 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDS-DETR: DETR with Masked Duplicate Suppressor
May 22, 2026The DEtection TRansformer (DETR) is a powerful end-to-end object detector, yet its one-to-one matching strategy suffers from slow convergence and low recall. A common approach to address this issue is to use one-to-many label assignment to provide more positive samples. However, existing methods that use one-to-many matching as an auxiliary objective lead to increased training costs, with their auxiliary decoders discarded during inference. To address this limitation, we propose MDS-DETR, which leverages both one-to-one and one-to-many supervision within a single decoder. Specifically, we introduce a Masked Duplicate Suppressor (MDS) that injects asymmetry into self-attention via confidence-based causal masking. MDS filters out the duplicates generated by the one-to-many supervised layer, enables explainable, duplicate-free predictions in a fully end-to-end framework. MDS-DETR outperforms existing one-to-many DETR variants such as MS-DETR, MR.DETR and Relation-DETR, without relying on any additional queries or auxiliary decoders. Under a 12-epoch training schedule on MS COCO with a ResNet-50 backbone, MDS-DETR achieves a +2.8 mAP improvement over Deformable-DETR with only a 5\% increase in training time, and outperforms the state-of-the-art MR.DETR by +0.3 mAP while being even 20\% faster in training. Our code and models are available at \href{https://github.com/dcholee/mds-detr}{https://github.com/DChoLee/MDS-DETR}.
ConceptPrism: Concept Disentanglement in Personalized Diffusion Models via Residual Token Optimization
Feb 23, 2026Personalized text-to-image generation suffers from concept entanglement, where irrelevant residual information from reference images is captured, leading to a trade-off between concept fidelity and text alignment. Recent disentanglement approaches attempt to solve this utilizing manual guidance, such as linguistic cues or segmentation masks, which limits their applicability and fails to fully articulate the target concept. In this paper, we propose ConceptPrism, a novel framework that automatically disentangles the shared visual concept from image-specific residuals by comparing images within a set. Our method jointly optimizes a target token and image-wise residual tokens using two complementary objectives: a reconstruction loss to ensure fidelity, and a novel exclusion loss that compels residual tokens to discard the shared concept. This process allows the target token to capture the pure concept without direct supervision. Extensive experiments demonstrate that ConceptPrism effectively resolves concept entanglement, achieving a significantly improved trade-off between fidelity and alignment.
Comparison Reveals Commonality: Customized Image Generation through Contrastive Inversion
Aug 11, 2025The recent demand for customized image generation raises a need for techniques that effectively extract the common concept from small sets of images. Existing methods typically rely on additional guidance, such as text prompts or spatial masks, to capture the common target concept. Unfortunately, relying on manually provided guidance can lead to incomplete separation of auxiliary features, which degrades generation quality.In this paper, we propose Contrastive Inversion, a novel approach that identifies the common concept by comparing the input images without relying on additional information. We train the target token along with the image-wise auxiliary text tokens via contrastive learning, which extracts the well-disentangled true semantics of the target. Then we apply disentangled cross-attention fine-tuning to improve concept fidelity without overfitting. Experimental results and analysis demonstrate that our method achieves a balanced, high-level performance in both concept representation and editing, outperforming existing techniques.
Unlocking the Capabilities of Masked Generative Models for Image Synthesis via Self-Guidance
Oct 17, 2024



Masked generative models (MGMs) have shown impressive generative ability while providing an order of magnitude efficient sampling steps compared to continuous diffusion models. However, MGMs still underperform in image synthesis compared to recent well-developed continuous diffusion models with similar size in terms of quality and diversity of generated samples. A key factor in the performance of continuous diffusion models stems from the guidance methods, which enhance the sample quality at the expense of diversity. In this paper, we extend these guidance methods to generalized guidance formulation for MGMs and propose a self-guidance sampling method, which leads to better generation quality. The proposed approach leverages an auxiliary task for semantic smoothing in vector-quantized token space, analogous to the Gaussian blur in continuous pixel space. Equipped with the parameter-efficient fine-tuning method and high-temperature sampling, MGMs with the proposed self-guidance achieve a superior quality-diversity trade-off, outperforming existing sampling methods in MGMs with more efficient training and sampling costs. Extensive experiments with the various sampling hyperparameters confirm the effectiveness of the proposed self-guidance.
FRED: Towards a Full Rotation-Equivariance in Aerial Image Object Detection
Dec 22, 2023Rotation-equivariance is an essential yet challenging property in oriented object detection. While general object detectors naturally leverage robustness to spatial shifts due to the translation-equivariance of the conventional CNNs, achieving rotation-equivariance remains an elusive goal. Current detectors deploy various alignment techniques to derive rotation-invariant features, but still rely on high capacity models and heavy data augmentation with all possible rotations. In this paper, we introduce a Fully Rotation-Equivariant Oriented Object Detector (FRED), whose entire process from the image to the bounding box prediction is strictly equivariant. Specifically, we decouple the invariant task (object classification) and the equivariant task (object localization) to achieve end-to-end equivariance. We represent the bounding box as a set of rotation-equivariant vectors to implement rotation-equivariant localization. Moreover, we utilized these rotation-equivariant vectors as offsets in the deformable convolution, thereby enhancing the existing advantages of spatial adaptation. Leveraging full rotation-equivariance, our FRED demonstrates higher robustness to image-level rotation compared to existing methods. Furthermore, we show that FRED is one step closer to non-axis aligned learning through our experiments. Compared to state-of-the-art methods, our proposed method delivers comparable performance on DOTA-v1.0 and outperforms by 1.5 mAP on DOTA-v1.5, all while significantly reducing the model parameters to 16%.
Associative Partial Domain Adaptation
Aug 07, 2020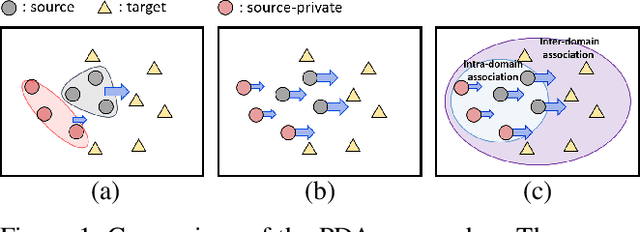
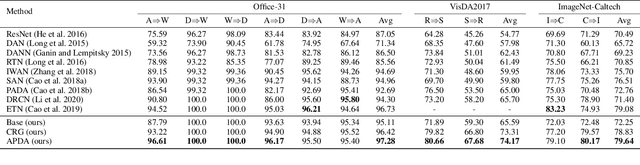
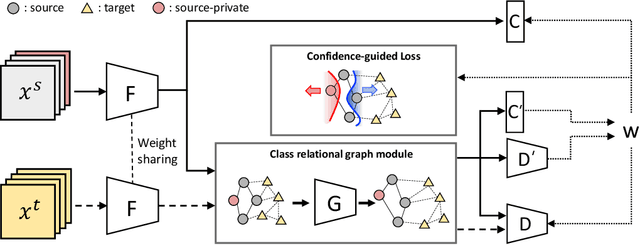
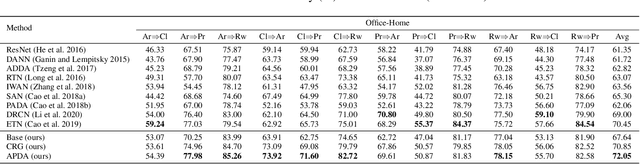
Partial Adaptation (PDA) addresses a practical scenario in which the target domain contains only a subset of classes in the source domain. While PDA should take into account both class-level and sample-level to mitigate negative transfer, current approaches mostly rely on only one of them. In this paper, we propose a novel approach to fully exploit multi-level associations that can arise in PDA. Our Associative Partial Domain Adaptation (APDA) utilizes intra-domain association to actively select out non-trivial anomaly samples in each source-private class that sample-level weighting cannot handle. Additionally, our method considers inter-domain association to encourage positive transfer by mapping between nearby target samples and source samples with high label-commonness. For this, we exploit feature propagation in a proposed label space consisting of source ground-truth labels and target probabilistic labels. We further propose a geometric guidance loss based on the label commonness of each source class to encourage positive transfer. Our APDA consistently achieves state-of-the-art performance across public datasets.
Sample-based Regularization: A Transfer Learning Strategy Toward Better Generalization
Jul 10, 2020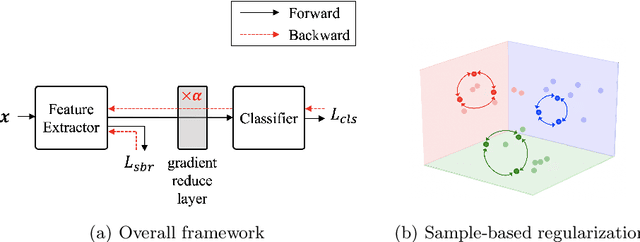
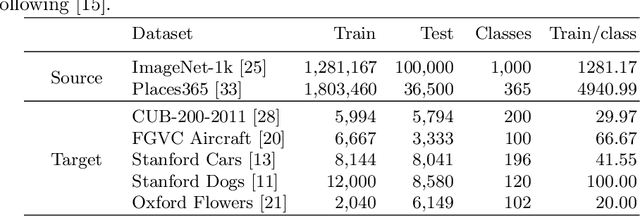
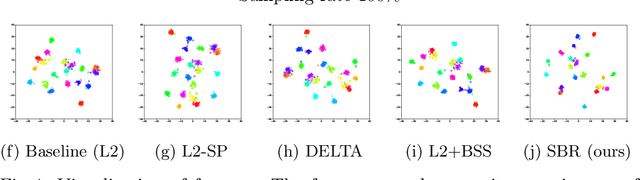
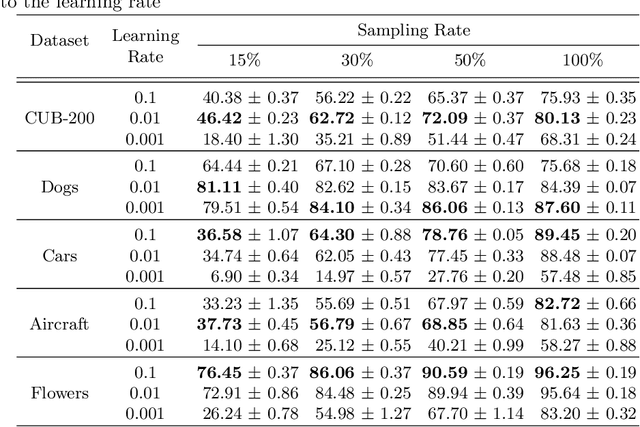
Training a deep neural network with a small amount of data is a challenging problem as it is vulnerable to overfitting. However, one of the practical difficulties that we often face is to collect many samples. Transfer learning is a cost-effective solution to this problem. By using the source model trained with a large-scale dataset, the target model can alleviate the overfitting originated from the lack of training data. Resorting to the ability of generalization of the source model, several methods proposed to use the source knowledge during the whole training procedure. However, this is likely to restrict the potential of the target model and some transferred knowledge from the source can interfere with the training procedure. For improving the generalization performance of the target model with a few training samples, we proposed a regularization method called sample-based regularization (SBR), which does not rely on the source's knowledge during training. With SBR, we suggested a new training framework for transfer learning. Experimental results showed that our framework outperformed existing methods in various configurations.
Integrating Multiple Receptive Fields through Grouped Active Convolution
Nov 11, 2018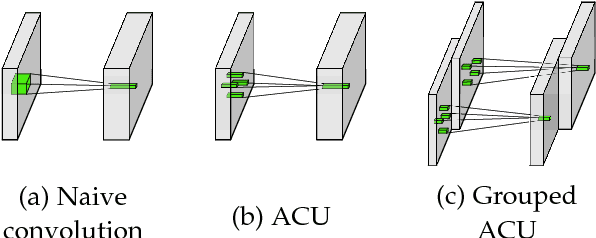
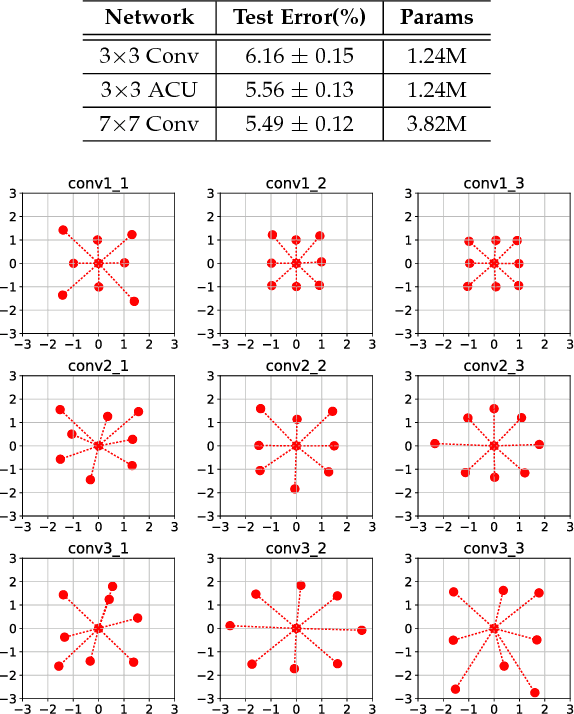
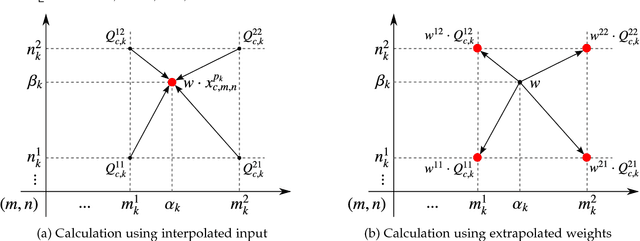
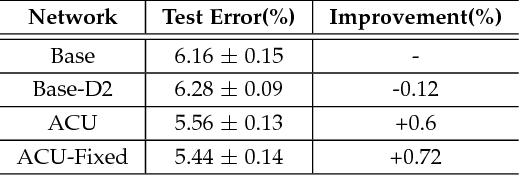
Convolutional networks have achieved great success in various vision tasks. This is mainly due to a considerable amount of research on network structure. In this study, instead of focusing on architectures, we focused on the convolution unit itself. The existing convolution unit has a fixed shape, and is limited to observing restricted receptive fields. In an earlier work, we proposed the active convolution unit (ACU), which can freely define its shape and learn by itself. In this paper, we propose a detailed analysis of the proposed unit and show that it is an efficient representation of a sparse weight convolution. Furthermore, we expand the unit to a grouped ACU, which can observe multiple receptive fields in one layer. We found that the performance of a naive grouped convolution is degraded by increasing the number of groups; however, the proposed unit retains the accuracy even though the number of parameters reduces. Based on this result, we suggest a depthwise ACU, and various experiments have shown that our unit is efficient and can replace the existing convolutions.
Constructing Fast Network through Deconstruction of Convolution
Oct 31, 2018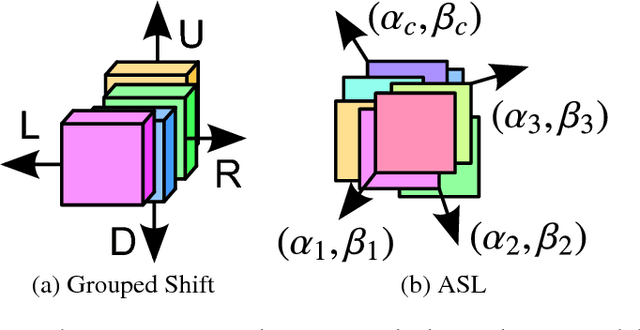

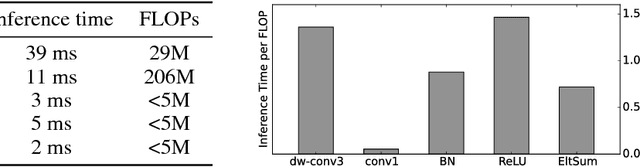

Convolutional neural networks have achieved great success in various vision tasks; however, they incur heavy resource costs. By using deeper and wider networks, network accuracy can be improved rapidly. However, in an environment with limited resources (e.g., mobile applications), heavy networks may not be usable. This study shows that naive convolution can be deconstructed into a shift operation and pointwise convolution. To cope with various convolutions, we propose a new shift operation called active shift layer (ASL) that formulates the amount of shift as a learnable function with shift parameters. This new layer can be optimized end-to-end through backpropagation and it can provide optimal shift values. Finally, we apply this layer to a light and fast network that surpasses existing state-of-the-art networks.
Active Convolution: Learning the Shape of Convolution for Image Classification
Mar 27, 2017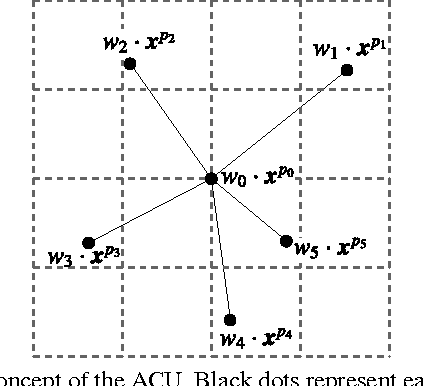
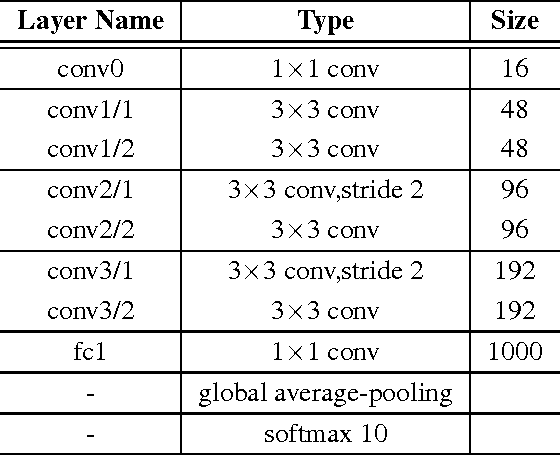
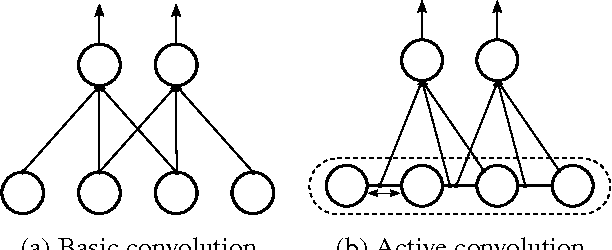

In recent years, deep learning has achieved great success in many computer vision applications. Convolutional neural networks (CNNs) have lately emerged as a major approach to image classification. Most research on CNNs thus far has focused on developing architectures such as the Inception and residual networks. The convolution layer is the core of the CNN, but few studies have addressed the convolution unit itself. In this paper, we introduce a convolution unit called the active convolution unit (ACU). A new convolution has no fixed shape, because of which we can define any form of convolution. Its shape can be learned through backpropagation during training. Our proposed unit has a few advantages. First, the ACU is a generalization of convolution; it can define not only all conventional convolutions, but also convolutions with fractional pixel coordinates. We can freely change the shape of the convolution, which provides greater freedom to form CNN structures. Second, the shape of the convolution is learned while training and there is no need to tune it by hand. Third, the ACU can learn better than a conventional unit, where we obtained the improvement simply by changing the conventional convolution to an ACU. We tested our proposed method on plain and residual networks, and the results showed significant improvement using our method on various datasets and architectures in comparison with the baseline.