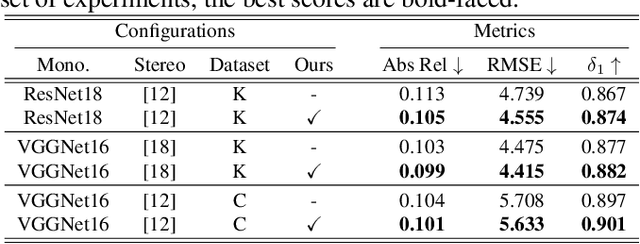
In stereo-matching knowledge distillation methods of the self-supervised monocular depth estimation, the stereo-matching network's knowledge is distilled into a monocular depth network through pseudo-depth maps. In these methods, the learning-based stereo-confidence network is generally utilized to identify errors in the pseudo-depth maps to prevent transferring the errors. However, the learning-based stereo-confidence networks should be trained with ground truth (GT), which is not feasible in a self-supervised setting. In this paper, we propose a method to identify and filter errors in the pseudo-depth map using multiple disparity maps by checking their consistency without the need for GT and a training process. Experimental results show that the proposed method outperforms the previous methods and works well on various configurations by filtering out erroneous areas where the stereo-matching is vulnerable, especially such as textureless regions, occlusion boundaries, and reflective surfaces.
Modeling Stereo-Confidence Out of the End-to-End Stereo-Matching Network via Disparity Plane Sweep
Jan 23, 2024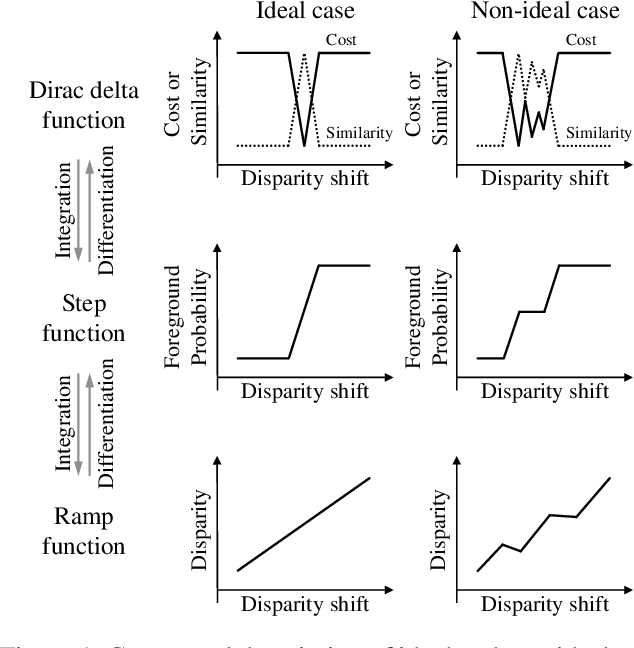
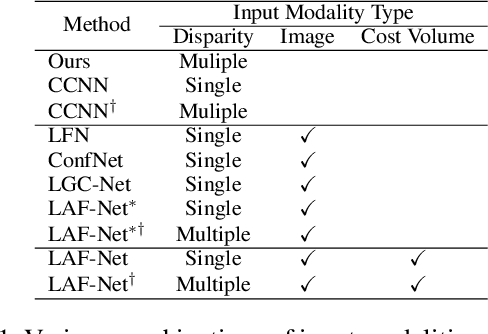
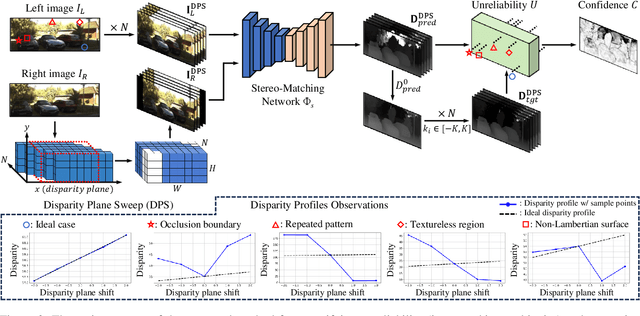
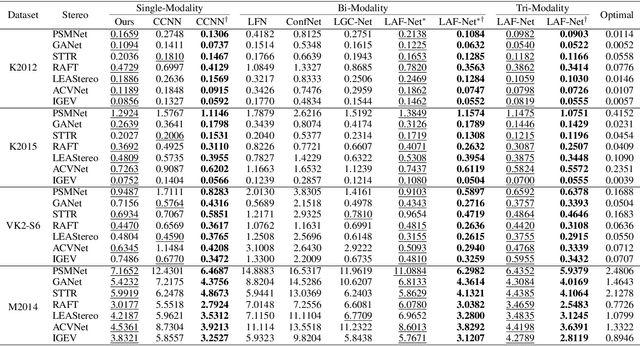
We propose a novel stereo-confidence that can be measured externally to various stereo-matching networks, offering an alternative input modality choice of the cost volume for learning-based approaches, especially in safety-critical systems. Grounded in the foundational concepts of disparity definition and the disparity plane sweep, the proposed stereo-confidence method is built upon the idea that any shift in a stereo-image pair should be updated in a corresponding amount shift in the disparity map. Based on this idea, the proposed stereo-confidence method can be summarized in three folds. 1) Using the disparity plane sweep, multiple disparity maps can be obtained and treated as a 3-D volume (predicted disparity volume), like the cost volume is constructed. 2) One of these disparity maps serves as an anchor, allowing us to define a desirable (or ideal) disparity profile at every spatial point. 3) By comparing the desirable and predicted disparity profiles, we can quantify the level of matching ambiguity between left and right images for confidence measurement. Extensive experimental results using various stereo-matching networks and datasets demonstrate that the proposed stereo-confidence method not only shows competitive performance on its own but also consistent performance improvements when it is used as an input modality for learning-based stereo-confidence methods.
Few-Shot Anomaly Detection with Adversarial Loss for Robust Feature Representations
Dec 04, 2023Anomaly detection is a critical and challenging task that aims to identify data points deviating from normal patterns and distributions within a dataset. Various methods have been proposed using a one-class-one-model approach, but these techniques often face practical problems such as memory inefficiency and the requirement of sufficient data for training. In particular, few-shot anomaly detection presents significant challenges in industrial applications, where limited samples are available before mass production. In this paper, we propose a few-shot anomaly detection method that integrates adversarial training loss to obtain more robust and generalized feature representations. We utilize the adversarial loss previously employed in domain adaptation to align feature distributions between source and target domains, to enhance feature robustness and generalization in few-shot anomaly detection tasks. We hypothesize that adversarial loss is effective when applied to features that should have similar characteristics, such as those from the same layer in a Siamese network's parallel branches or input-output pairs of reconstruction-based methods. Experimental results demonstrate that the proposed method generally achieves better performance when utilizing the adversarial loss.
SimCol3D -- 3D Reconstruction during Colonoscopy Challenge
Jul 20, 2023Colorectal cancer is one of the most common cancers in the world. While colonoscopy is an effective screening technique, navigating an endoscope through the colon to detect polyps is challenging. A 3D map of the observed surfaces could enhance the identification of unscreened colon tissue and serve as a training platform. However, reconstructing the colon from video footage remains unsolved due to numerous factors such as self-occlusion, reflective surfaces, lack of texture, and tissue deformation that limit feature-based methods. Learning-based approaches hold promise as robust alternatives, but necessitate extensive datasets. By establishing a benchmark, the 2022 EndoVis sub-challenge SimCol3D aimed to facilitate data-driven depth and pose prediction during colonoscopy. The challenge was hosted as part of MICCAI 2022 in Singapore. Six teams from around the world and representatives from academia and industry participated in the three sub-challenges: synthetic depth prediction, synthetic pose prediction, and real pose prediction. This paper describes the challenge, the submitted methods, and their results. We show that depth prediction in virtual colonoscopy is robustly solvable, while pose estimation remains an open research question.
Lightweight Monocular Depth Estimation via Token-Sharing Transformer
Jun 09, 2023Depth estimation is an important task in various robotics systems and applications. In mobile robotics systems, monocular depth estimation is desirable since a single RGB camera can be deployable at a low cost and compact size. Due to its significant and growing needs, many lightweight monocular depth estimation networks have been proposed for mobile robotics systems. While most lightweight monocular depth estimation methods have been developed using convolution neural networks, the Transformer has been gradually utilized in monocular depth estimation recently. However, massive parameters and large computational costs in the Transformer disturb the deployment to embedded devices. In this paper, we present a Token-Sharing Transformer (TST), an architecture using the Transformer for monocular depth estimation, optimized especially in embedded devices. The proposed TST utilizes global token sharing, which enables the model to obtain an accurate depth prediction with high throughput in embedded devices. Experimental results show that TST outperforms the existing lightweight monocular depth estimation methods. On the NYU Depth v2 dataset, TST can deliver depth maps up to 63.4 FPS in NVIDIA Jetson nano and 142.6 FPS in NVIDIA Jetson TX2, with lower errors than the existing methods. Furthermore, TST achieves real-time depth estimation of high-resolution images on Jetson TX2 with competitive results.
Fix the Noise: Disentangling Source Feature for Controllable Domain Translation
Mar 21, 2023Recent studies show strong generative performance in domain translation especially by using transfer learning techniques on the unconditional generator. However, the control between different domain features using a single model is still challenging. Existing methods often require additional models, which is computationally demanding and leads to unsatisfactory visual quality. In addition, they have restricted control steps, which prevents a smooth transition. In this paper, we propose a new approach for high-quality domain translation with better controllability. The key idea is to preserve source features within a disentangled subspace of a target feature space. This allows our method to smoothly control the degree to which it preserves source features while generating images from an entirely new domain using only a single model. Our extensive experiments show that the proposed method can produce more consistent and realistic images than previous works and maintain precise controllability over different levels of transformation. The code is available at https://github.com/LeeDongYeun/FixNoise.
I See-Through You: A Framework for Removing Foreground Occlusion in Both Sparse and Dense Light Field Images
Jan 16, 2023Light field (LF) camera captures rich information from a scene. Using the information, the LF de-occlusion (LF-DeOcc) task aims to reconstruct the occlusion-free center view image. Existing LF-DeOcc studies mainly focus on the sparsely sampled (sparse) LF images where most of the occluded regions are visible in other views due to the large disparity. In this paper, we expand LF-DeOcc in more challenging datasets, densely sampled (dense) LF images, which are taken by a micro-lens-based portable LF camera. Due to the small disparity ranges of dense LF images, most of the background regions are invisible in any view. To apply LF-DeOcc in both LF datasets, we propose a framework, ISTY, which is defined and divided into three roles: (1) extract LF features, (2) define the occlusion, and (3) inpaint occluded regions. By dividing the framework into three specialized components according to the roles, the development and analysis can be easier. Furthermore, an explainable intermediate representation, an occlusion mask, can be obtained in the proposed framework. The occlusion mask is useful for comprehensive analysis of the model and other applications by manipulating the mask. In experiments, qualitative and quantitative results show that the proposed framework outperforms state-of-the-art LF-DeOcc methods in both sparse and dense LF datasets.
Fix the Noise: Disentangling Source Feature for Transfer Learning of StyleGAN
May 02, 2022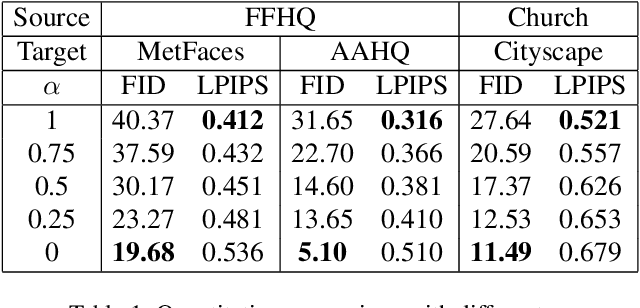
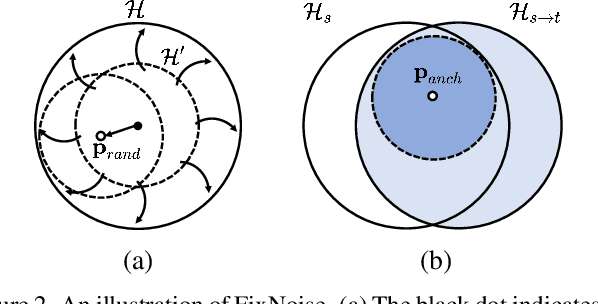
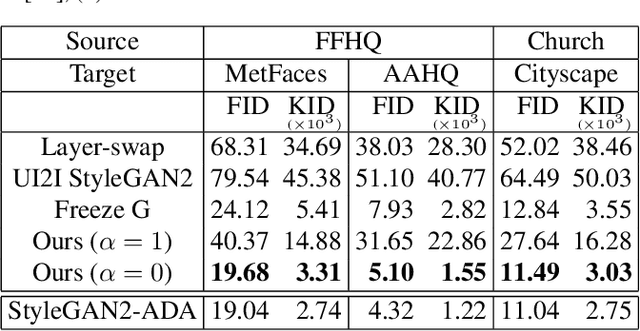

Transfer learning of StyleGAN has recently shown great potential to solve diverse tasks, especially in domain translation. Previous methods utilized a source model by swapping or freezing weights during transfer learning, however, they have limitations on visual quality and controlling source features. In other words, they require additional models that are computationally demanding and have restricted control steps that prevent a smooth transition. In this paper, we propose a new approach to overcome these limitations. Instead of swapping or freezing, we introduce a simple feature matching loss to improve generation quality. In addition, to control the degree of source features, we train a target model with the proposed strategy, FixNoise, to preserve the source features only in a disentangled subspace of a target feature space. Owing to the disentangled feature space, our method can smoothly control the degree of the source features in a single model. Extensive experiments demonstrate that the proposed method can generate more consistent and realistic images than previous works.
Integral Policy Iterations for Reinforcement Learning Problems in Continuous Time and Space
May 09, 2017
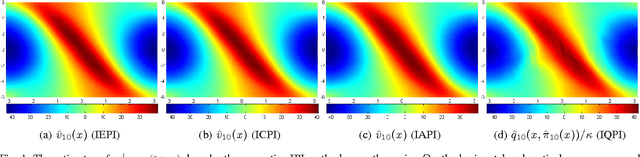


Policy iteration (PI) is a recursive process of policy evaluation and improvement to solve an optimal decision-making, e.g., reinforcement learning (RL) or optimal control problem and has served as the fundamental to develop RL methods. Motivated by integral PI (IPI) schemes in optimal control and RL methods in continuous time and space (CTS), this paper proposes on-policy IPI to solve the general RL problem in CTS, with its environment modeled by an ordinary differential equation (ODE). In such continuous domain, we also propose four off-policy IPI methods---two are the ideal PI forms that use advantage and Q-functions, respectively, and the other two are natural extensions of the existing off-policy IPI schemes to our general RL framework. Compared to the IPI methods in optimal control, the proposed IPI schemes can be applied to more general situations and do not require an initial stabilizing policy to run; they are also strongly relevant to the RL algorithms in CTS such as advantage updating, Q-learning, and value-gradient based (VGB) greedy policy improvement. Our on-policy IPI is basically model-based but can be made partially model-free; each off-policy method is also either partially or completely model-free. The mathematical properties of the IPI methods---admissibility, monotone improvement, and convergence towards the optimal solution---are all rigorously proven, together with the equivalence of on- and off-policy IPI. Finally, the IPI methods are simulated with an inverted-pendulum model to support the theory and verify the performance.