 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB4DL: A Benchmark for 4D LiDAR LLM in Spatio-Temporal Understanding
Aug 07, 2025Understanding dynamic outdoor environments requires capturing complex object interactions and their evolution over time. LiDAR-based 4D point clouds provide precise spatial geometry and rich temporal cues, making them ideal for representing real-world scenes. However, despite their potential, 4D LiDAR remains underexplored in the context of Multimodal Large Language Models (MLLMs) due to the absence of high-quality, modality-specific annotations and the lack of MLLM architectures capable of processing its high-dimensional composition. To address these challenges, we introduce B4DL, a new benchmark specifically designed for training and evaluating MLLMs on 4D LiDAR understanding. In addition, we propose a scalable data generation pipeline and an MLLM model that, for the first time, directly processes raw 4D LiDAR by bridging it with language understanding. Combined with our dataset and benchmark, our model offers a unified solution for spatio-temporal reasoning in dynamic outdoor environments. We provide rendered 4D LiDAR videos, generated dataset, and inference outputs on diverse scenarios at: https://mmb4dl.github.io/mmb4dl/
PRISM: Video Dataset Condensation with Progressive Refinement and Insertion for Sparse Motion
May 28, 2025Video dataset condensation has emerged as a critical technique for addressing the computational challenges associated with large-scale video data processing in deep learning applications. While significant progress has been made in image dataset condensation, the video domain presents unique challenges due to the complex interplay between spatial content and temporal dynamics. This paper introduces PRISM, Progressive Refinement and Insertion for Sparse Motion, for video dataset condensation, a novel approach that fundamentally reconsiders how video data should be condensed. Unlike the previous method that separates static content from dynamic motion, our method preserves the essential interdependence between these elements. Our approach progressively refines and inserts frames to fully accommodate the motion in an action while achieving better performance but less storage, considering the relation of gradients for each frame. Extensive experiments across standard video action recognition benchmarks demonstrate that PRISM outperforms existing disentangled approaches while maintaining compact representations suitable for resource-constrained environments.
DAM: Domain-Aware Module for Multi-Domain Dataset Condensation
May 28, 2025Dataset Condensation (DC) has emerged as a promising solution to mitigate the computational and storage burdens associated with training deep learning models. However, existing DC methods largely overlook the multi-domain nature of modern datasets, which are increasingly composed of heterogeneous images spanning multiple domains. In this paper, we extend DC and introduce Multi-Domain Dataset Condensation (MDDC), which aims to condense data that generalizes across both single-domain and multi-domain settings. To this end, we propose the Domain-Aware Module (DAM), a training-time module that embeds domain-related features into each synthetic image via learnable spatial masks. As explicit domain labels are mostly unavailable in real-world datasets, we employ frequency-based pseudo-domain labeling, which leverages low-frequency amplitude statistics. DAM is only active during the condensation process, thus preserving the same images per class (IPC) with prior methods. Experiments show that DAM consistently improves in-domain, out-of-domain, and cross-architecture performance over baseline dataset condensation methods.
Unlocking the Capabilities of Masked Generative Models for Image Synthesis via Self-Guidance
Oct 17, 2024



Masked generative models (MGMs) have shown impressive generative ability while providing an order of magnitude efficient sampling steps compared to continuous diffusion models. However, MGMs still underperform in image synthesis compared to recent well-developed continuous diffusion models with similar size in terms of quality and diversity of generated samples. A key factor in the performance of continuous diffusion models stems from the guidance methods, which enhance the sample quality at the expense of diversity. In this paper, we extend these guidance methods to generalized guidance formulation for MGMs and propose a self-guidance sampling method, which leads to better generation quality. The proposed approach leverages an auxiliary task for semantic smoothing in vector-quantized token space, analogous to the Gaussian blur in continuous pixel space. Equipped with the parameter-efficient fine-tuning method and high-temperature sampling, MGMs with the proposed self-guidance achieve a superior quality-diversity trade-off, outperforming existing sampling methods in MGMs with more efficient training and sampling costs. Extensive experiments with the various sampling hyperparameters confirm the effectiveness of the proposed self-guidance.
Expanding Expressiveness of Diffusion Models with Limited Data via Self-Distillation based Fine-Tuning
Nov 02, 2023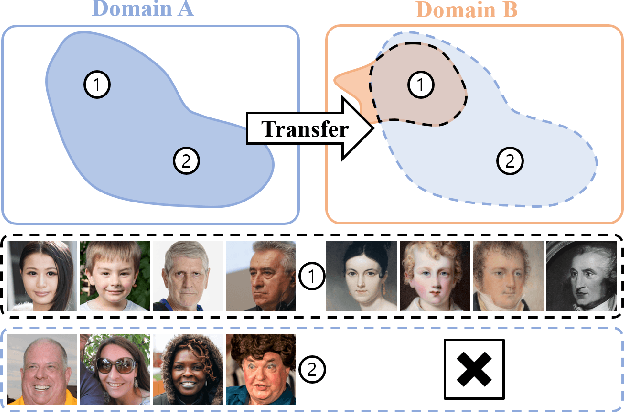
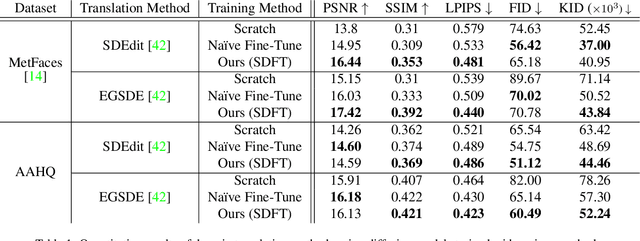

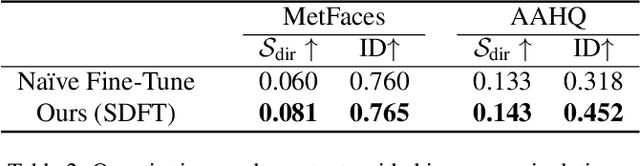
Training diffusion models on limited datasets poses challenges in terms of limited generation capacity and expressiveness, leading to unsatisfactory results in various downstream tasks utilizing pretrained diffusion models, such as domain translation and text-guided image manipulation. In this paper, we propose Self-Distillation for Fine-Tuning diffusion models (SDFT), a methodology to address these challenges by leveraging diverse features from diffusion models pretrained on large source datasets. SDFT distills more general features (shape, colors, etc.) and less domain-specific features (texture, fine details, etc) from the source model, allowing successful knowledge transfer without disturbing the training process on target datasets. The proposed method is not constrained by the specific architecture of the model and thus can be generally adopted to existing frameworks. Experimental results demonstrate that SDFT enhances the expressiveness of the diffusion model with limited datasets, resulting in improved generation capabilities across various downstream tasks.
Deep Cross-Modal Steganography Using Neural Representations
Jul 18, 2023Steganography is the process of embedding secret data into another message or data, in such a way that it is not easily noticeable. With the advancement of deep learning, Deep Neural Networks (DNNs) have recently been utilized in steganography. However, existing deep steganography techniques are limited in scope, as they focus on specific data types and are not effective for cross-modal steganography. Therefore, We propose a deep cross-modal steganography framework using Implicit Neural Representations (INRs) to hide secret data of various formats in cover images. The proposed framework employs INRs to represent the secret data, which can handle data of various modalities and resolutions. Experiments on various secret datasets of diverse types demonstrate that the proposed approach is expandable and capable of accommodating different modalities.
Reinforcement Learning-Based Black-Box Model Inversion Attacks
Apr 10, 2023
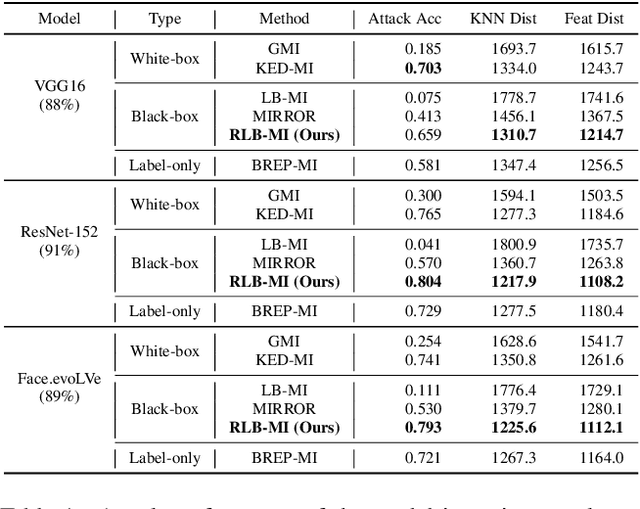


Model inversion attacks are a type of privacy attack that reconstructs private data used to train a machine learning model, solely by accessing the model. Recently, white-box model inversion attacks leveraging Generative Adversarial Networks (GANs) to distill knowledge from public datasets have been receiving great attention because of their excellent attack performance. On the other hand, current black-box model inversion attacks that utilize GANs suffer from issues such as being unable to guarantee the completion of the attack process within a predetermined number of query accesses or achieve the same level of performance as white-box attacks. To overcome these limitations, we propose a reinforcement learning-based black-box model inversion attack. We formulate the latent space search as a Markov Decision Process (MDP) problem and solve it with reinforcement learning. Our method utilizes the confidence scores of the generated images to provide rewards to an agent. Finally, the private data can be reconstructed using the latent vectors found by the agent trained in the MDP. The experiment results on various datasets and models demonstrate that our attack successfully recovers the private information of the target model by achieving state-of-the-art attack performance. We emphasize the importance of studies on privacy-preserving machine learning by proposing a more advanced black-box model inversion attack.
Training Time Adversarial Attack Aiming the Vulnerability of Continual Learning
Nov 29, 2022



Generally, regularization-based continual learning models limit access to the previous task data to imitate the real-world setting which has memory and privacy issues. However, this introduces a problem in these models by not being able to track the performance on each task. In other words, current continual learning methods are vulnerable to attacks done on the previous task. We demonstrate the vulnerability of regularization-based continual learning methods by presenting simple task-specific training time adversarial attack that can be used in the learning process of a new task. Training data generated by the proposed attack causes performance degradation on a specific task targeted by the attacker. Experiment results justify the vulnerability proposed in this paper and demonstrate the importance of developing continual learning models that are robust to adversarial attack.