 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Rethinking Caching for LLM Serving Systems: Beyond Traditional Heuristics
Aug 26, 2025Serving Large Language Models (LLMs) at scale requires meeting strict Service Level Objectives (SLOs) under severe computational and memory constraints. Nevertheless, traditional caching strategies fall short: exact-matching and prefix caches neglect query semantics, while state-of-the-art semantic caches remain confined to traditional intuitions, offering little conceptual departure. Building on this, we present SISO, a semantic caching system that redefines efficiency for LLM serving. SISO introduces centroid-based caching to maximize coverage with minimal memory, locality-aware replacement to preserve high-value entries, and dynamic thresholding to balance accuracy and latency under varying workloads. Across diverse datasets, SISO delivers up to 1.71$\times$ higher hit ratios and consistently stronger SLO attainment compared to state-of-the-art systems.
SeDi-Instruct: Enhancing Alignment of Language Models through Self-Directed Instruction Generation
Feb 07, 2025The rapid evolution of Large Language Models (LLMs) has enabled the industry to develop various AI-based services. Instruction tuning is considered essential in adapting foundation models for target domains to provide high-quality services to customers. A key challenge in instruction tuning is obtaining high-quality instruction data. Self-Instruct, which automatically generates instruction data using ChatGPT APIs, alleviates the data scarcity problem. To improve the quality of instruction data, Self-Instruct discards many of the instructions generated from ChatGPT, even though it is inefficient in terms of cost owing to many useless API calls. To generate high-quality instruction data at a low cost, we propose a novel data generation framework, Self-Direct Instruction generation (SeDi-Instruct), which employs diversity-based filtering and iterative feedback task generation. Diversity-based filtering maintains model accuracy without excessively discarding low-quality generated instructions by enhancing the diversity of instructions in a batch. This reduces the cost of synthesizing instruction data. The iterative feedback task generation integrates instruction generation and training tasks and utilizes information obtained during the training to create high-quality instruction sets. Our results show that SeDi-Instruct enhances the accuracy of AI models by 5.2%, compared with traditional methods, while reducing data generation costs by 36%.
Syntriever: How to Train Your Retriever with Synthetic Data from LLMs
Feb 06, 2025



LLMs have boosted progress in many AI applications. Recently, there were attempts to distill the vast knowledge of LLMs into information retrieval systems. Those distillation methods mostly use output probabilities of LLMs which are unavailable in the latest black-box LLMs. We propose Syntriever, a training framework for retrievers using synthetic data from black-box LLMs. Syntriever consists of two stages. Firstly in the distillation stage, we synthesize relevant and plausibly irrelevant passages and augmented queries using chain-of-thoughts for the given queries. LLM is asked to self-verify the synthetic data for possible hallucinations, after which retrievers are trained with a loss designed to cluster the embeddings of relevant passages. Secondly in the alignment stage, we align the retriever with the preferences of LLMs. We propose a preference modeling called partial Plackett-Luce ranking to learn LLM preferences with regularization which prevents the model from deviating excessively from that trained in the distillation stage. Experiments show that Syntriever achieves state-of-the-art performances on benchmark datasets from various domains in nDCG@$K$. The code is available at \href{https://github.com/kmswin1/Syntriever}{https://github.com/kmswin1/Syntriever}.
Exploring Large Language Models on Cross-Cultural Values in Connection with Training Methodology
Dec 12, 2024

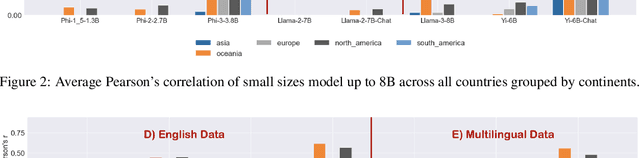

Large language models (LLMs) closely interact with humans, and thus need an intimate understanding of the cultural values of human society. In this paper, we explore how open-source LLMs make judgments on diverse categories of cultural values across countries, and its relation to training methodology such as model sizes, training corpus, alignment, etc. Our analysis shows that LLMs can judge socio-cultural norms similar to humans but less so on social systems and progress. In addition, LLMs tend to judge cultural values biased toward Western culture, which can be improved with training on the multilingual corpus. We also find that increasing model size helps a better understanding of social values, but smaller models can be enhanced by using synthetic data. Our analysis reveals valuable insights into the design methodology of LLMs in connection with their understanding of cultural values.
Augmenting Query and Passage for Retrieval-Augmented Generation using LLMs for Open-Domain Question Answering
Jun 20, 2024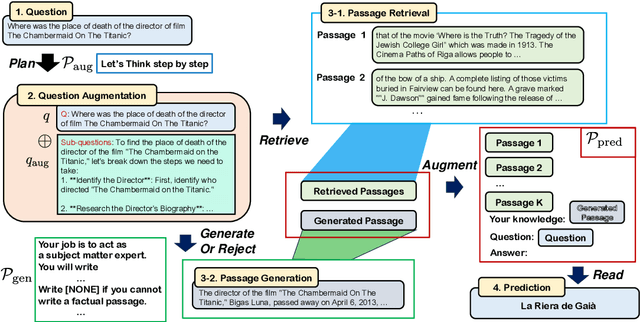
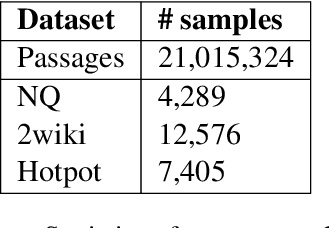
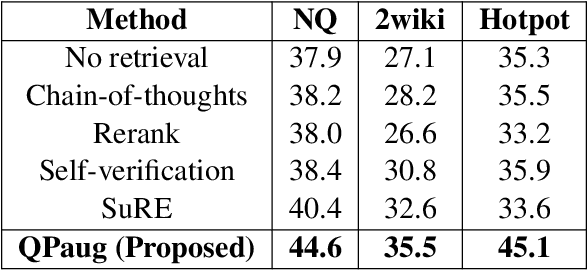
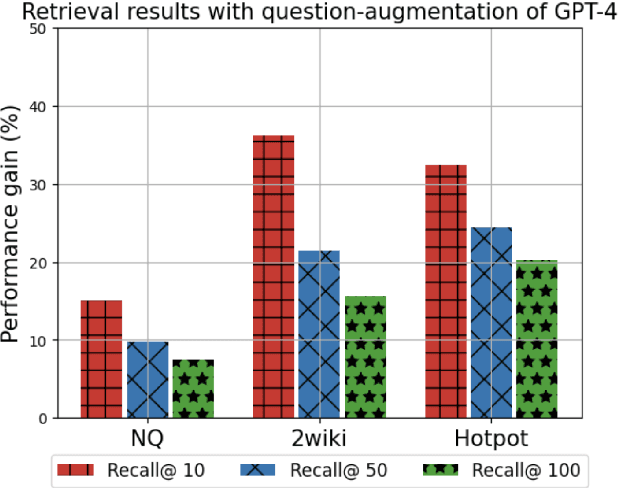
Retrieval-augmented generation (RAG) has received much attention for Open-domain question-answering (ODQA) tasks as a means to compensate for the parametric knowledge of large language models (LLMs). While previous approaches focused on processing retrieved passages to remove irrelevant context, they still rely heavily on the quality of retrieved passages which can degrade if the question is ambiguous or complex. In this paper, we propose a simple yet efficient method called question and passage augmentation via LLMs for open-domain QA. Our method first decomposes the original questions into multiple-step sub-questions. By augmenting the original question with detailed sub-questions and planning, we are able to make the query more specific on what needs to be retrieved, improving the retrieval performance. In addition, to compensate for the case where the retrieved passages contain distracting information or divided opinions, we augment the retrieved passages with self-generated passages by LLMs to guide the answer extraction. Experimental results show that the proposed scheme outperforms the previous state-of-the-art and achieves significant performance gain over existing RAG methods.
Measuring Sample Importance in Data Pruning for Training LLMs from a Data Compression Perspective
Jun 20, 2024



Compute-efficient training of large language models (LLMs) has become an important research problem. In this work, we consider data pruning as a method of data-efficient training of LLMs, where we take a data compression view on data pruning. We argue that the amount of information of a sample, or the achievable compression on its description length, represents its sample importance. The key idea is that, less informative samples are likely to contain redundant information, and thus should be pruned first. We leverage log-likelihood function of trained models as a surrogate to measure information content of samples. Experiments reveal a surprising insight that information-based pruning can enhance the generalization capability of the model, improves upon language modeling and downstream tasks as compared to the model trained on the entire dataset.
Hierarchical Position Embedding of Graphs with Landmarks and Clustering for Link Prediction
Feb 13, 2024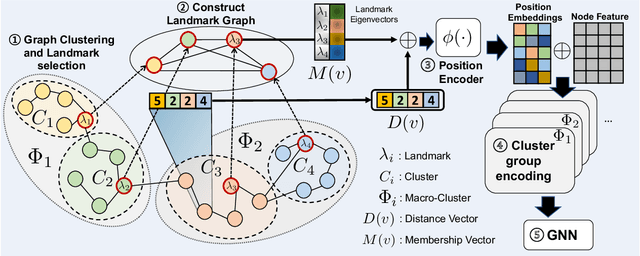



Learning positional information of nodes in a graph is important for link prediction tasks. We propose a representation of positional information using representative nodes called landmarks. A small number of nodes with high degree centrality are selected as landmarks, which serve as reference points for the nodes' positions. We justify this selection strategy for well-known random graph models and derive closed-form bounds on the average path lengths involving landmarks. In a model for power-law graphs, we prove that landmarks provide asymptotically exact information on inter-node distances. We apply theoretical insights to practical networks and propose Hierarchical Position embedding with Landmarks and Clustering (HPLC). HPLC combines landmark selection and graph clustering, where the graph is partitioned into densely connected clusters in which nodes with the highest degree are selected as landmarks. HPLC leverages the positional information of nodes based on landmarks at various levels of hierarchy such as nodes' distances to landmarks, inter-landmark distances and hierarchical grouping of clusters. Experiments show that HPLC achieves state-of-the-art performances of link prediction on various datasets in terms of HIT@K, MRR, and AUC. The code is available at \url{https://github.com/kmswin1/HPLC}.
ComDensE : Combined Dense Embedding of Relation-aware and Common Features for Knowledge Graph Completion
Jun 29, 2022


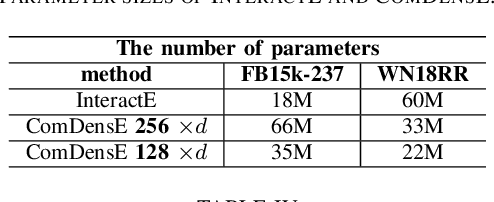
Real-world knowledge graphs (KG) are mostly incomplete. The problem of recovering missing relations, called KG completion, has recently become an active research area. Knowledge graph (KG) embedding, a low-dimensional representation of entities and relations, is the crucial technique for KG completion. Convolutional neural networks in models such as ConvE, SACN, InteractE, and RGCN achieve recent successes. This paper takes a different architectural view and proposes ComDensE which combines relation-aware and common features using dense neural networks. In the relation-aware feature extraction, we attempt to create relational inductive bias by applying an encoding function specific to each relation. In the common feature extraction, we apply the common encoding function to all input embeddings. These encoding functions are implemented using dense layers in ComDensE. ComDensE achieves the state-of-the-art performance in the link prediction in terms of MRR, HIT@1 on FB15k-237 and HIT@1 on WN18RR compared to the previous baseline approaches. We conduct an extensive ablation study to examine the effects of the relation-aware layer and the common layer of the ComDensE. Experimental results illustrate that the combined dense architecture as implemented in ComDensE achieves the best performance.