 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Auto-Meta: Automated Gradient Based Meta Learner Search
Jun 11, 2018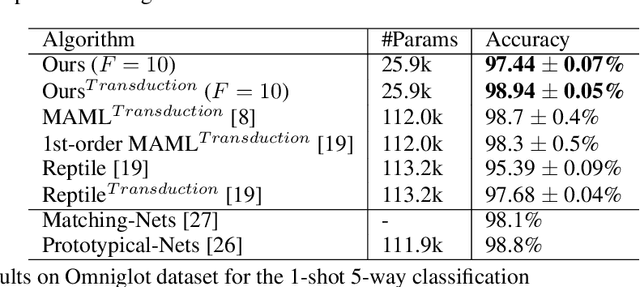
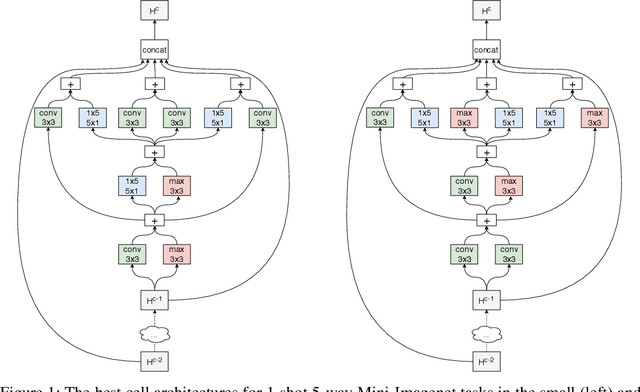
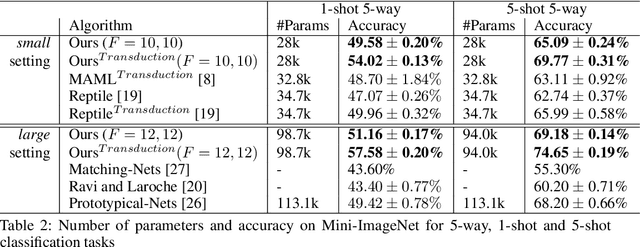
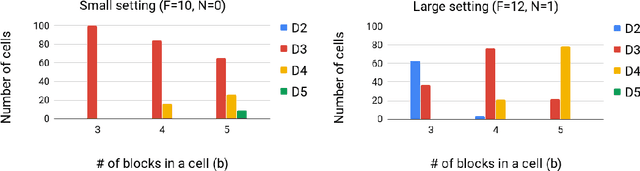
Fully automating machine learning pipeline is one of the outstanding challenges of general artificial intelligence, as practical machine learning often requires costly human driven process, such as hyper-parameter tuning, algorithmic selection, and model selection. In this work, we consider the problem of executing automated, yet scalable search for finding optimal gradient based meta-learners in practice. As a solution, we apply progressive neural architecture search to proto-architectures by appealing to the model agnostic nature of general gradient based meta learners. In the presence of recent universality result of Finn \textit{et al.}\cite{finn:universality_maml:DBLP:/journals/corr/abs-1710-11622}, our search is a priori motivated in that neural network architecture search dynamics---automated or not---may be quite different from that of the classical setting with the same target tasks, due to the presence of the gradient update operator. A posteriori, our search algorithm, given appropriately designed search spaces, finds gradient based meta learners with non-intuitive proto-architectures that are narrowly deep, unlike the inception-like structures previously observed in the resulting architectures of traditional NAS algorithms. Along with these notable findings, the searched gradient based meta-learner achieves state-of-the-art results on the few shot classification problem on Mini-ImageNet with $76.29\%$ accuracy, which is an $13.18\%$ improvement over results reported in the original MAML paper. To our best knowledge, this work is the first successful AutoML implementation in the context of meta learning.