 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Sample-based Regularization: A Transfer Learning Strategy Toward Better Generalization
Jul 10, 2020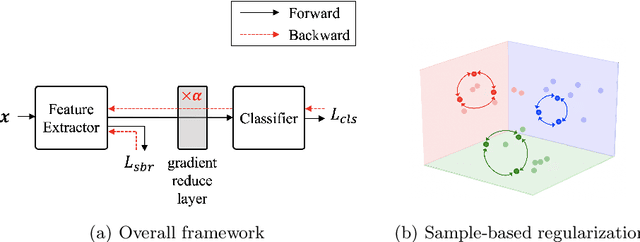
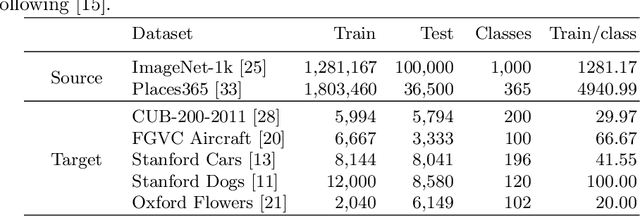
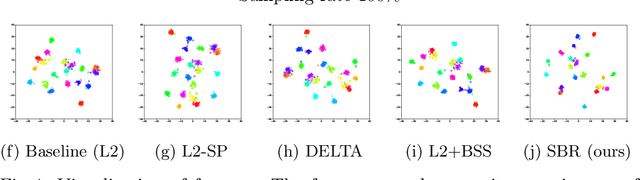
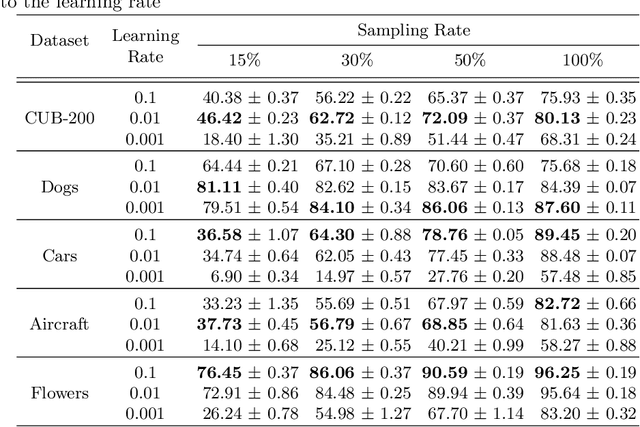
Training a deep neural network with a small amount of data is a challenging problem as it is vulnerable to overfitting. However, one of the practical difficulties that we often face is to collect many samples. Transfer learning is a cost-effective solution to this problem. By using the source model trained with a large-scale dataset, the target model can alleviate the overfitting originated from the lack of training data. Resorting to the ability of generalization of the source model, several methods proposed to use the source knowledge during the whole training procedure. However, this is likely to restrict the potential of the target model and some transferred knowledge from the source can interfere with the training procedure. For improving the generalization performance of the target model with a few training samples, we proposed a regularization method called sample-based regularization (SBR), which does not rely on the source's knowledge during training. With SBR, we suggested a new training framework for transfer learning. Experimental results showed that our framework outperformed existing methods in various configurations.
Few-Shot Classification on Unseen Domains by Learning Disparate Modulators
Sep 11, 2019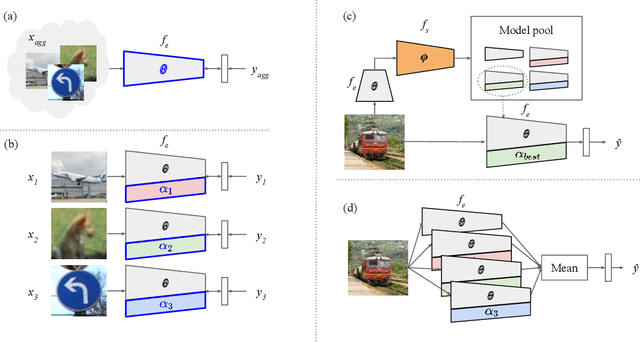
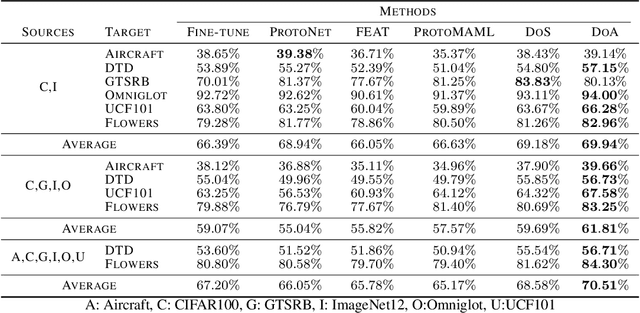
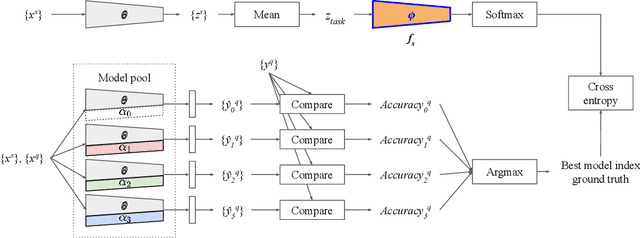
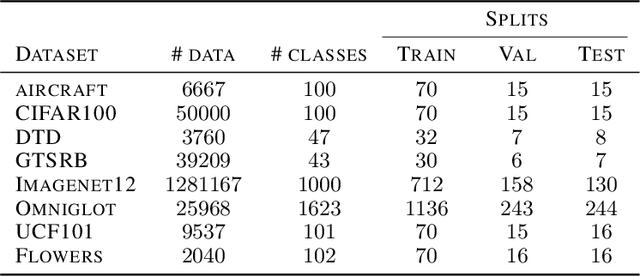
Although few-shot learning studies have advanced rapidly with the help of meta-learning, their practical applicability is still limited because most of them assumed that all meta-training and meta-testing examples came from the same domain. Leveraging meta-learning on multiple heterogeneous domains, we propose a few-shot classification method which adapts to novel domains as well as novel classes, which is believed to be more practical in the real world. To address this challenging problem, we start from building a pool of multiple embedding models. Inspired by multi-task learning techniques, we design each model to have its own per-layer modulator with a base network shared by others. This allows the pool to have representational diversity as a whole without losing beneficial domain-invariant features. Experimental results show that our framework can be utilized effectively for few-shot learning on unseen domains by learning to select the best model or averaging all models in the pool. Additionally, ours outperform previous methods in few-shot classification tasks on multiple seen domains.
Discriminative Few-Shot Learning Based on Directional Statistics
Jun 05, 2019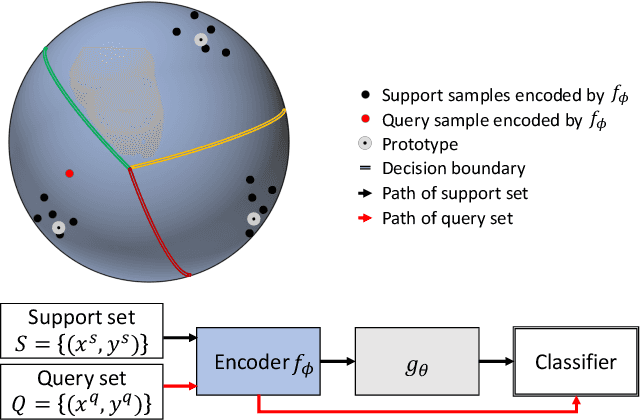

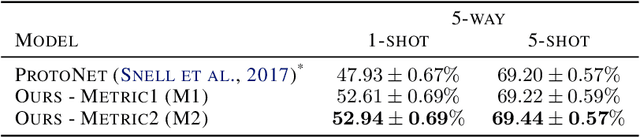
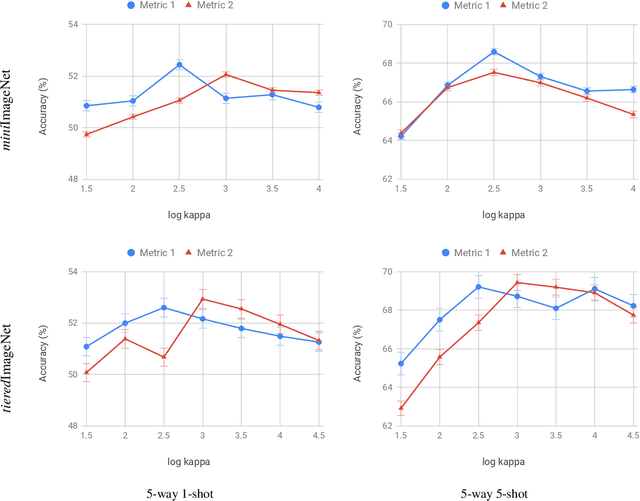
Metric-based few-shot learning methods try to overcome the difficulty due to the lack of training examples by learning embedding to make comparison easy. We propose a novel algorithm to generate class representatives for few-shot classification tasks. As a probabilistic model for learned features of inputs, we consider a mixture of von Mises-Fisher distributions which is known to be more expressive than Gaussian in a high dimensional space. Then, from a discriminative classifier perspective, we get a better class representative considering inter-class correlation which has not been addressed by conventional few-shot learning algorithms. We apply our method to \emph{mini}ImageNet and \emph{tiered}ImageNet datasets, and show that the proposed approach outperforms other comparable methods in few-shot classification tasks.
Grouped Convolutional Neural Networks for Multivariate Time Series
May 31, 2018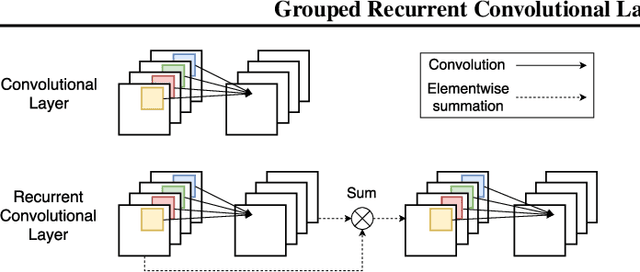
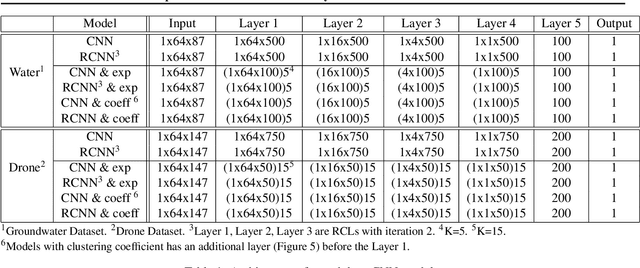
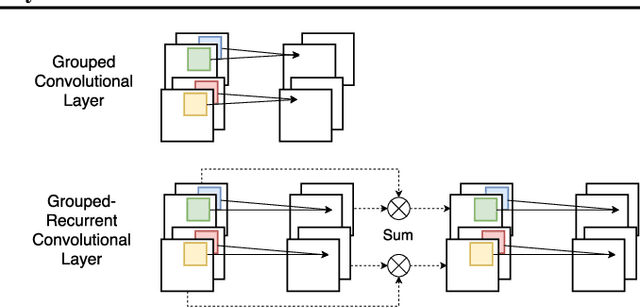
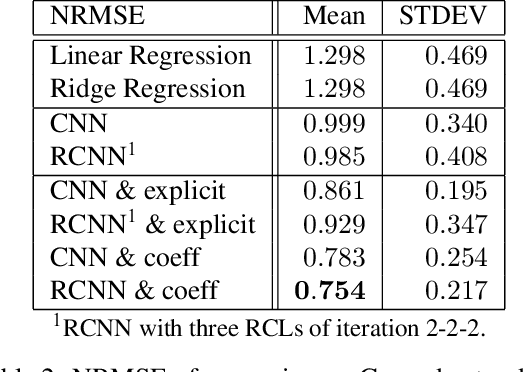
Analyzing multivariate time series data is important for many applications such as automated control, fault diagnosis and anomaly detection. One of the key challenges is to learn latent features automatically from dynamically changing multivariate input. In visual recognition tasks, convolutional neural networks (CNNs) have been successful to learn generalized feature extractors with shared parameters over the spatial domain. However, when high-dimensional multivariate time series is given, designing an appropriate CNN model structure becomes challenging because the kernels may need to be extended through the full dimension of the input volume. To address this issue, we present two structure learning algorithms for deep CNN models. Our algorithms exploit the covariance structure over multiple time series to partition input volume into groups. The first algorithm learns the group CNN structures explicitly by clustering individual input sequences. The second algorithm learns the group CNN structures implicitly from the error backpropagation. In experiments with two real-world datasets, we demonstrate that our group CNNs outperform existing CNN based regression methods.