 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSG: Scaled Spatial Guidance for Multi-Scale Visual Autoregressive Generation
Feb 05, 2026Visual autoregressive (VAR) models generate images through next-scale prediction, naturally achieving coarse-to-fine, fast, high-fidelity synthesis mirroring human perception. In practice, this hierarchy can drift at inference time, as limited capacity and accumulated error cause the model to deviate from its coarse-to-fine nature. We revisit this limitation from an information-theoretic perspective and deduce that ensuring each scale contributes high-frequency content not explained by earlier scales mitigates the train-inference discrepancy. With this insight, we propose Scaled Spatial Guidance (SSG), training-free, inference-time guidance that steers generation toward the intended hierarchy while maintaining global coherence. SSG emphasizes target high-frequency signals, defined as the semantic residual, isolated from a coarser prior. To obtain this prior, we leverage a principled frequency-domain procedure, Discrete Spatial Enhancement (DSE), which is devised to sharpen and better isolate the semantic residual through frequency-aware construction. SSG applies broadly across VAR models leveraging discrete visual tokens, regardless of tokenization design or conditioning modality. Experiments demonstrate SSG yields consistent gains in fidelity and diversity while preserving low latency, revealing untapped efficiency in coarse-to-fine image generation. Code is available at https://github.com/Youngwoo-git/SSG.
Inlier-Centric Post-Training Quantization for Object Detection Models
Feb 03, 2026Object detection is pivotal in computer vision, yet its immense computational demands make deployment slow and power-hungry, motivating quantization. However, task-irrelevant morphologies such as background clutter and sensor noise induce redundant activations (or anomalies). These anomalies expand activation ranges and skew activation distributions toward task-irrelevant responses, complicating bit allocation and weakening the preservation of informative features. Without a clear criterion to distinguish anomalies, suppressing them can inadvertently discard useful information. To address this, we present InlierQ, an inlier-centric post-training quantization approach that separates anomalies from informative inliers. InlierQ computes gradient-aware volume saliency scores, classifies each volume as an inlier or anomaly, and fits a posterior distribution over these scores using the Expectation-Maximization (EM) algorithm. This design suppresses anomalies while preserving informative features. InlierQ is label-free, drop-in, and requires only 64 calibration samples. Experiments on the COCO and nuScenes benchmarks show consistent reductions in quantization error for camera-based (2D and 3D) and LiDAR-based (3D) object detection.
PRISM: Video Dataset Condensation with Progressive Refinement and Insertion for Sparse Motion
May 28, 2025Video dataset condensation has emerged as a critical technique for addressing the computational challenges associated with large-scale video data processing in deep learning applications. While significant progress has been made in image dataset condensation, the video domain presents unique challenges due to the complex interplay between spatial content and temporal dynamics. This paper introduces PRISM, Progressive Refinement and Insertion for Sparse Motion, for video dataset condensation, a novel approach that fundamentally reconsiders how video data should be condensed. Unlike the previous method that separates static content from dynamic motion, our method preserves the essential interdependence between these elements. Our approach progressively refines and inserts frames to fully accommodate the motion in an action while achieving better performance but less storage, considering the relation of gradients for each frame. Extensive experiments across standard video action recognition benchmarks demonstrate that PRISM outperforms existing disentangled approaches while maintaining compact representations suitable for resource-constrained environments.
Unlocking the Capabilities of Masked Generative Models for Image Synthesis via Self-Guidance
Oct 17, 2024



Masked generative models (MGMs) have shown impressive generative ability while providing an order of magnitude efficient sampling steps compared to continuous diffusion models. However, MGMs still underperform in image synthesis compared to recent well-developed continuous diffusion models with similar size in terms of quality and diversity of generated samples. A key factor in the performance of continuous diffusion models stems from the guidance methods, which enhance the sample quality at the expense of diversity. In this paper, we extend these guidance methods to generalized guidance formulation for MGMs and propose a self-guidance sampling method, which leads to better generation quality. The proposed approach leverages an auxiliary task for semantic smoothing in vector-quantized token space, analogous to the Gaussian blur in continuous pixel space. Equipped with the parameter-efficient fine-tuning method and high-temperature sampling, MGMs with the proposed self-guidance achieve a superior quality-diversity trade-off, outperforming existing sampling methods in MGMs with more efficient training and sampling costs. Extensive experiments with the various sampling hyperparameters confirm the effectiveness of the proposed self-guidance.
Expanding Expressiveness of Diffusion Models with Limited Data via Self-Distillation based Fine-Tuning
Nov 02, 2023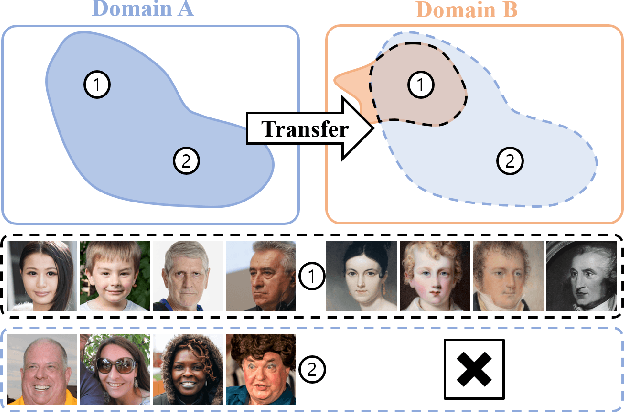
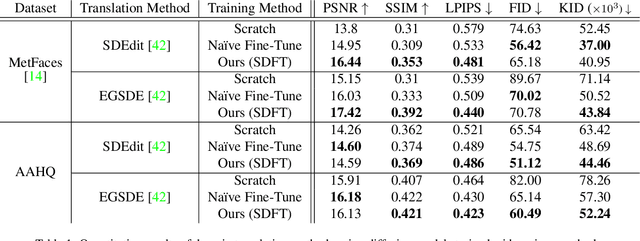

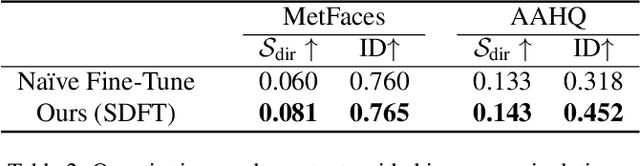
Training diffusion models on limited datasets poses challenges in terms of limited generation capacity and expressiveness, leading to unsatisfactory results in various downstream tasks utilizing pretrained diffusion models, such as domain translation and text-guided image manipulation. In this paper, we propose Self-Distillation for Fine-Tuning diffusion models (SDFT), a methodology to address these challenges by leveraging diverse features from diffusion models pretrained on large source datasets. SDFT distills more general features (shape, colors, etc.) and less domain-specific features (texture, fine details, etc) from the source model, allowing successful knowledge transfer without disturbing the training process on target datasets. The proposed method is not constrained by the specific architecture of the model and thus can be generally adopted to existing frameworks. Experimental results demonstrate that SDFT enhances the expressiveness of the diffusion model with limited datasets, resulting in improved generation capabilities across various downstream tasks.
Deep Cross-Modal Steganography Using Neural Representations
Jul 18, 2023Steganography is the process of embedding secret data into another message or data, in such a way that it is not easily noticeable. With the advancement of deep learning, Deep Neural Networks (DNNs) have recently been utilized in steganography. However, existing deep steganography techniques are limited in scope, as they focus on specific data types and are not effective for cross-modal steganography. Therefore, We propose a deep cross-modal steganography framework using Implicit Neural Representations (INRs) to hide secret data of various formats in cover images. The proposed framework employs INRs to represent the secret data, which can handle data of various modalities and resolutions. Experiments on various secret datasets of diverse types demonstrate that the proposed approach is expandable and capable of accommodating different modalities.
I See-Through You: A Framework for Removing Foreground Occlusion in Both Sparse and Dense Light Field Images
Jan 16, 2023Light field (LF) camera captures rich information from a scene. Using the information, the LF de-occlusion (LF-DeOcc) task aims to reconstruct the occlusion-free center view image. Existing LF-DeOcc studies mainly focus on the sparsely sampled (sparse) LF images where most of the occluded regions are visible in other views due to the large disparity. In this paper, we expand LF-DeOcc in more challenging datasets, densely sampled (dense) LF images, which are taken by a micro-lens-based portable LF camera. Due to the small disparity ranges of dense LF images, most of the background regions are invisible in any view. To apply LF-DeOcc in both LF datasets, we propose a framework, ISTY, which is defined and divided into three roles: (1) extract LF features, (2) define the occlusion, and (3) inpaint occluded regions. By dividing the framework into three specialized components according to the roles, the development and analysis can be easier. Furthermore, an explainable intermediate representation, an occlusion mask, can be obtained in the proposed framework. The occlusion mask is useful for comprehensive analysis of the model and other applications by manipulating the mask. In experiments, qualitative and quantitative results show that the proposed framework outperforms state-of-the-art LF-DeOcc methods in both sparse and dense LF datasets.