 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Tokenizer is Key to Consistent Representation
Jul 09, 2025Speech tokenization is crucial in digital speech processing, converting continuous speech signals into discrete units for various computational tasks. This paper introduces a novel speech tokenizer with broad applicability across downstream tasks. While recent advances in residual vector quantization (RVQ) have incorporated semantic elements, they often neglect critical acoustic features. We propose an advanced approach that simultaneously encodes both linguistic and acoustic information, preserving prosodic and emotional content. Our method significantly enhances speech representation fidelity across diverse applications. Empirical evaluations demonstrate its effectiveness in speech coding, voice conversion, emotion recognition, and multimodal language modeling, without requiring additional training. This versatility underscores its potential as a key tool for advancing AI-driven speech processing.
Few-Shot Classification on Unseen Domains by Learning Disparate Modulators
Sep 11, 2019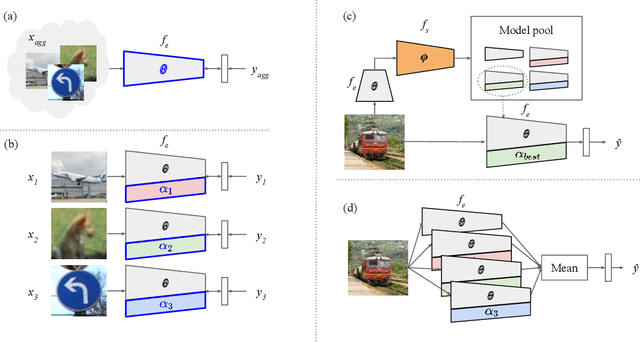
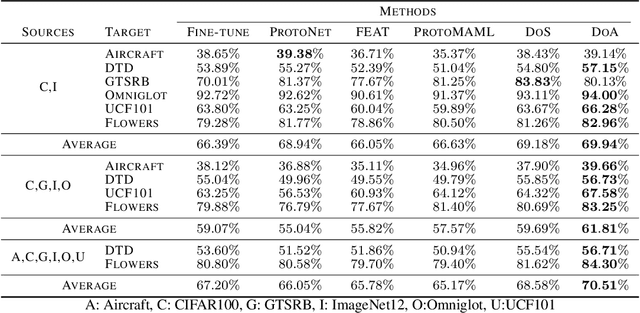
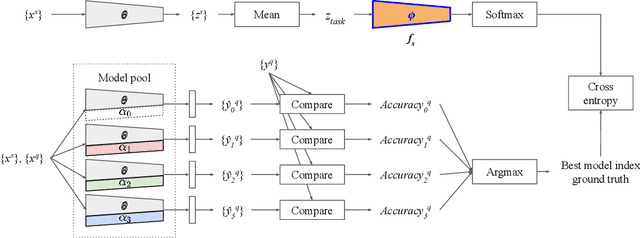
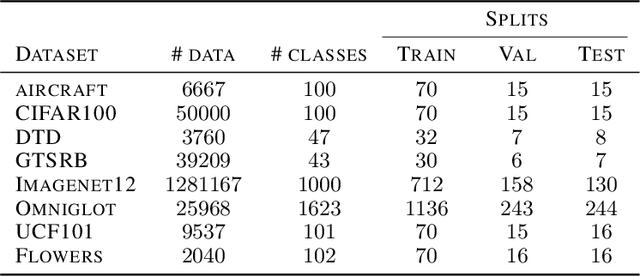
Although few-shot learning studies have advanced rapidly with the help of meta-learning, their practical applicability is still limited because most of them assumed that all meta-training and meta-testing examples came from the same domain. Leveraging meta-learning on multiple heterogeneous domains, we propose a few-shot classification method which adapts to novel domains as well as novel classes, which is believed to be more practical in the real world. To address this challenging problem, we start from building a pool of multiple embedding models. Inspired by multi-task learning techniques, we design each model to have its own per-layer modulator with a base network shared by others. This allows the pool to have representational diversity as a whole without losing beneficial domain-invariant features. Experimental results show that our framework can be utilized effectively for few-shot learning on unseen domains by learning to select the best model or averaging all models in the pool. Additionally, ours outperform previous methods in few-shot classification tasks on multiple seen domains.
Discriminative Few-Shot Learning Based on Directional Statistics
Jun 05, 2019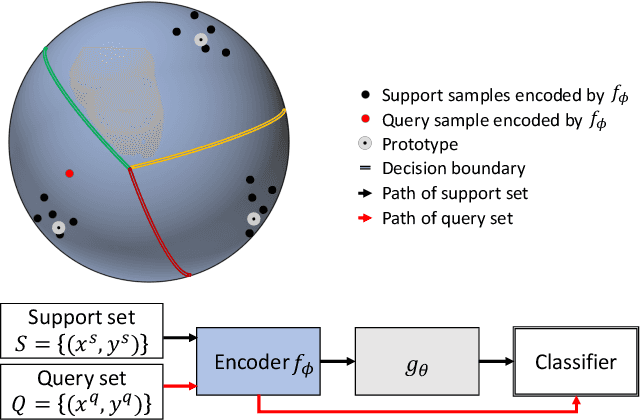

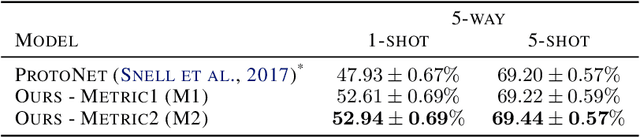
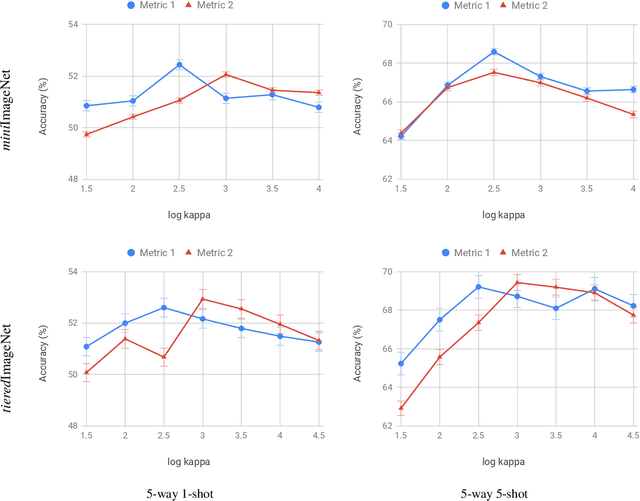
Metric-based few-shot learning methods try to overcome the difficulty due to the lack of training examples by learning embedding to make comparison easy. We propose a novel algorithm to generate class representatives for few-shot classification tasks. As a probabilistic model for learned features of inputs, we consider a mixture of von Mises-Fisher distributions which is known to be more expressive than Gaussian in a high dimensional space. Then, from a discriminative classifier perspective, we get a better class representative considering inter-class correlation which has not been addressed by conventional few-shot learning algorithms. We apply our method to \emph{mini}ImageNet and \emph{tiered}ImageNet datasets, and show that the proposed approach outperforms other comparable methods in few-shot classification tasks.
Meta Continual Learning
Jun 11, 2018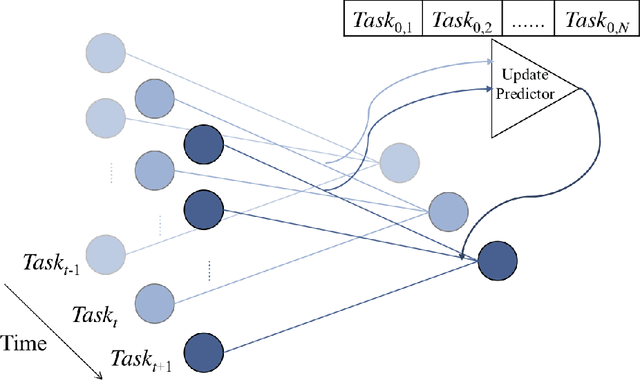

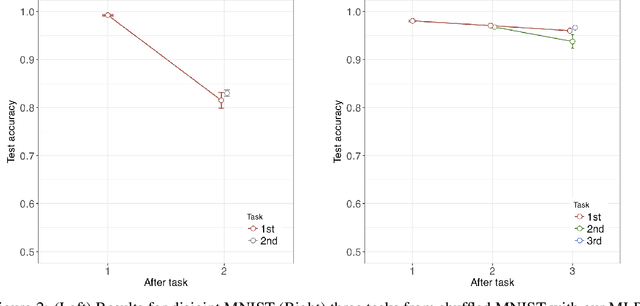
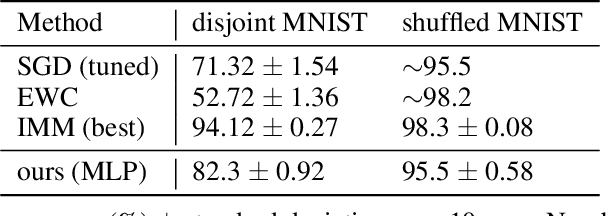
Using neural networks in practical settings would benefit from the ability of the networks to learn new tasks throughout their lifetimes without forgetting the previous tasks. This ability is limited in the current deep neural networks by a problem called catastrophic forgetting, where training on new tasks tends to severely degrade performance on previous tasks. One way to lessen the impact of the forgetting problem is to constrain parameters that are important to previous tasks to stay close to the optimal parameters. Recently, multiple competitive approaches for computing the importance of the parameters with respect to the previous tasks have been presented. In this paper, we propose a learning to optimize algorithm for mitigating catastrophic forgetting. Instead of trying to formulate a new constraint function ourselves, we propose to train another neural network to predict parameter update steps that respect the importance of parameters to the previous tasks. In the proposed meta-training scheme, the update predictor is trained to minimize loss on a combination of current and past tasks. We show experimentally that the proposed approach works in the continual learning setting.