 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Pre-Sampling Barrier: Activation-Informed Difficulty-Aware Self-Consistency
Feb 10, 2026Self-Consistency (SC) is an effective decoding strategy that improves the reasoning performance of Large Language Models (LLMs) by generating multiple chain-of-thought reasoning paths and selecting the final answer via majority voting. However, it suffers from substantial inference costs because it requires a large number of samples. To mitigate this issue, Difficulty-Adaptive Self-Consistency (DSC) was proposed to reduce unnecessary token usage for easy problems by adjusting the number of samples according to problem difficulty. However, DSC requires additional model calls and pre-sampling to estimate difficulty, and this process is repeated when applying to each dataset, leading to significant computational overhead. In this work, we propose Activation-Informed Difficulty-Aware Self-Consistency (ACTSC) to address these limitations. ACTSC leverages internal difficulty signals reflected in the feed-forward network neuron activations to construct a lightweight difficulty estimation probe, without any additional token generation or model calls. The probe dynamically adjusts the number of samples for SC and can be applied to new datasets without requiring pre-sampling for difficulty estimation. To validate its effectiveness, we conduct experiments on five benchmarks. Experimental results show that ACTSC effectively reduces inference costs while maintaining accuracy relative to existing methods.
Transcending Traditional Boundaries: Leveraging Inter-Annotator Agreement (IAA) for Enhancing Data Management Operations (DMOps)
Jun 26, 2023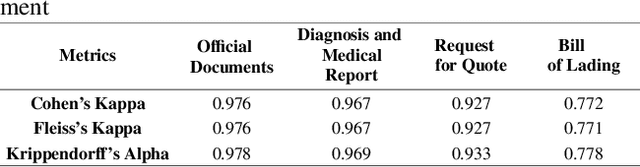
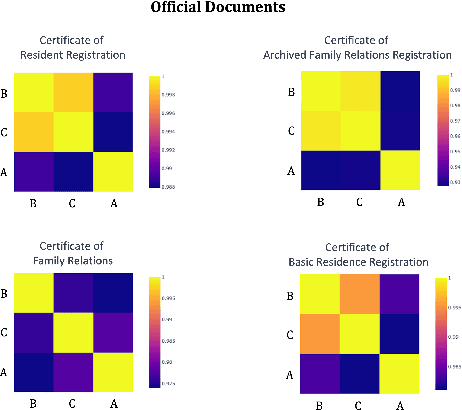
This paper presents a novel approach of leveraging Inter-Annotator Agreement (IAA), traditionally used for assessing labeling consistency, to optimize Data Management Operations (DMOps). We advocate for the use of IAA in predicting the labeling quality of individual annotators, leading to cost and time efficiency in data production. Additionally, our work highlights the potential of IAA in forecasting document difficulty, thereby boosting the data construction process's overall efficiency. This research underscores IAA's broader application potential in data-driven research optimization and holds significant implications for large-scale data projects prioritizing efficiency, cost reduction, and high-quality data.
Improving Sentence-Level Relation Extraction through Curriculum Learning
Aug 04, 2021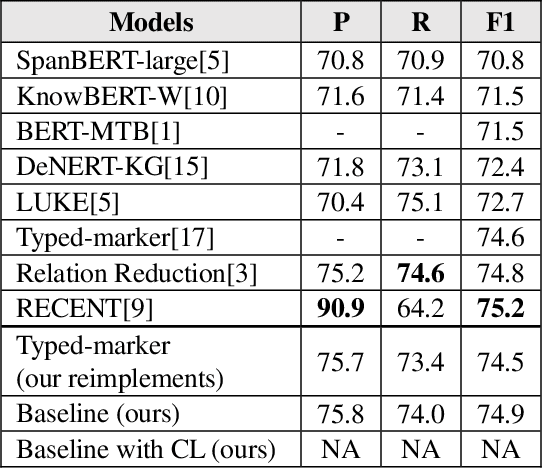
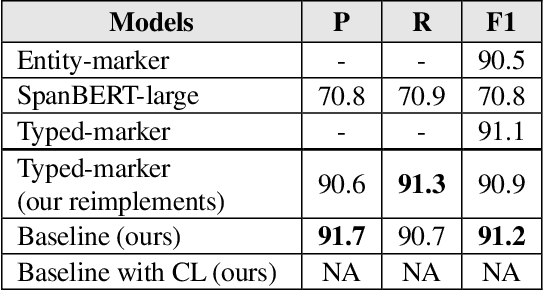
Sentence-level relation extraction mainly aims to classify the relation between two entities in a sentence. The sentence-level relation extraction corpus often contains data that are difficult for the model to infer or noise data. In this paper, we propose a curriculum learning-based relation extraction model that splits data by difficulty and utilizes them for learning. In the experiments with the representative sentence-level relation extraction datasets, TACRED and Re-TACRED, the proposed method obtained an F1-score of 75.0% and 91.4% respectively, which are the state-of-the-art performance.
Deep Context- and Relation-Aware Learning for Aspect-based Sentiment Analysis
Jun 07, 2021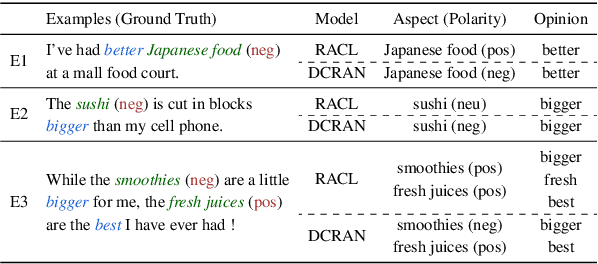
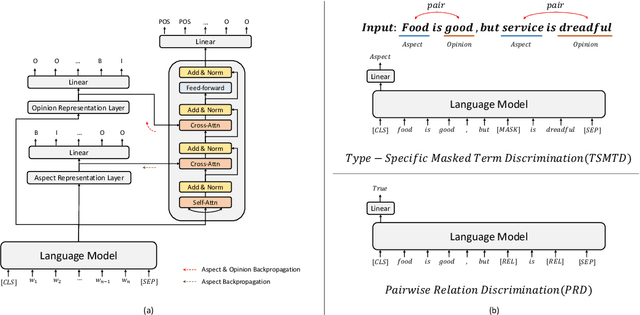
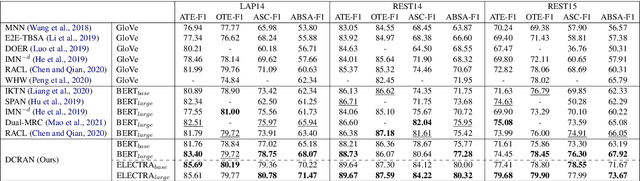
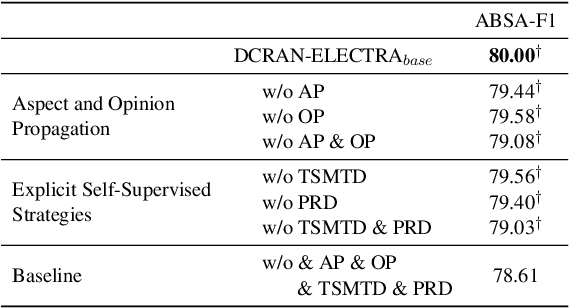
Existing works for aspect-based sentiment analysis (ABSA) have adopted a unified approach, which allows the interactive relations among subtasks. However, we observe that these methods tend to predict polarities based on the literal meaning of aspect and opinion terms and mainly consider relations implicitly among subtasks at the word level. In addition, identifying multiple aspect-opinion pairs with their polarities is much more challenging. Therefore, a comprehensive understanding of contextual information w.r.t. the aspect and opinion are further required in ABSA. In this paper, we propose Deep Contextualized Relation-Aware Network (DCRAN), which allows interactive relations among subtasks with deep contextual information based on two modules (i.e., Aspect and Opinion Propagation and Explicit Self-Supervised Strategies). Especially, we design novel self-supervised strategies for ABSA, which have strengths in dealing with multiple aspects. Experimental results show that DCRAN significantly outperforms previous state-of-the-art methods by large margins on three widely used benchmarks.
Grammar Accuracy Evaluation (GAE): Quantifiable Intrinsic Evaluation of Machine Translation Models
Jun 01, 2021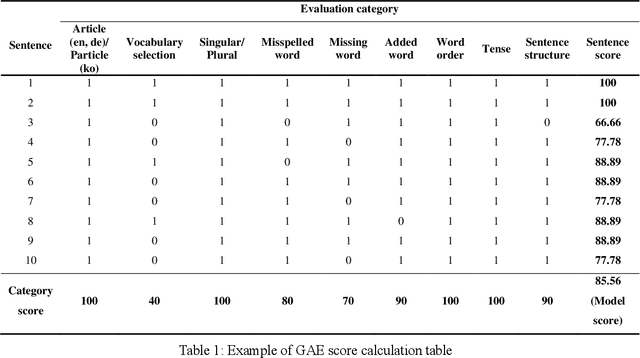
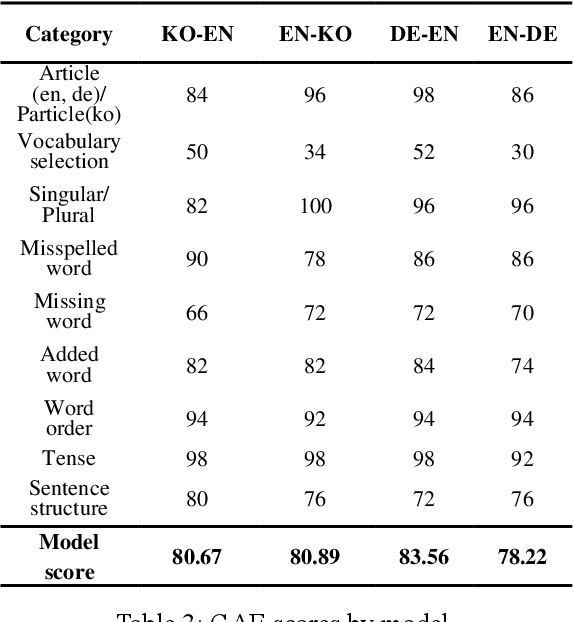

Intrinsic evaluation by humans for the performance of natural language generation models is conducted to overcome the fact that the quality of generated sentences cannot be fully represented by only extrinsic evaluation. Nevertheless, existing intrinsic evaluations have a large score deviation according to the evaluator's criteria. In this paper, we propose Grammar Accuracy Evaluation (GAE) that can provide specific evaluating criteria. As a result of analyzing the quality of machine translation by BLEU and GAE, it was confirmed that the BLEU score does not represent the absolute performance of machine translation models and that GAE compensates for the shortcomings of BLEU with a flexible evaluation on alternative synonyms and changes in sentence structure.
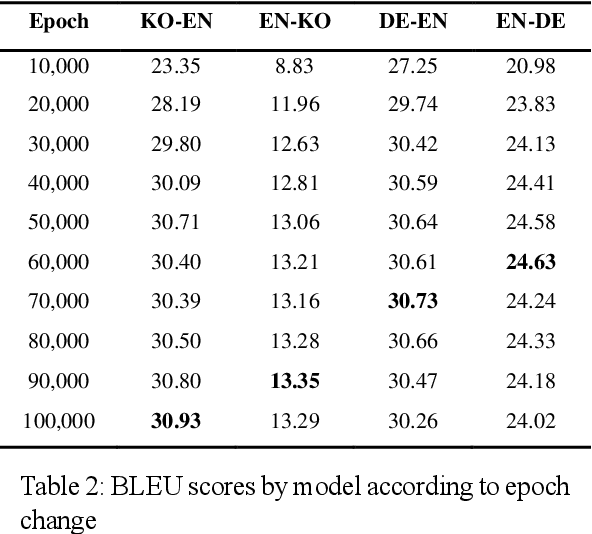
Korean-English Machine Translation with Multiple Tokenization Strategy
Jun 01, 2021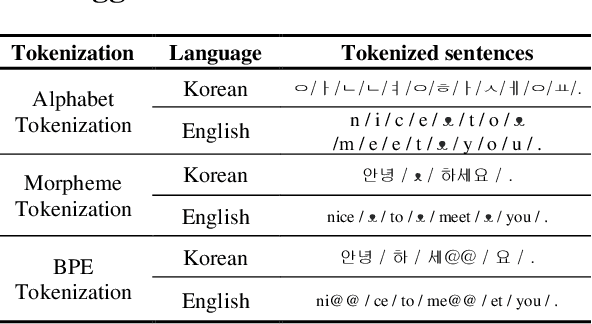
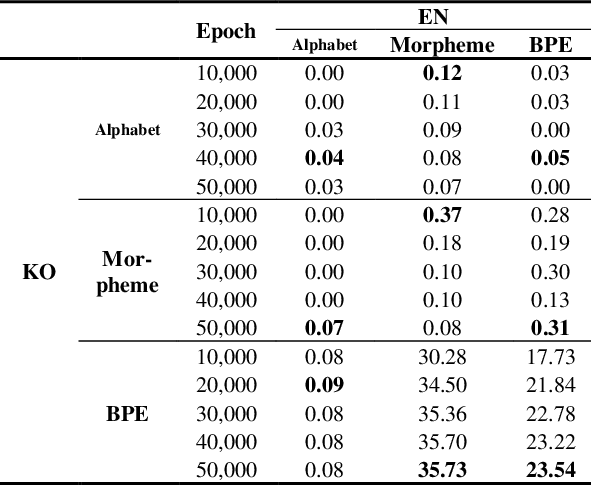
This work was conducted to find out how tokenization methods affect the training results of machine translation models. In this work, alphabet tokenization, morpheme tokenization, and BPE tokenization were applied to Korean as the source language and English as the target language respectively, and the comparison experiment was conducted by repeating 50,000 epochs of each 9 models using the Transformer neural network. As a result of measuring the BLEU scores of the experimental models, the model that applied BPE tokenization to Korean and morpheme tokenization to English recorded 35.73, showing the best performance.
Improving Document-Level Sentiment Classification Using Importance of Sentences
Mar 09, 2021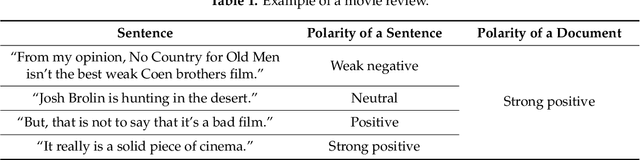
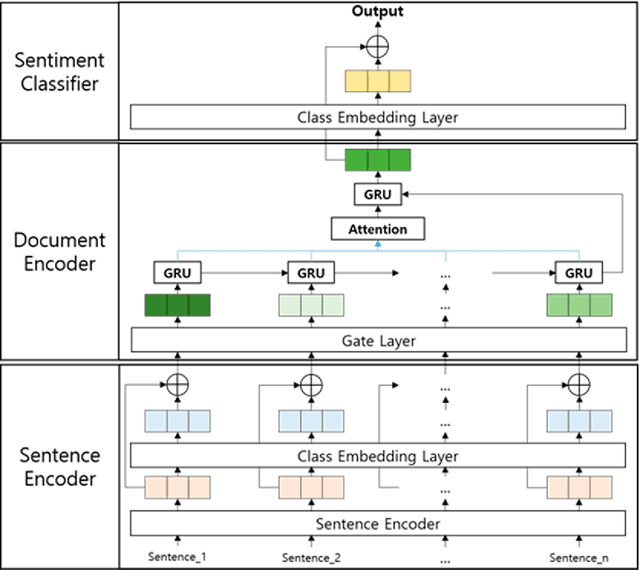
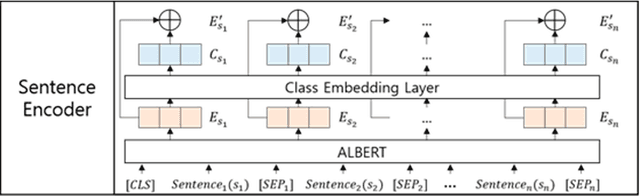
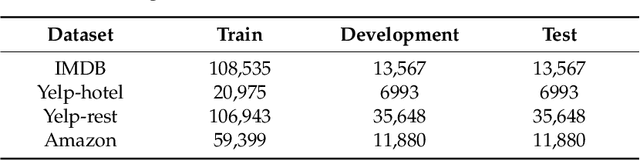
Previous researchers have considered sentiment analysis as a document classification task, in which input documents are classified into predefined sentiment classes. Although there are sentences in a document that support important evidences for sentiment analysis and sentences that do not, they have treated the document as a bag of sentences. In other words, they have not considered the importance of each sentence in the document. To effectively determine polarity of a document, each sentence in the document should be dealt with different degrees of importance. To address this problem, we propose a document-level sentence classification model based on deep neural networks, in which the importance degrees of sentences in documents are automatically determined through gate mechanisms. To verify our new sentiment analysis model, we conducted experiments using the sentiment datasets in the four different domains such as movie reviews, hotel reviews, restaurant reviews, and music reviews. In the experiments, the proposed model outperformed previous state-of-the-art models that do not consider importance differences of sentences in a document. The experimental results show that the importance of sentences should be considered in a document-level sentiment classification task.
* 12 pages, 7 figures, 5 tables
Dual Pointer Network for Fast Extraction of Multiple Relations in a Sentence
Mar 05, 2021

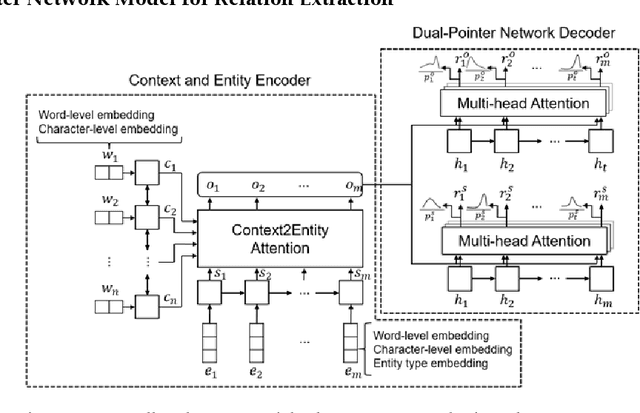
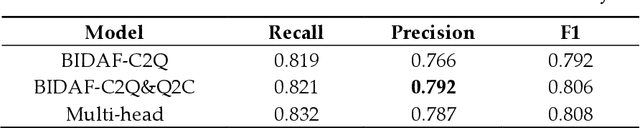
Relation extraction is a type of information extraction task that recognizes semantic relationships between entities in a sentence. Many previous studies have focused on extracting only one semantic relation between two entities in a single sentence. However, multiple entities in a sentence are associated through various relations. To address this issue, we propose a relation extraction model based on a dual pointer network with a multi-head attention mechanism. The proposed model finds n-to-1 subject-object relations using a forward object decoder. Then, it finds 1-to-n subject-object relations using a backward subject decoder. Our experiments confirmed that the proposed model outperformed previous models, with an F1-score of 80.8% for the ACE-2005 corpus and an F1-score of 78.3% for the NYT corpus.
ThisIsCompetition at SemEval-2019 Task 9: BERT is unstable for out-of-domain samples
Apr 06, 2019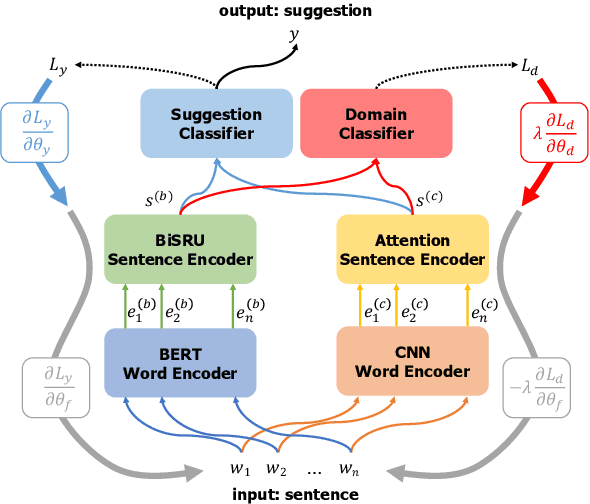
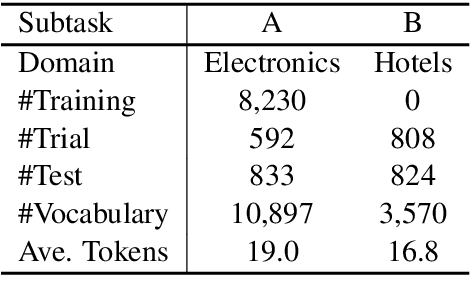
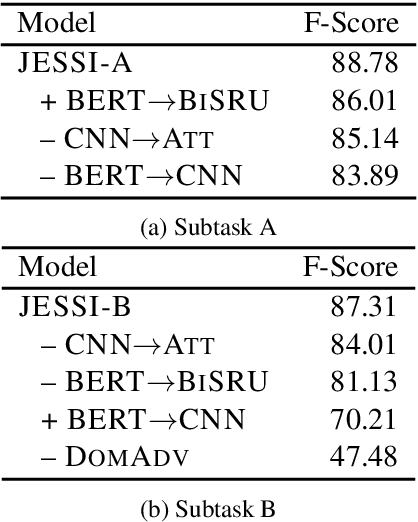
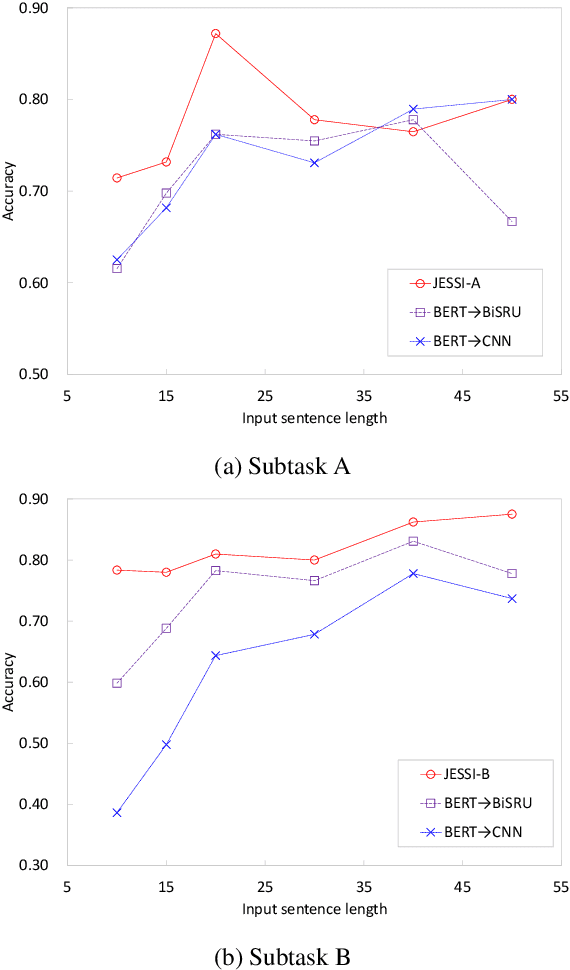
This paper describes our system, Joint Encoders for Stable Suggestion Inference (JESSI), for the SemEval 2019 Task 9: Suggestion Mining from Online Reviews and Forums. JESSI is a combination of two sentence encoders: (a) one using multiple pre-trained word embeddings learned from log-bilinear regression (GloVe) and translation (CoVe) models, and (b) one on top of word encodings from a pre-trained deep bidirectional transformer (BERT). We include a domain adversarial training module when training for out-of-domain samples. Our experiments show that while BERT performs exceptionally well for in-domain samples, several runs of the model show that it is unstable for out-of-domain samples. The problem is mitigated tremendously by (1) combining BERT with a non-BERT encoder, and (2) using an RNN-based classifier on top of BERT. Our final models obtained second place with 77.78\% F-Score on Subtask A (i.e. in-domain) and achieved an F-Score of 79.59\% on Subtask B (i.e. out-of-domain), even without using any additional external data.