 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammar Accuracy Evaluation (GAE): Quantifiable Intrinsic Evaluation of Machine Translation Models
Paper and Code
Jun 01, 2021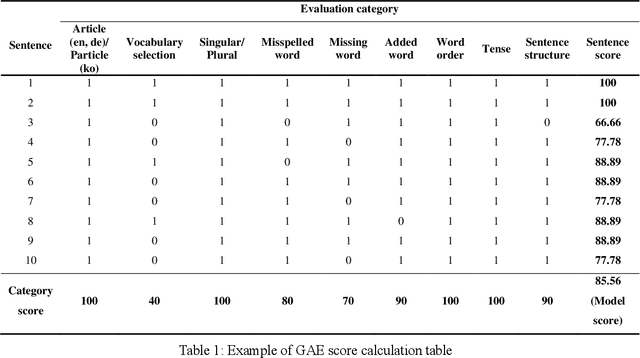
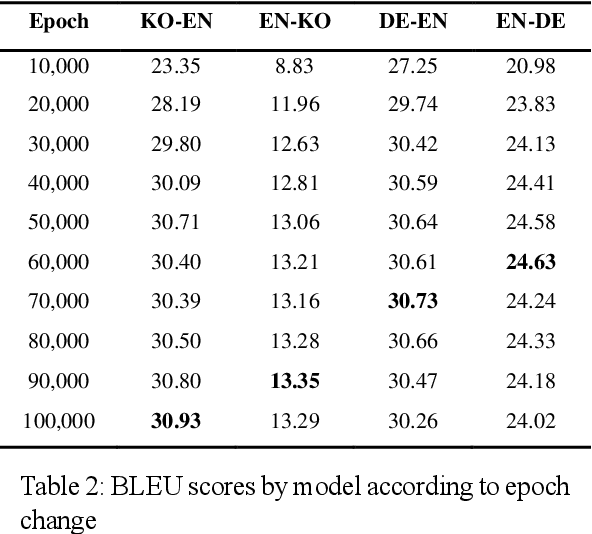
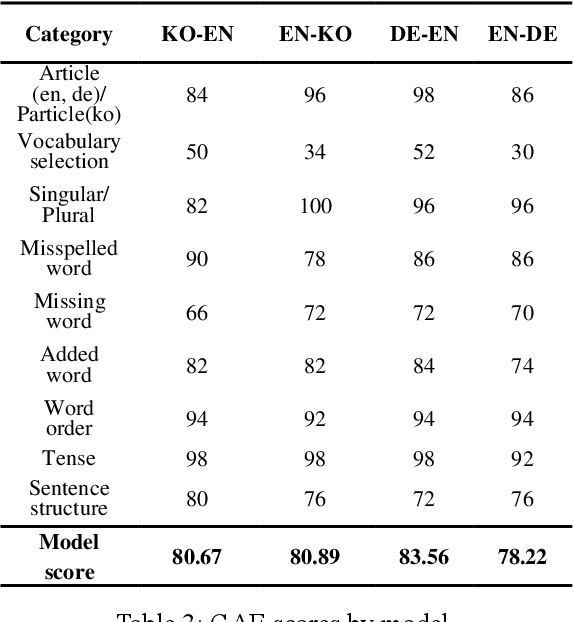

Intrinsic evaluation by humans for the performance of natural language generation models is conducted to overcome the fact that the quality of generated sentences cannot be fully represented by only extrinsic evaluation. Nevertheless, existing intrinsic evaluations have a large score deviation according to the evaluator's criteria. In this paper, we propose Grammar Accuracy Evaluation (GAE) that can provide specific evaluating criteria. As a result of analyzing the quality of machine translation by BLEU and GAE, it was confirmed that the BLEU score does not represent the absolute performance of machine translation models and that GAE compensates for the shortcomings of BLEU with a flexible evaluation on alternative synonyms and changes in sentence structure.