 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMSE: Intrinsic Mixture of Spectral Experts Fine-tuning for Test-Time Adaptation
Mar 10, 2026Test-time adaptation (TTA) has been widely explored to prevent performance degradation when test data differ from the training distribution. However, fully leveraging the rich representations of large pretrained models with minimal parameter updates remains underexplored. In this paper, we propose Intrinsic Mixture of Spectral Experts (IMSE) that leverages the spectral experts inherently embedded in Vision Transformers. We decompose each linear layer via singular value decomposition (SVD) and adapt only the singular values, while keeping the singular vectors fixed. We further identify a key limitation of entropy minimization in TTA: it often induces feature collapse, causing the model to rely on domain-specific features rather than class-discriminative features. To address this, we propose a diversity maximization loss based on expert-input alignment, which encourages diverse utilization of spectral experts during adaptation. In the continual test-time adaptation (CTTA) scenario, beyond preserving pretrained knowledge, it is crucial to retain and reuse knowledge from previously observed domains. We introduce Domain-Aware Spectral Code Retrieval, which estimates input distributions to detect domain shifts, and retrieves adapted singular values for rapid adaptation. Consequently, our method achieves state-of-the-art performance on various distribution-shift benchmarks under the TTA setting. In CTTA and Gradual CTTA, it further improves accuracy by 3.4 percentage points (pp) and 2.4 pp, respectively, while requiring 385 times fewer trainable parameters. Our code is available at https://github.com/baek85/IMSE.
MuCo: Multi-turn Contrastive Learning for Multimodal Embedding Model
Feb 06, 2026Universal Multimodal embedding models built on Multimodal Large Language Models (MLLMs) have traditionally employed contrastive learning, which aligns representations of query-target pairs across different modalities. Yet, despite its empirical success, they are primarily built on a "single-turn" formulation where each query-target pair is treated as an independent data point. This paradigm leads to computational inefficiency when scaling, as it requires a separate forward pass for each pair and overlooks potential contextual relationships between multiple queries that can relate to the same context. In this work, we introduce Multi-Turn Contrastive Learning (MuCo), a dialogue-inspired framework that revisits this process. MuCo leverages the conversational nature of MLLMs to process multiple, related query-target pairs associated with a single image within a single forward pass. This allows us to extract a set of multiple query and target embeddings simultaneously, conditioned on a shared context representation, amplifying the effective batch size and overall training efficiency. Experiments exhibit MuCo with a newly curated 5M multimodal multi-turn dataset (M3T), which yields state-of-the-art retrieval performance on MMEB and M-BEIR benchmarks, while markedly enhancing both training efficiency and representation coherence across modalities. Code and M3T are available at https://github.com/naver-ai/muco
Inlier-Centric Post-Training Quantization for Object Detection Models
Feb 03, 2026Object detection is pivotal in computer vision, yet its immense computational demands make deployment slow and power-hungry, motivating quantization. However, task-irrelevant morphologies such as background clutter and sensor noise induce redundant activations (or anomalies). These anomalies expand activation ranges and skew activation distributions toward task-irrelevant responses, complicating bit allocation and weakening the preservation of informative features. Without a clear criterion to distinguish anomalies, suppressing them can inadvertently discard useful information. To address this, we present InlierQ, an inlier-centric post-training quantization approach that separates anomalies from informative inliers. InlierQ computes gradient-aware volume saliency scores, classifies each volume as an inlier or anomaly, and fits a posterior distribution over these scores using the Expectation-Maximization (EM) algorithm. This design suppresses anomalies while preserving informative features. InlierQ is label-free, drop-in, and requires only 64 calibration samples. Experiments on the COCO and nuScenes benchmarks show consistent reductions in quantization error for camera-based (2D and 3D) and LiDAR-based (3D) object detection.
FairASR: Fair Audio Contrastive Learning for Automatic Speech Recognition
Jun 12, 2025Large-scale ASR models have achieved remarkable gains in accuracy and robustness. However, fairness issues remain largely unaddressed despite their critical importance in real-world applications. In this work, we introduce FairASR, a system that mitigates demographic bias by learning representations that are uninformative about group membership, enabling fair generalization across demographic groups. Leveraging a multi-demographic dataset, our approach employs a gradient reversal layer to suppress demographic-discriminative features while maintaining the ability to capture generalizable speech patterns through an unsupervised contrastive loss. Experimental results show that FairASR delivers competitive overall ASR performance while significantly reducing performance disparities across different demographic groups.
PRISM: Video Dataset Condensation with Progressive Refinement and Insertion for Sparse Motion
May 28, 2025Video dataset condensation has emerged as a critical technique for addressing the computational challenges associated with large-scale video data processing in deep learning applications. While significant progress has been made in image dataset condensation, the video domain presents unique challenges due to the complex interplay between spatial content and temporal dynamics. This paper introduces PRISM, Progressive Refinement and Insertion for Sparse Motion, for video dataset condensation, a novel approach that fundamentally reconsiders how video data should be condensed. Unlike the previous method that separates static content from dynamic motion, our method preserves the essential interdependence between these elements. Our approach progressively refines and inserts frames to fully accommodate the motion in an action while achieving better performance but less storage, considering the relation of gradients for each frame. Extensive experiments across standard video action recognition benchmarks demonstrate that PRISM outperforms existing disentangled approaches while maintaining compact representations suitable for resource-constrained environments.
Self-supervised Transformation Learning for Equivariant Representations
Jan 15, 2025



Unsupervised representation learning has significantly advanced various machine learning tasks. In the computer vision domain, state-of-the-art approaches utilize transformations like random crop and color jitter to achieve invariant representations, embedding semantically the same inputs despite transformations. However, this can degrade performance in tasks requiring precise features, such as localization or flower classification. To address this, recent research incorporates equivariant representation learning, which captures transformation-sensitive information. However, current methods depend on transformation labels and thus struggle with interdependency and complex transformations. We propose Self-supervised Transformation Learning (STL), replacing transformation labels with transformation representations derived from image pairs. The proposed method ensures transformation representation is image-invariant and learns corresponding equivariant transformations, enhancing performance without increased batch complexity. We demonstrate the approach's effectiveness across diverse classification and detection tasks, outperforming existing methods in 7 out of 11 benchmarks and excelling in detection. By integrating complex transformations like AugMix, unusable by prior equivariant methods, this approach enhances performance across tasks, underscoring its adaptability and resilience. Additionally, its compatibility with various base models highlights its flexibility and broad applicability. The code is available at https://github.com/jaemyung-u/stl.
Stochastic Attribute Modeling for Face Super-Resolution
Jul 16, 2022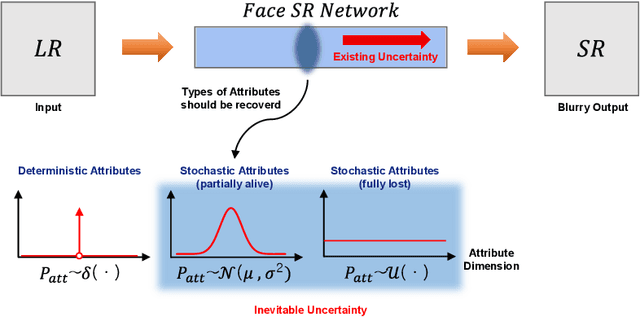
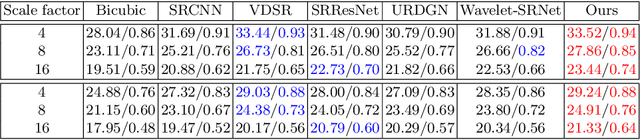

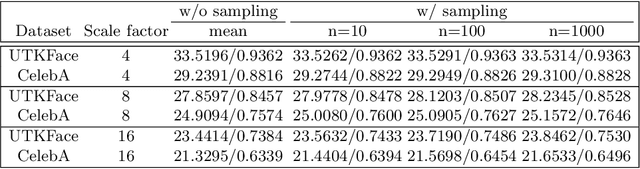
When a high-resolution (HR) image is degraded into a low-resolution (LR) image, the image loses some of the existing information. Consequently, multiple HR images can correspond to the LR image. Most of the existing methods do not consider the uncertainty caused by the stochastic attribute, which can only be probabilistically inferred. Therefore, the predicted HR images are often blurry because the network tries to reflect all possibilities in a single output image. To overcome this limitation, this paper proposes a novel face super-resolution (SR) scheme to take into the uncertainty by stochastic modeling. Specifically, the information in LR images is separately encoded into deterministic and stochastic attributes. Furthermore, an Input Conditional Attribute Predictor is proposed and separately trained to predict the partially alive stochastic attributes from only the LR images. Extensive evaluation shows that the proposed method successfully reduces the uncertainty in the learning process and outperforms the existing state-of-the-art approaches.
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning
Dec 03, 2021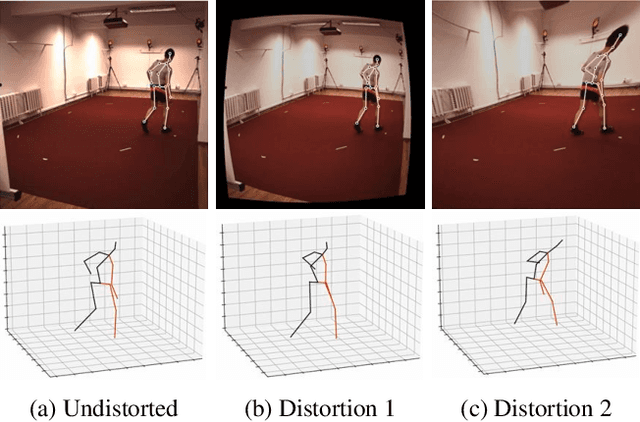

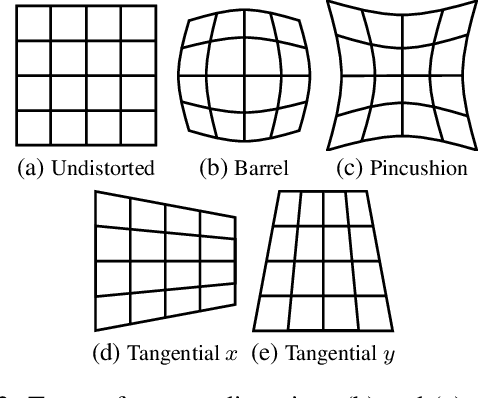
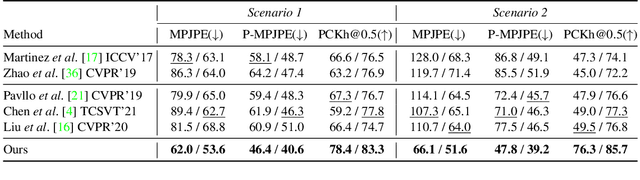
Existing 3D human pose estimation algorithms trained on distortion-free datasets suffer performance drop when applied to new scenarios with a specific camera distortion. In this paper, we propose a simple yet effective model for 3D human pose estimation in video that can quickly adapt to any distortion environment by utilizing MAML, a representative optimization-based meta-learning algorithm. We consider a sequence of 2D keypoints in a particular distortion as a single task of MAML. However, due to the absence of a large-scale dataset in a distorted environment, we propose an efficient method to generate synthetic distorted data from undistorted 2D keypoints. For the evaluation, we assume two practical testing situations depending on whether a motion capture sensor is available or not. In particular, we propose Inference Stage Optimization using bone-length symmetry and consistency. Extensive evaluation shows that our proposed method successfully adapts to various degrees of distortion in the testing phase and outperforms the existing state-of-the-art approaches. The proposed method is useful in practice because it does not require camera calibration and additional computations in a testing set-up.