 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multimodal Perception in Large Language Models Through Perceptual Strength Ratings
Mar 10, 2025This study investigated the multimodal perception of large language models (LLMs), focusing on their ability to capture human-like perceptual strength ratings across sensory modalities. Utilizing perceptual strength ratings as a benchmark, the research compared GPT-3.5, GPT-4, GPT-4o, and GPT-4o-mini, highlighting the influence of multimodal inputs on grounding and linguistic reasoning. While GPT-4 and GPT-4o demonstrated strong alignment with human evaluations and significant advancements over smaller models, qualitative analyses revealed distinct differences in processing patterns, such as multisensory overrating and reliance on loose semantic associations. Despite integrating multimodal capabilities, GPT-4o did not exhibit superior grounding compared to GPT-4, raising questions about their role in improving human-like grounding. These findings underscore how LLMs' reliance on linguistic patterns can both approximate and diverge from human embodied cognition, revealing limitations in replicating sensory experiences.
MultiPragEval: Multilingual Pragmatic Evaluation of Large Language Models
Jun 11, 2024As the capabilities of LLMs expand, it becomes increasingly important to evaluate them beyond basic knowledge assessment, focusing on higher-level language understanding. This study introduces MultiPragEval, a robust test suite designed for the multilingual pragmatic evaluation of LLMs across English, German, Korean, and Chinese. Comprising 1200 question units categorized according to Grice's Cooperative Principle and its four conversational maxims, MultiPragEval enables an in-depth assessment of LLMs' contextual awareness and their ability to infer implied meanings. Our findings demonstrate that Claude3-Opus significantly outperforms other models in all tested languages, establishing a state-of-the-art in the field. Among open-source models, Solar-10.7B and Qwen1.5-14B emerge as strong competitors. This study not only leads the way in the multilingual evaluation of LLMs in pragmatic inference but also provides valuable insights into the nuanced capabilities necessary for advanced language comprehension in AI systems.
Pragmatic Competence Evaluation of Large Language Models for Korean
Mar 19, 2024The current evaluation of Large Language Models (LLMs) predominantly relies on benchmarks focusing on their embedded knowledge by testing through multiple-choice questions (MCQs), a format inherently suited for automated evaluation. Our study extends this evaluation to explore LLMs' pragmatic competence--a facet previously underexamined before the advent of sophisticated LLMs, specifically in the context of Korean. We employ two distinct evaluation setups: the conventional MCQ format, adapted for automatic evaluation, and Open-Ended Questions (OEQs), assessed by human experts, to examine LLMs' narrative response capabilities without predefined options. Our findings reveal that GPT-4 excels, scoring 81.11 and 85.69 in the MCQ and OEQ setups, respectively, with HyperCLOVA X, an LLM optimized for Korean, closely following, especially in the OEQ setup, demonstrating a score of 81.56 with a marginal difference of 4.13 points compared to GPT-4. Furthermore, while few-shot learning strategies generally enhance LLM performance, Chain-of-Thought (CoT) prompting introduces a bias toward literal interpretations, hindering accurate pragmatic inference. Considering the growing expectation for LLMs to understand and produce language that aligns with human communicative norms, our findings emphasize the importance for advancing LLMs' abilities to grasp and convey sophisticated meanings beyond mere literal interpretations.
Multi-Dimensional Machine Translation Evaluation: Model Evaluation and Resource for Korean
Mar 19, 2024Almost all frameworks for the manual or automatic evaluation of machine translation characterize the quality of an MT output with a single number. An exception is the Multidimensional Quality Metrics (MQM) framework which offers a fine-grained ontology of quality dimensions for scoring (such as style, fluency, accuracy, and terminology). Previous studies have demonstrated the feasibility of MQM annotation but there are, to our knowledge, no computational models that predict MQM scores for novel texts, due to a lack of resources. In this paper, we address these shortcomings by (a) providing a 1200-sentence MQM evaluation benchmark for the language pair English-Korean and (b) reframing MT evaluation as the multi-task problem of simultaneously predicting several MQM scores using SOTA language models, both in a reference-based MT evaluation setup and a reference-free quality estimation (QE) setup. We find that reference-free setup outperforms its counterpart in the style dimension while reference-based models retain an edge regarding accuracy. Overall, RemBERT emerges as the most promising model. Through our evaluation, we offer an insight into the translation quality in a more fine-grained, interpretable manner.
German Phoneme Recognition with Text-to-Phoneme Data Augmentation
Nov 24, 2022In this study, we experimented to examine the effect of adding the most frequent n phoneme bigrams to the basic vocabulary on the German phoneme recognition model using the text-to-phoneme data augmentation strategy. As a result, compared to the baseline model, the vowel30 model and the const20 model showed an increased BLEU score of more than 1 point, and the total30 model showed a significant decrease in the BLEU score of more than 20 points, showing that the phoneme bigrams could have a positive or negative effect on the model performance. In addition, we identified the types of errors that the models repeatedly showed through error analysis.
Grammar Accuracy Evaluation (GAE): Quantifiable Intrinsic Evaluation of Machine Translation Models
Jun 01, 2021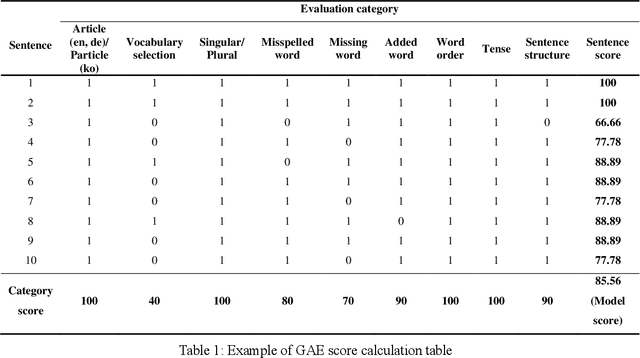
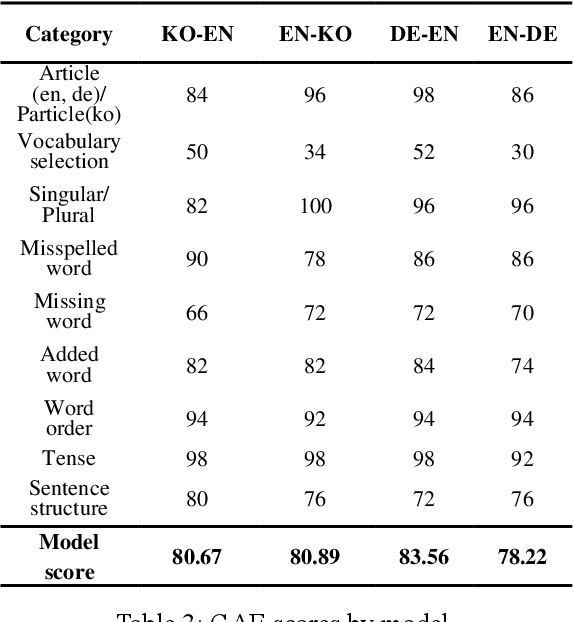

Intrinsic evaluation by humans for the performance of natural language generation models is conducted to overcome the fact that the quality of generated sentences cannot be fully represented by only extrinsic evaluation. Nevertheless, existing intrinsic evaluations have a large score deviation according to the evaluator's criteria. In this paper, we propose Grammar Accuracy Evaluation (GAE) that can provide specific evaluating criteria. As a result of analyzing the quality of machine translation by BLEU and GAE, it was confirmed that the BLEU score does not represent the absolute performance of machine translation models and that GAE compensates for the shortcomings of BLEU with a flexible evaluation on alternative synonyms and changes in sentence structure.
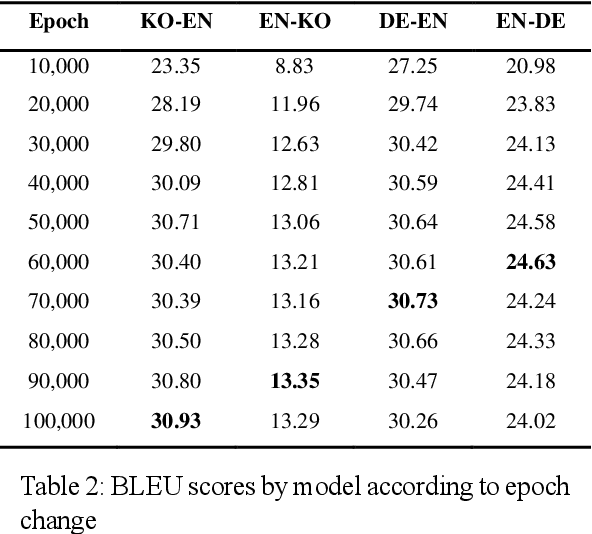
Korean-English Machine Translation with Multiple Tokenization Strategy
Jun 01, 2021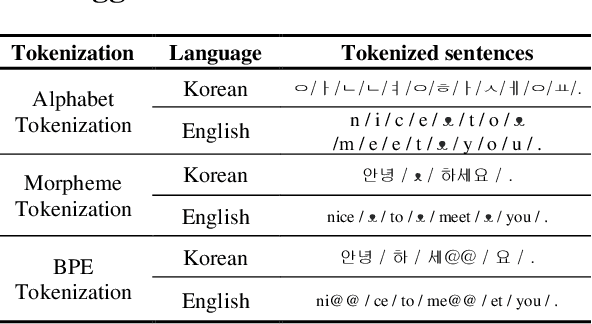
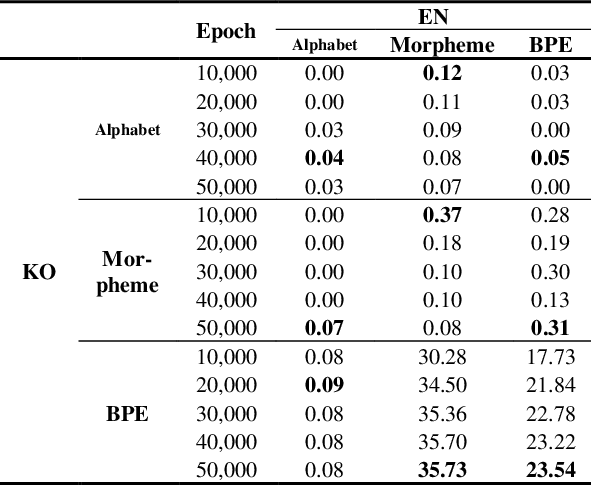
This work was conducted to find out how tokenization methods affect the training results of machine translation models. In this work, alphabet tokenization, morpheme tokenization, and BPE tokenization were applied to Korean as the source language and English as the target language respectively, and the comparison experiment was conducted by repeating 50,000 epochs of each 9 models using the Transformer neural network. As a result of measuring the BLEU scores of the experimental models, the model that applied BPE tokenization to Korean and morpheme tokenization to English recorded 35.73, showing the best performance.