Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKorean-English Machine Translation with Multiple Tokenization Strategy
Paper and Code
Jun 01, 2021
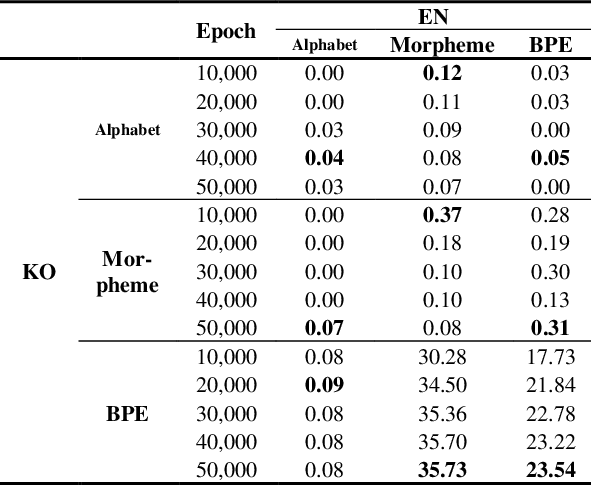
This work was conducted to find out how tokenization methods affect the training results of machine translation models. In this work, alphabet tokenization, morpheme tokenization, and BPE tokenization were applied to Korean as the source language and English as the target language respectively, and the comparison experiment was conducted by repeating 50,000 epochs of each 9 models using the Transformer neural network. As a result of measuring the BLEU scores of the experimental models, the model that applied BPE tokenization to Korean and morpheme tokenization to English recorded 35.73, showing the best performance.
* KCC2021 Undergraduate/Junior Thesis Competition
View paper on