 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossAug: A Contrastive Data Augmentation Method for Debiasing Fact Verification Models
Paper and Code
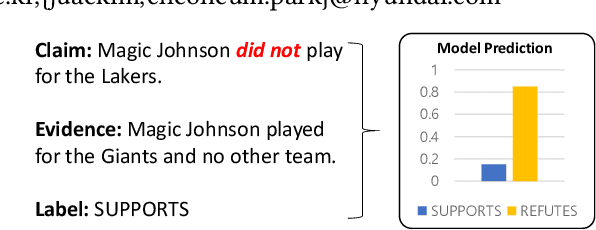
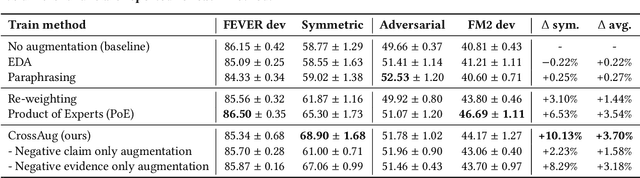
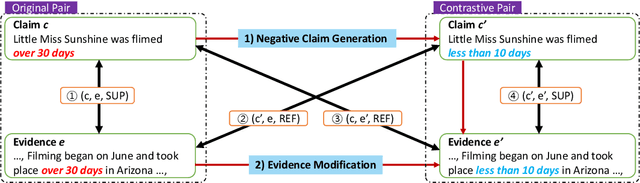
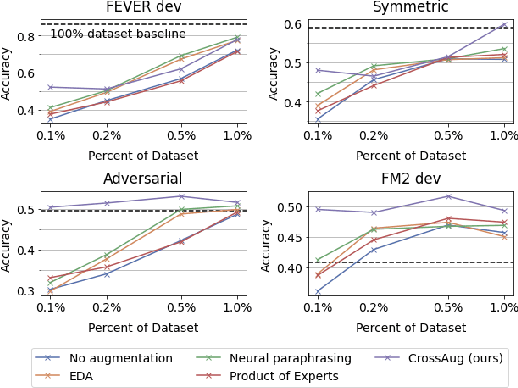
Fact verification datasets are typically constructed using crowdsourcing techniques due to the lack of text sources with veracity labels. However, the crowdsourcing process often produces undesired biases in data that cause models to learn spurious patterns. In this paper, we propose CrossAug, a contrastive data augmentation method for debiasing fact verification models. Specifically, we employ a two-stage augmentation pipeline to generate new claims and evidences from existing samples. The generated samples are then paired cross-wise with the original pair, forming contrastive samples that facilitate the model to rely less on spurious patterns and learn more robust representations. Experimental results show that our method outperforms the previous state-of-the-art debiasing technique by 3.6% on the debiased extension of the FEVER dataset, with a total performance boost of 10.13% from the baseline. Furthermore, we evaluate our approach in data-scarce settings, where models can be more susceptible to biases due to the lack of training data. Experimental results demonstrate that our approach is also effective at debiasing in these low-resource conditions, exceeding the baseline performance on the Symmetric dataset with just 1% of the original data.