 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantics: Disentangling Information Scope in Sparse Autoencoders for CLIP
Apr 07, 2026Sparse Autoencoders (SAEs) have emerged as a powerful tool for interpreting the internal representations of CLIP vision encoders, yet existing analyses largely focus on the semantic meaning of individual features. We introduce information scope as a complementary dimension of interpretability that characterizes how broadly an SAE feature aggregates visual evidence, ranging from localized, patch-specific cues to global, image-level signals. We observe that some SAE features respond consistently across spatial perturbations, while others shift unpredictably with minor input changes, indicating a fundamental distinction in their underlying scope. To quantify this, we propose the Contextual Dependency Score (CDS), which separates positionally stable local scope features from positionally variant global scope features. Our experiments show that features of different information scopes exert systematically different influences on CLIP's predictions and confidence. These findings establish information scope as a critical new axis for understanding CLIP representations and provide a deeper diagnostic view of SAE-derived features.
Advancing Multi-Robot Networks via MLLM-Driven Sensing, Communication, and Computation: A Comprehensive Survey
Mar 31, 2026Imagine advanced humanoid robots, powered by multimodal large language models (MLLMs), coordinating missions across industries like warehouse logistics, manufacturing, and safety rescue. While individual robots show local autonomy, realistic tasks demand coordination among multiple agents sharing vast streams of sensor data. Communication is indispensable, yet transmitting comprehensive data can overwhelm networks, especially when a system-level orchestrator or cloud-based MLLM fuses multimodal inputs for route planning or anomaly detection. These tasks are often initiated by high-level natural language instructions. This intent serves as a filter for resource optimization: by understanding the goal via MLLMs, the system can selectively activate relevant sensing modalities, dynamically allocate bandwidth, and determine computation placement. Thus, R2X is fundamentally an intent-to-resource orchestration problem where sensing, communication, and computation are jointly optimized to maximize task-level success under resource constraints. This survey examines how integrated design paves the way for multi-robot coordination under MLLM guidance. We review state-of-the-art sensing modalities, communication strategies, and computing approaches, highlighting how reasoning is split between on-device models and powerful edge/cloud servers. We present four end-to-end demonstrations (sense -> communicate -> compute -> act): (i) digital-twin warehouse navigation with predictive link context, (ii) mobility-driven proactive MCS control, (iii) a FollowMe robot with a semantic-sensing switch, and (iv) real-hardware open-vocabulary trash sorting via edge-assisted MLLM grounding. We emphasize system-level metrics -- payload, latency, and success -- to show why R2X orchestration outperforms purely on-device baselines.
PRISM: Video Dataset Condensation with Progressive Refinement and Insertion for Sparse Motion
May 28, 2025Video dataset condensation has emerged as a critical technique for addressing the computational challenges associated with large-scale video data processing in deep learning applications. While significant progress has been made in image dataset condensation, the video domain presents unique challenges due to the complex interplay between spatial content and temporal dynamics. This paper introduces PRISM, Progressive Refinement and Insertion for Sparse Motion, for video dataset condensation, a novel approach that fundamentally reconsiders how video data should be condensed. Unlike the previous method that separates static content from dynamic motion, our method preserves the essential interdependence between these elements. Our approach progressively refines and inserts frames to fully accommodate the motion in an action while achieving better performance but less storage, considering the relation of gradients for each frame. Extensive experiments across standard video action recognition benchmarks demonstrate that PRISM outperforms existing disentangled approaches while maintaining compact representations suitable for resource-constrained environments.
DAM: Domain-Aware Module for Multi-Domain Dataset Condensation
May 28, 2025Dataset Condensation (DC) has emerged as a promising solution to mitigate the computational and storage burdens associated with training deep learning models. However, existing DC methods largely overlook the multi-domain nature of modern datasets, which are increasingly composed of heterogeneous images spanning multiple domains. In this paper, we extend DC and introduce Multi-Domain Dataset Condensation (MDDC), which aims to condense data that generalizes across both single-domain and multi-domain settings. To this end, we propose the Domain-Aware Module (DAM), a training-time module that embeds domain-related features into each synthetic image via learnable spatial masks. As explicit domain labels are mostly unavailable in real-world datasets, we employ frequency-based pseudo-domain labeling, which leverages low-frequency amplitude statistics. DAM is only active during the condensation process, thus preserving the same images per class (IPC) with prior methods. Experiments show that DAM consistently improves in-domain, out-of-domain, and cross-architecture performance over baseline dataset condensation methods.
Self-supervised Transformation Learning for Equivariant Representations
Jan 15, 2025



Unsupervised representation learning has significantly advanced various machine learning tasks. In the computer vision domain, state-of-the-art approaches utilize transformations like random crop and color jitter to achieve invariant representations, embedding semantically the same inputs despite transformations. However, this can degrade performance in tasks requiring precise features, such as localization or flower classification. To address this, recent research incorporates equivariant representation learning, which captures transformation-sensitive information. However, current methods depend on transformation labels and thus struggle with interdependency and complex transformations. We propose Self-supervised Transformation Learning (STL), replacing transformation labels with transformation representations derived from image pairs. The proposed method ensures transformation representation is image-invariant and learns corresponding equivariant transformations, enhancing performance without increased batch complexity. We demonstrate the approach's effectiveness across diverse classification and detection tasks, outperforming existing methods in 7 out of 11 benchmarks and excelling in detection. By integrating complex transformations like AugMix, unusable by prior equivariant methods, this approach enhances performance across tasks, underscoring its adaptability and resilience. Additionally, its compatibility with various base models highlights its flexibility and broad applicability. The code is available at https://github.com/jaemyung-u/stl.
AH-OCDA: Amplitude-based Curriculum Learning and Hopfield Segmentation Model for Open Compound Domain Adaptation
Dec 03, 2024

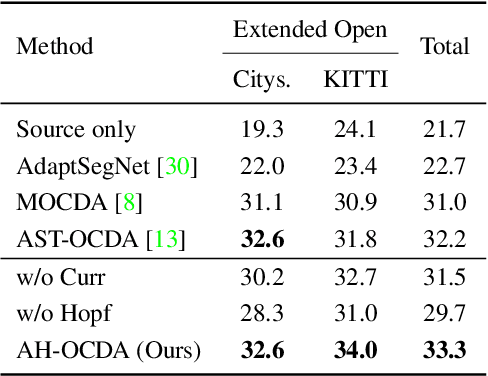

Open compound domain adaptation (OCDA) is a practical domain adaptation problem that consists of a source domain, target compound domain, and unseen open domain. In this problem, the absence of domain labels and pixel-level segmentation labels for both compound and open domains poses challenges to the direct application of existing domain adaptation and generalization methods. To address this issue, we propose Amplitude-based curriculum learning and a Hopfield segmentation model for Open Compound Domain Adaptation (AH-OCDA). Our method comprises two complementary components: 1) amplitude-based curriculum learning and 2) Hopfield segmentation model. Without prior knowledge of target domains within the compound domains, amplitude-based curriculum learning gradually induces the semantic segmentation model to adapt from the near-source compound domain to the far-source compound domain by ranking unlabeled compound domain images through Fast Fourier Transform (FFT). Additionally, the Hopfield segmentation model maps segmentation feature distributions from arbitrary domains to the feature distributions of the source domain. AH-OCDA achieves state-of-the-art performance on two OCDA benchmarks and extended open domains, demonstrating its adaptability to continuously changing compound domains and unseen open domains.
Unlocking the Capabilities of Masked Generative Models for Image Synthesis via Self-Guidance
Oct 17, 2024



Masked generative models (MGMs) have shown impressive generative ability while providing an order of magnitude efficient sampling steps compared to continuous diffusion models. However, MGMs still underperform in image synthesis compared to recent well-developed continuous diffusion models with similar size in terms of quality and diversity of generated samples. A key factor in the performance of continuous diffusion models stems from the guidance methods, which enhance the sample quality at the expense of diversity. In this paper, we extend these guidance methods to generalized guidance formulation for MGMs and propose a self-guidance sampling method, which leads to better generation quality. The proposed approach leverages an auxiliary task for semantic smoothing in vector-quantized token space, analogous to the Gaussian blur in continuous pixel space. Equipped with the parameter-efficient fine-tuning method and high-temperature sampling, MGMs with the proposed self-guidance achieve a superior quality-diversity trade-off, outperforming existing sampling methods in MGMs with more efficient training and sampling costs. Extensive experiments with the various sampling hyperparameters confirm the effectiveness of the proposed self-guidance.
Boundary-Recovering Network for Temporal Action Detection
Aug 18, 2024Temporal action detection (TAD) is challenging, yet fundamental for real-world video applications. Large temporal scale variation of actions is one of the most primary difficulties in TAD. Naturally, multi-scale features have potential in localizing actions of diverse lengths as widely used in object detection. Nevertheless, unlike objects in images, actions have more ambiguity in their boundaries. That is, small neighboring objects are not considered as a large one while short adjoining actions can be misunderstood as a long one. In the coarse-to-fine feature pyramid via pooling, these vague action boundaries can fade out, which we call 'vanishing boundary problem'. To this end, we propose Boundary-Recovering Network (BRN) to address the vanishing boundary problem. BRN constructs scale-time features by introducing a new axis called scale dimension by interpolating multi-scale features to the same temporal length. On top of scale-time features, scale-time blocks learn to exchange features across scale levels, which can effectively settle down the issue. Our extensive experiments demonstrate that our model outperforms the state-of-the-art on the two challenging benchmarks, ActivityNet-v1.3 and THUMOS14, with remarkably reduced degree of the vanishing boundary problem.
Stereo-Matching Knowledge Distilled Monocular Depth Estimation Filtered by Multiple Disparity Consistency
Jan 23, 2024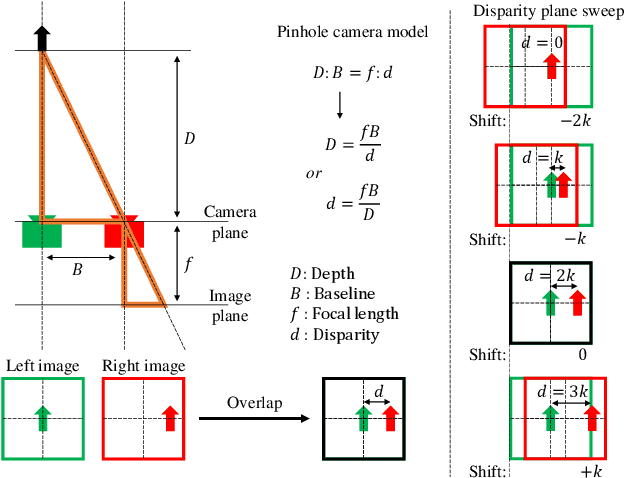
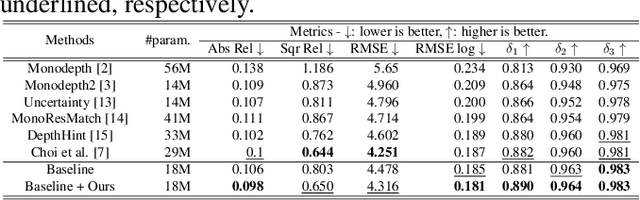
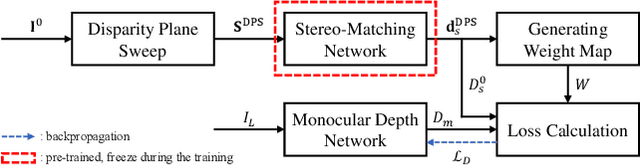
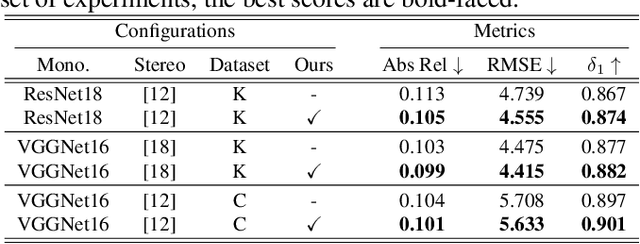
In stereo-matching knowledge distillation methods of the self-supervised monocular depth estimation, the stereo-matching network's knowledge is distilled into a monocular depth network through pseudo-depth maps. In these methods, the learning-based stereo-confidence network is generally utilized to identify errors in the pseudo-depth maps to prevent transferring the errors. However, the learning-based stereo-confidence networks should be trained with ground truth (GT), which is not feasible in a self-supervised setting. In this paper, we propose a method to identify and filter errors in the pseudo-depth map using multiple disparity maps by checking their consistency without the need for GT and a training process. Experimental results show that the proposed method outperforms the previous methods and works well on various configurations by filtering out erroneous areas where the stereo-matching is vulnerable, especially such as textureless regions, occlusion boundaries, and reflective surfaces.
Modeling Stereo-Confidence Out of the End-to-End Stereo-Matching Network via Disparity Plane Sweep
Jan 23, 2024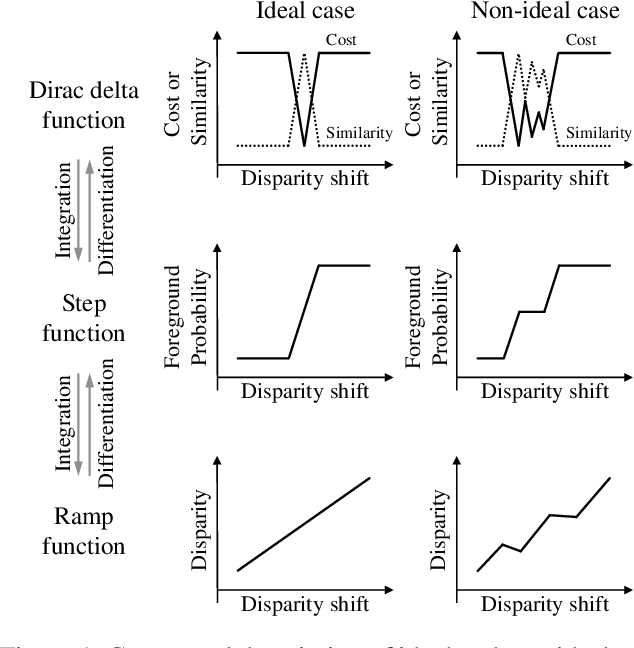
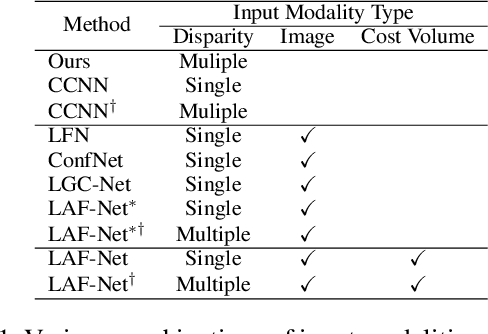
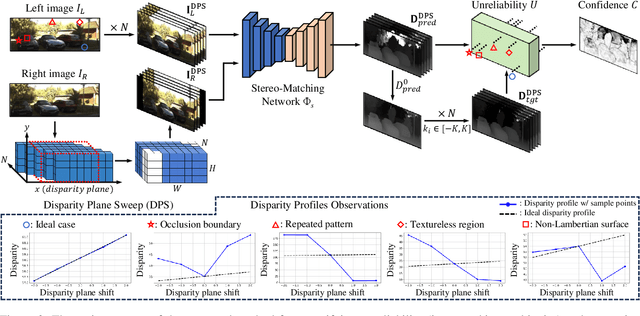
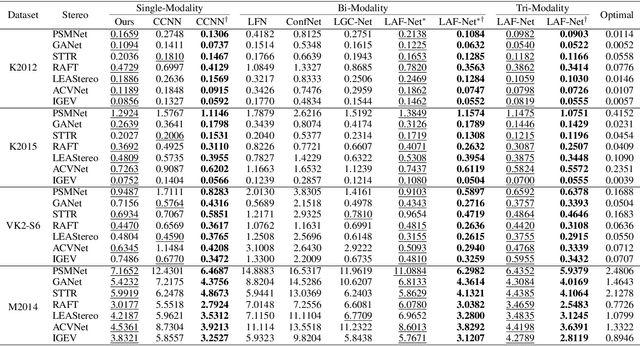
We propose a novel stereo-confidence that can be measured externally to various stereo-matching networks, offering an alternative input modality choice of the cost volume for learning-based approaches, especially in safety-critical systems. Grounded in the foundational concepts of disparity definition and the disparity plane sweep, the proposed stereo-confidence method is built upon the idea that any shift in a stereo-image pair should be updated in a corresponding amount shift in the disparity map. Based on this idea, the proposed stereo-confidence method can be summarized in three folds. 1) Using the disparity plane sweep, multiple disparity maps can be obtained and treated as a 3-D volume (predicted disparity volume), like the cost volume is constructed. 2) One of these disparity maps serves as an anchor, allowing us to define a desirable (or ideal) disparity profile at every spatial point. 3) By comparing the desirable and predicted disparity profiles, we can quantify the level of matching ambiguity between left and right images for confidence measurement. Extensive experimental results using various stereo-matching networks and datasets demonstrate that the proposed stereo-confidence method not only shows competitive performance on its own but also consistent performance improvements when it is used as an input modality for learning-based stereo-confidence methods.