 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Multi-View Polymer Representations for the Open Polymer Prediction
Nov 14, 2025We address polymer property prediction with a multi-view design that exploits complementary representations. Our system integrates four families: (i) tabular RDKit/Morgan descriptors, (ii) graph neural networks, (iii) 3D-informed representations, and (iv) pretrained SMILES language models, and averages per-property predictions via a uniform ensemble. Models are trained with 10-fold splits and evaluated with SMILES test-time augmentation. The approach ranks 9th of 2241 teams in the Open Polymer Prediction Challenge at NeurIPS 2025. The submitted ensemble achieves a public MAE of 0.057 and a private MAE of 0.082.
Enhancing Generalization in Data-free Quantization via Mixup-class Prompting
Jul 29, 2025
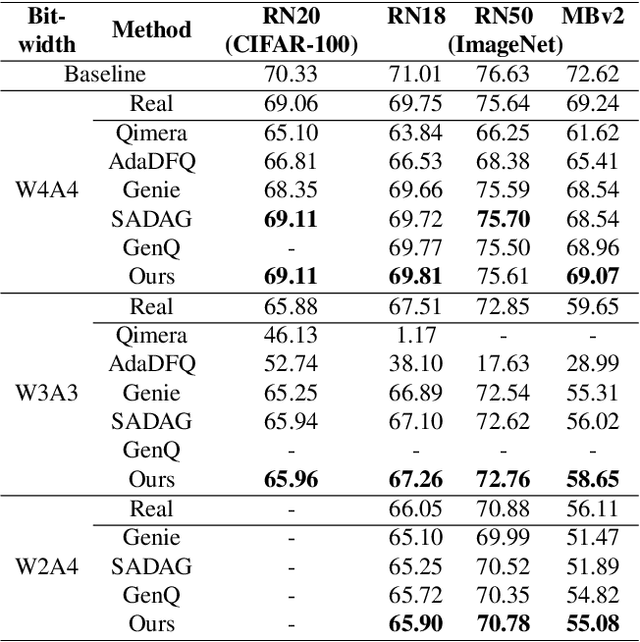
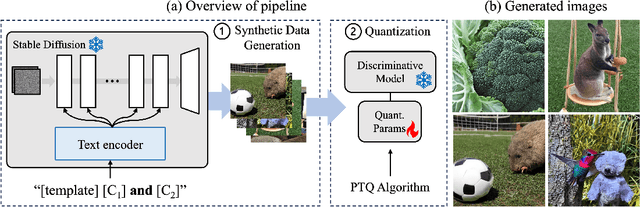
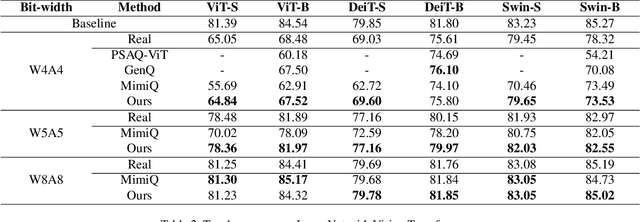
Post-training quantization (PTQ) improves efficiency but struggles with limited calibration data, especially under privacy constraints. Data-free quantization (DFQ) mitigates this by generating synthetic images using generative models such as generative adversarial networks (GANs) and text-conditioned latent diffusion models (LDMs), while applying existing PTQ algorithms. However, the relationship between generated synthetic images and the generalizability of the quantized model during PTQ remains underexplored. Without investigating this relationship, synthetic images generated by previous prompt engineering methods based on single-class prompts suffer from issues such as polysemy, leading to performance degradation. We propose \textbf{mixup-class prompt}, a mixup-based text prompting strategy that fuses multiple class labels at the text prompt level to generate diverse, robust synthetic data. This approach enhances generalization, and improves optimization stability in PTQ. We provide quantitative insights through gradient norm and generalization error analysis. Experiments on convolutional neural networks (CNNs) and vision transformers (ViTs) show that our method consistently outperforms state-of-the-art DFQ methods like GenQ. Furthermore, it pushes the performance boundary in extremely low-bit scenarios, achieving new state-of-the-art accuracy in challenging 2-bit weight, 4-bit activation (W2A4) quantization.
Sample-based Regularization: A Transfer Learning Strategy Toward Better Generalization
Jul 10, 2020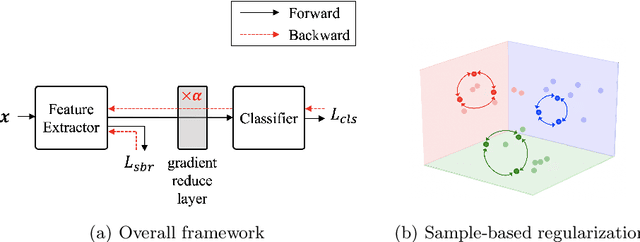
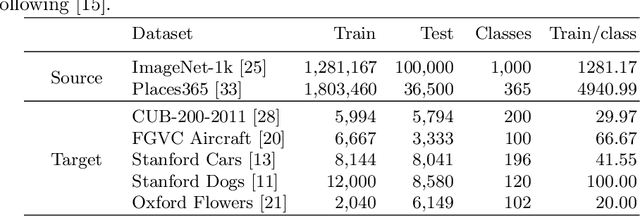
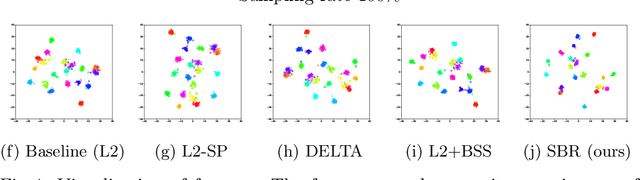
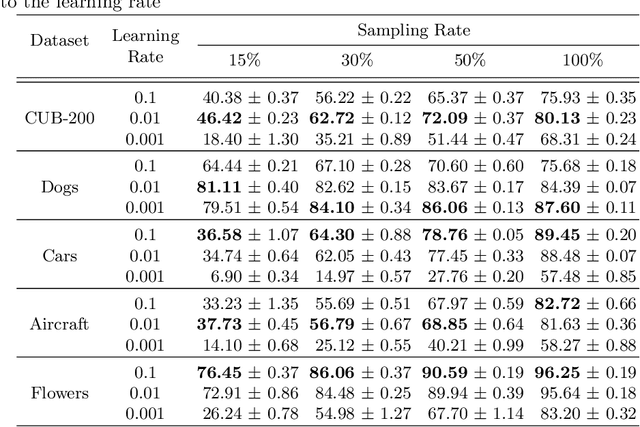
Training a deep neural network with a small amount of data is a challenging problem as it is vulnerable to overfitting. However, one of the practical difficulties that we often face is to collect many samples. Transfer learning is a cost-effective solution to this problem. By using the source model trained with a large-scale dataset, the target model can alleviate the overfitting originated from the lack of training data. Resorting to the ability of generalization of the source model, several methods proposed to use the source knowledge during the whole training procedure. However, this is likely to restrict the potential of the target model and some transferred knowledge from the source can interfere with the training procedure. For improving the generalization performance of the target model with a few training samples, we proposed a regularization method called sample-based regularization (SBR), which does not rely on the source's knowledge during training. With SBR, we suggested a new training framework for transfer learning. Experimental results showed that our framework outperformed existing methods in various configurations.
Multi-step Estimation for Gradient-based Meta-learning
Jun 08, 2020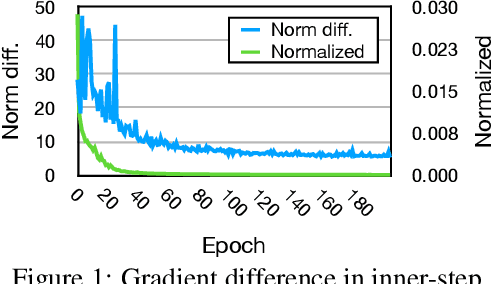

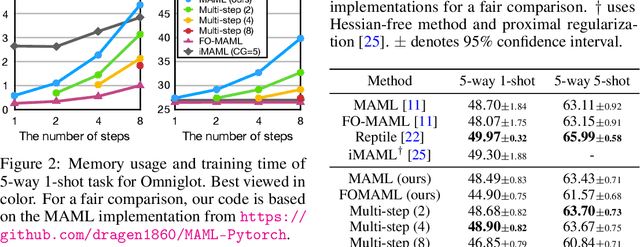

Gradient-based meta-learning approaches have been successful in few-shot learning, transfer learning, and a wide range of other domains. Despite its efficacy and simplicity, the burden of calculating the Hessian matrix with large memory footprints is the critical challenge in large-scale applications. To tackle this issue, we propose a simple yet straightforward method to reduce the cost by reusing the same gradient in a window of inner steps. We describe the dynamics of the multi-step estimation in the Lagrangian formalism and discuss how to reduce evaluating second-order derivatives estimating the dynamics. To validate our method, we experiment on meta-transfer learning and few-shot learning tasks for multiple settings. The experiment on meta-transfer emphasizes the applicability of training meta-networks, where other approximations are limited. For few-shot learning, we evaluate time and memory complexities compared with popular baselines. We show that our method significantly reduces training time and memory usage, maintaining competitive accuracies, or even outperforming in some cases.
Few-Shot Classification on Unseen Domains by Learning Disparate Modulators
Sep 11, 2019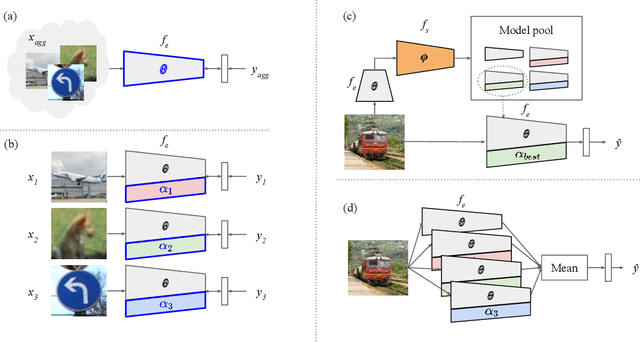
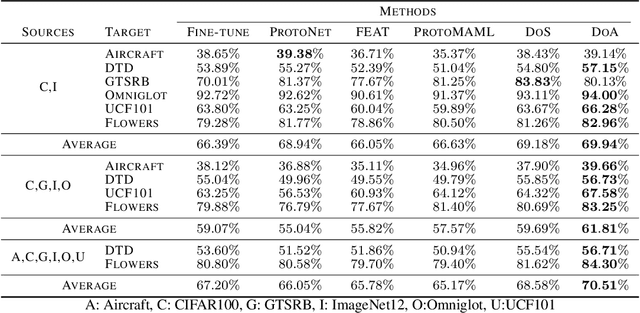
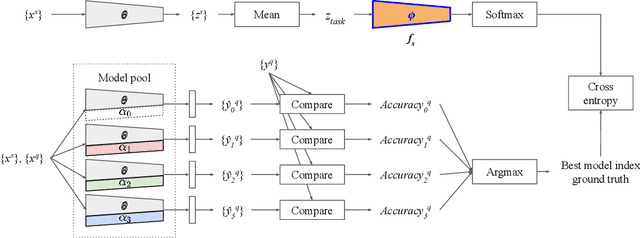
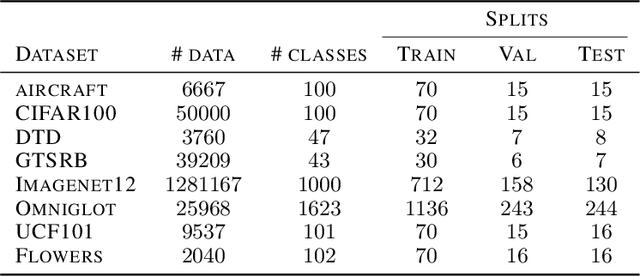
Although few-shot learning studies have advanced rapidly with the help of meta-learning, their practical applicability is still limited because most of them assumed that all meta-training and meta-testing examples came from the same domain. Leveraging meta-learning on multiple heterogeneous domains, we propose a few-shot classification method which adapts to novel domains as well as novel classes, which is believed to be more practical in the real world. To address this challenging problem, we start from building a pool of multiple embedding models. Inspired by multi-task learning techniques, we design each model to have its own per-layer modulator with a base network shared by others. This allows the pool to have representational diversity as a whole without losing beneficial domain-invariant features. Experimental results show that our framework can be utilized effectively for few-shot learning on unseen domains by learning to select the best model or averaging all models in the pool. Additionally, ours outperform previous methods in few-shot classification tasks on multiple seen domains.
Discriminative Few-Shot Learning Based on Directional Statistics
Jun 05, 2019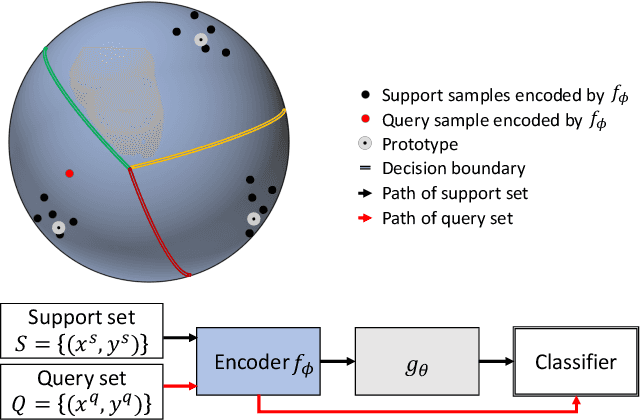

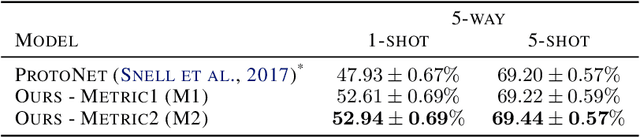
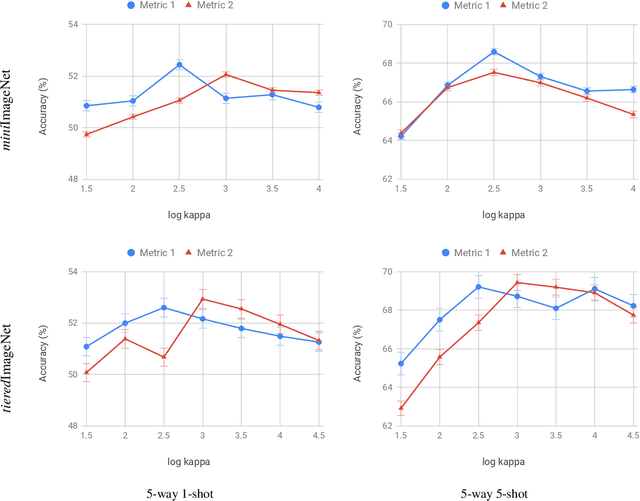
Metric-based few-shot learning methods try to overcome the difficulty due to the lack of training examples by learning embedding to make comparison easy. We propose a novel algorithm to generate class representatives for few-shot classification tasks. As a probabilistic model for learned features of inputs, we consider a mixture of von Mises-Fisher distributions which is known to be more expressive than Gaussian in a high dimensional space. Then, from a discriminative classifier perspective, we get a better class representative considering inter-class correlation which has not been addressed by conventional few-shot learning algorithms. We apply our method to \emph{mini}ImageNet and \emph{tiered}ImageNet datasets, and show that the proposed approach outperforms other comparable methods in few-shot classification tasks.
Doubly Nested Network for Resource-Efficient Inference
Jun 20, 2018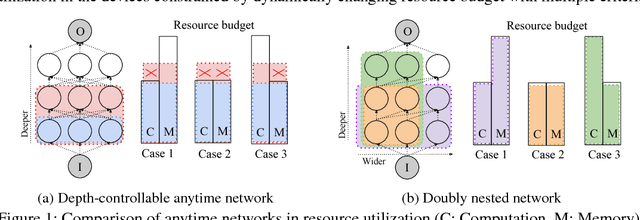
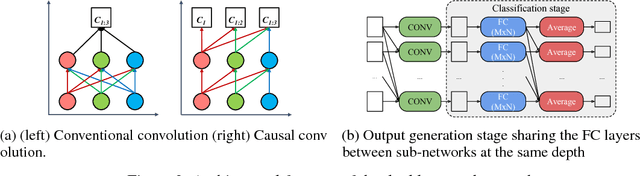
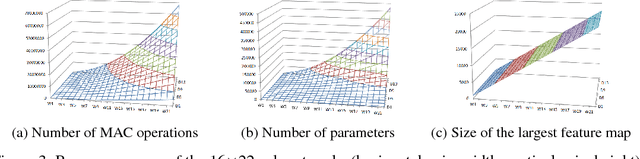
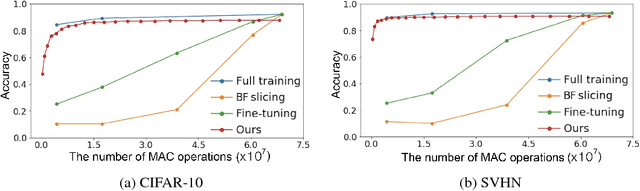
We propose doubly nested network(DNNet) where all neurons represent their own sub-models that solve the same task. Every sub-model is nested both layer-wise and channel-wise. While nesting sub-models layer-wise is straight-forward with deep-supervision as proposed in \cite{xie2015holistically}, channel-wise nesting has not been explored in the literature to our best knowledge. Channel-wise nesting is non-trivial as neurons between consecutive layers are all connected to each other. In this work, we introduce a technique to solve this problem by sorting channels topologically and connecting neurons accordingly. For the purpose, channel-causal convolutions are used. Slicing doubly nested network gives a working sub-network. The most notable application of our proposed network structure with slicing operation is resource-efficient inference. At test time, computing resources such as time and memory available for running the prediction algorithm can significantly vary across devices and applications. Given a budget constraint, we can slice the network accordingly and use a sub-model for inference within budget, requiring no additional computation such as training or fine-tuning after deployment. We demonstrate the effectiveness of our approach in several practical scenarios of utilizing available resource efficiently.
Auto-Meta: Automated Gradient Based Meta Learner Search
Jun 11, 2018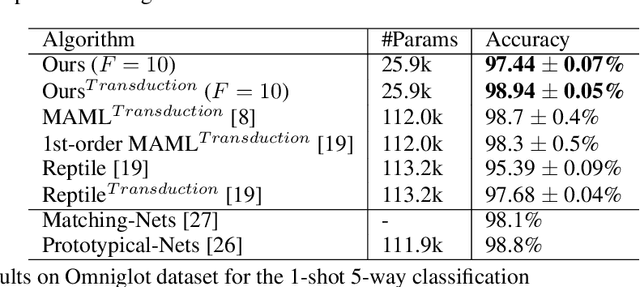
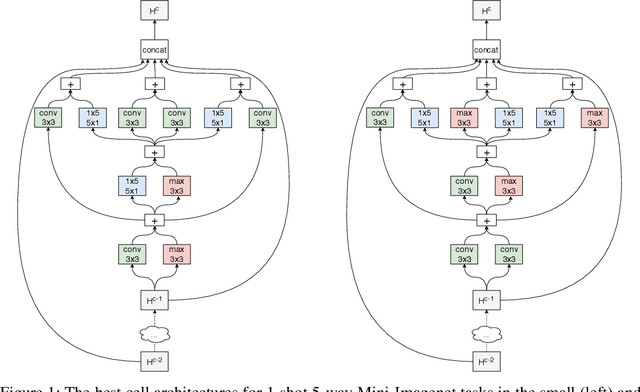
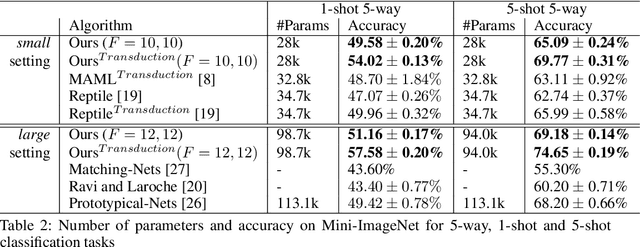
Fully automating machine learning pipeline is one of the outstanding challenges of general artificial intelligence, as practical machine learning often requires costly human driven process, such as hyper-parameter tuning, algorithmic selection, and model selection. In this work, we consider the problem of executing automated, yet scalable search for finding optimal gradient based meta-learners in practice. As a solution, we apply progressive neural architecture search to proto-architectures by appealing to the model agnostic nature of general gradient based meta learners. In the presence of recent universality result of Finn \textit{et al.}\cite{finn:universality_maml:DBLP:/journals/corr/abs-1710-11622}, our search is a priori motivated in that neural network architecture search dynamics---automated or not---may be quite different from that of the classical setting with the same target tasks, due to the presence of the gradient update operator. A posteriori, our search algorithm, given appropriately designed search spaces, finds gradient based meta learners with non-intuitive proto-architectures that are narrowly deep, unlike the inception-like structures previously observed in the resulting architectures of traditional NAS algorithms. Along with these notable findings, the searched gradient based meta-learner achieves state-of-the-art results on the few shot classification problem on Mini-ImageNet with $76.29\%$ accuracy, which is an $13.18\%$ improvement over results reported in the original MAML paper. To our best knowledge, this work is the first successful AutoML implementation in the context of meta learning.