 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELO: Efficient Layer-Specific Optimization for Continual Pretraining of Multilingual LLMs
Jan 07, 2026We propose an efficient layer-specific optimization (ELO) method designed to enhance continual pretraining (CP) for specific languages in multilingual large language models (MLLMs). This approach addresses the common challenges of high computational cost and degradation of source language performance associated with traditional CP. The ELO method consists of two main stages: (1) ELO Pretraining, where a small subset of specific layers, identified in our experiments as the critically important first and last layers, are detached from the original MLLM and trained with the target language. This significantly reduces not only the number of trainable parameters but also the total parameters computed during the forward pass, minimizing GPU memory consumption and accelerating the training process. (2) Layer Alignment, where the newly trained layers are reintegrated into the original model, followed by a brief full fine-tuning step on a small dataset to align the parameters. Experimental results demonstrate that the ELO method achieves a training speedup of up to 6.46 times compared to existing methods, while improving target language performance by up to 6.2\% on qualitative benchmarks and effectively preserving source language (English) capabilities.
ScholarBench: A Bilingual Benchmark for Abstraction, Comprehension, and Reasoning Evaluation in Academic Contexts
May 22, 2025



Prior benchmarks for evaluating the domain-specific knowledge of large language models (LLMs) lack the scalability to handle complex academic tasks. To address this, we introduce \texttt{ScholarBench}, a benchmark centered on deep expert knowledge and complex academic problem-solving, which evaluates the academic reasoning ability of LLMs and is constructed through a three-step process. \texttt{ScholarBench} targets more specialized and logically complex contexts derived from academic literature, encompassing five distinct problem types. Unlike prior benchmarks, \texttt{ScholarBench} evaluates the abstraction, comprehension, and reasoning capabilities of LLMs across eight distinct research domains. To ensure high-quality evaluation data, we define category-specific example attributes and design questions that are aligned with the characteristic research methodologies and discourse structures of each domain. Additionally, this benchmark operates as an English-Korean bilingual dataset, facilitating simultaneous evaluation for linguistic capabilities of LLMs in both languages. The benchmark comprises 5,031 examples in Korean and 5,309 in English, with even state-of-the-art models like o3-mini achieving an average evaluation score of only 0.543, demonstrating the challenging nature of this benchmark.
Augmenting Query and Passage for Retrieval-Augmented Generation using LLMs for Open-Domain Question Answering
Jun 20, 2024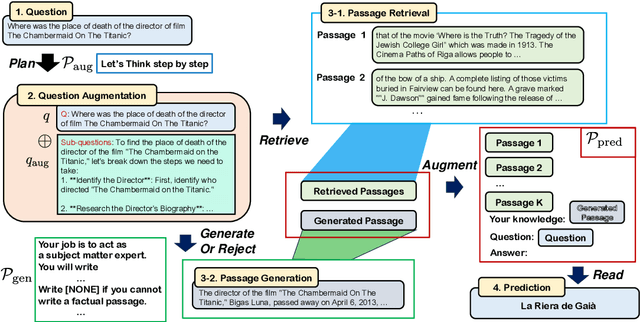
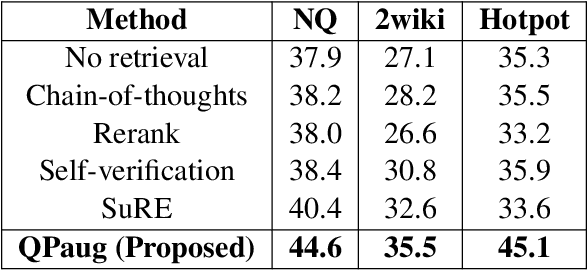
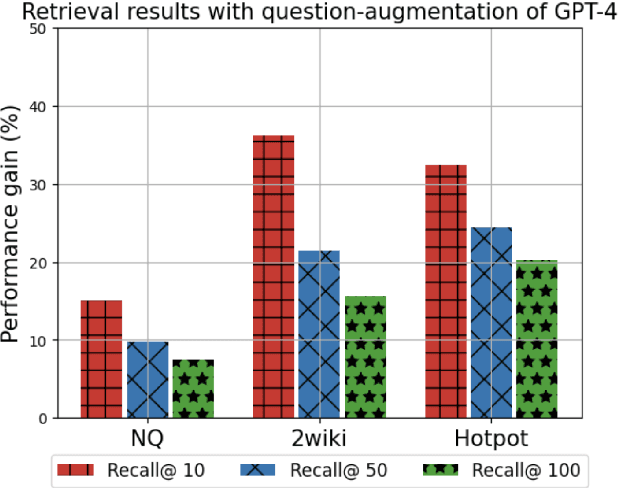
Retrieval-augmented generation (RAG) has received much attention for Open-domain question-answering (ODQA) tasks as a means to compensate for the parametric knowledge of large language models (LLMs). While previous approaches focused on processing retrieved passages to remove irrelevant context, they still rely heavily on the quality of retrieved passages which can degrade if the question is ambiguous or complex. In this paper, we propose a simple yet efficient method called question and passage augmentation via LLMs for open-domain QA. Our method first decomposes the original questions into multiple-step sub-questions. By augmenting the original question with detailed sub-questions and planning, we are able to make the query more specific on what needs to be retrieved, improving the retrieval performance. In addition, to compensate for the case where the retrieved passages contain distracting information or divided opinions, we augment the retrieved passages with self-generated passages by LLMs to guide the answer extraction. Experimental results show that the proposed scheme outperforms the previous state-of-the-art and achieves significant performance gain over existing RAG methods.
Factual Error Correction for Abstractive Summaries Using Entity Retrieval
Apr 18, 2022
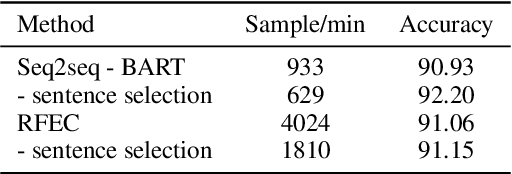
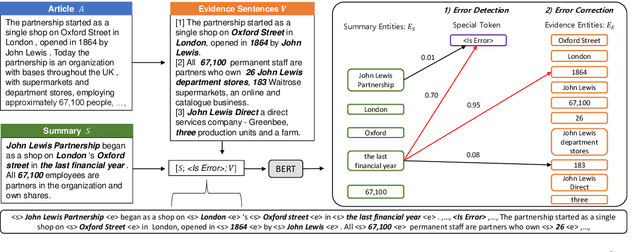
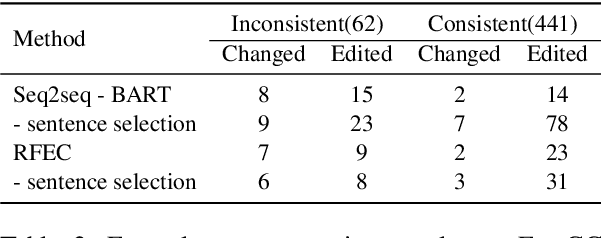
Despite the recent advancements in abstractive summarization systems leveraged from large-scale datasets and pre-trained language models, the factual correctness of the summary is still insufficient. One line of trials to mitigate this problem is to include a post-editing process that can detect and correct factual errors in the summary. In building such a post-editing system, it is strongly required that 1) the process has a high success rate and interpretability and 2) has a fast running time. Previous approaches focus on regeneration of the summary using the autoregressive models, which lack interpretability and require high computing resources. In this paper, we propose an efficient factual error correction system RFEC based on entities retrieval post-editing process. RFEC first retrieves the evidence sentences from the original document by comparing the sentences with the target summary. This approach greatly reduces the length of text for a system to analyze. Next, RFEC detects the entity-level errors in the summaries by considering the evidence sentences and substitutes the wrong entities with the accurate entities from the evidence sentences. Experimental results show that our proposed error correction system shows more competitive performance than baseline methods in correcting the factual errors with a much faster speed.
CrossAug: A Contrastive Data Augmentation Method for Debiasing Fact Verification Models
Sep 30, 2021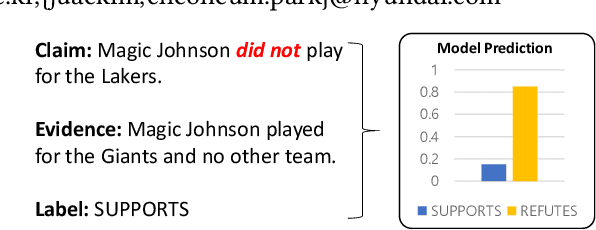
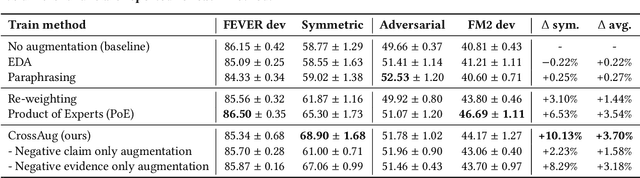
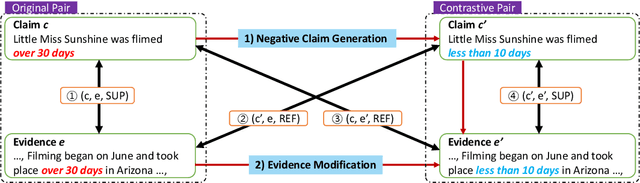
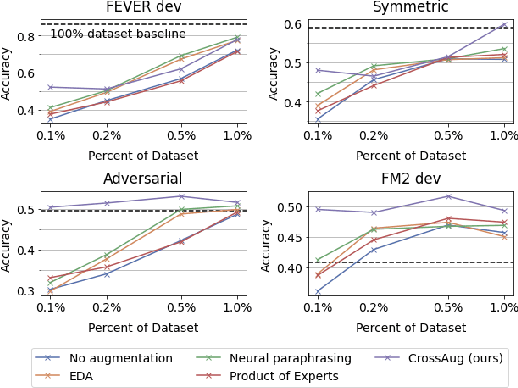
Fact verification datasets are typically constructed using crowdsourcing techniques due to the lack of text sources with veracity labels. However, the crowdsourcing process often produces undesired biases in data that cause models to learn spurious patterns. In this paper, we propose CrossAug, a contrastive data augmentation method for debiasing fact verification models. Specifically, we employ a two-stage augmentation pipeline to generate new claims and evidences from existing samples. The generated samples are then paired cross-wise with the original pair, forming contrastive samples that facilitate the model to rely less on spurious patterns and learn more robust representations. Experimental results show that our method outperforms the previous state-of-the-art debiasing technique by 3.6% on the debiased extension of the FEVER dataset, with a total performance boost of 10.13% from the baseline. Furthermore, we evaluate our approach in data-scarce settings, where models can be more susceptible to biases due to the lack of training data. Experimental results demonstrate that our approach is also effective at debiasing in these low-resource conditions, exceeding the baseline performance on the Symmetric dataset with just 1% of the original data.
ThisIsCompetition at SemEval-2019 Task 9: BERT is unstable for out-of-domain samples
Apr 06, 2019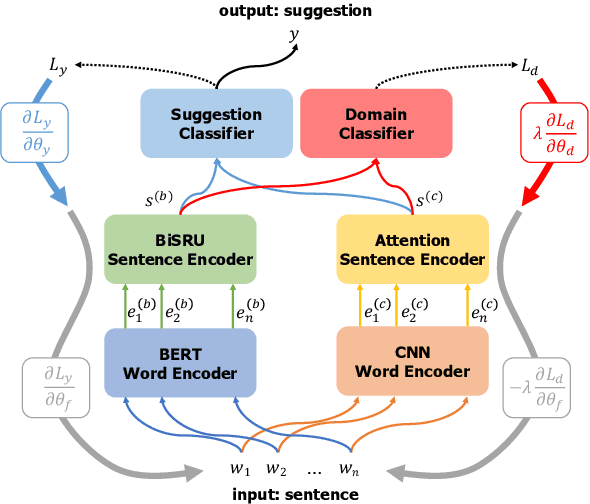
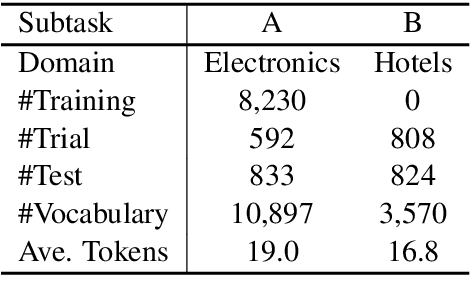
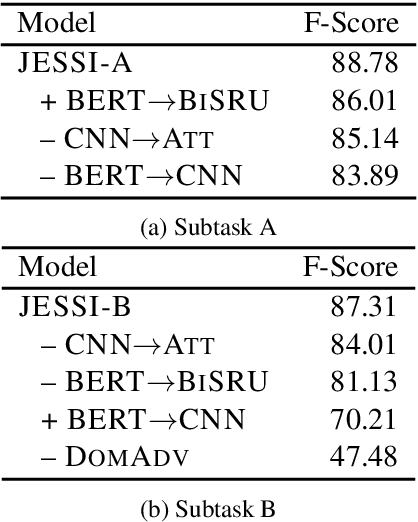
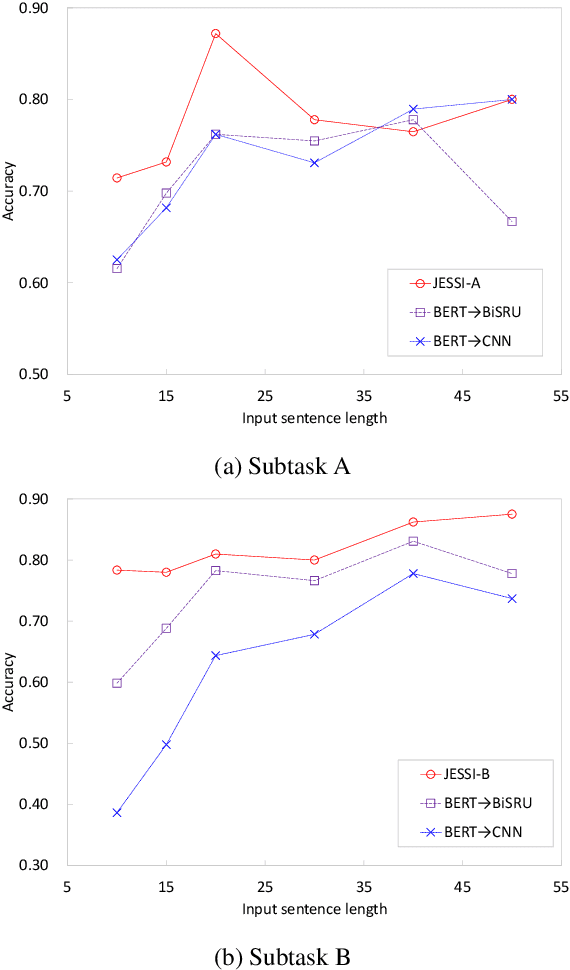
This paper describes our system, Joint Encoders for Stable Suggestion Inference (JESSI), for the SemEval 2019 Task 9: Suggestion Mining from Online Reviews and Forums. JESSI is a combination of two sentence encoders: (a) one using multiple pre-trained word embeddings learned from log-bilinear regression (GloVe) and translation (CoVe) models, and (b) one on top of word encodings from a pre-trained deep bidirectional transformer (BERT). We include a domain adversarial training module when training for out-of-domain samples. Our experiments show that while BERT performs exceptionally well for in-domain samples, several runs of the model show that it is unstable for out-of-domain samples. The problem is mitigated tremendously by (1) combining BERT with a non-BERT encoder, and (2) using an RNN-based classifier on top of BERT. Our final models obtained second place with 77.78\% F-Score on Subtask A (i.e. in-domain) and achieved an F-Score of 79.59\% on Subtask B (i.e. out-of-domain), even without using any additional external data.