 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLPDove at SemEval-2020 Task 12: Improving Offensive Language Detection with Cross-lingual Transfer
Aug 04, 2020


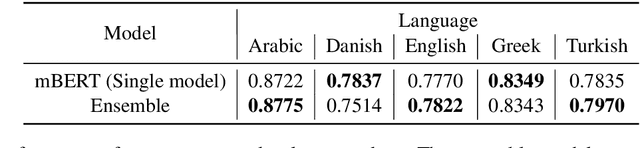
This paper describes our approach to the task of identifying offensive languages in a multilingual setting. We investigate two data augmentation strategies: using additional semi-supervised labels with different thresholds and cross-lingual transfer with data selection. Leveraging the semi-supervised dataset resulted in performance improvements compared to the baseline trained solely with the manually-annotated dataset. We propose a new metric, Translation Embedding Distance, to measure the transferability of instances for cross-lingual data selection. We also introduce various preprocessing steps tailored for social media text along with methods to fine-tune the pre-trained multilingual BERT (mBERT) for offensive language identification. Our multilingual systems achieved competitive results in Greek, Danish, and Turkish at OffensEval 2020.
ThisIsCompetition at SemEval-2019 Task 9: BERT is unstable for out-of-domain samples
Apr 06, 2019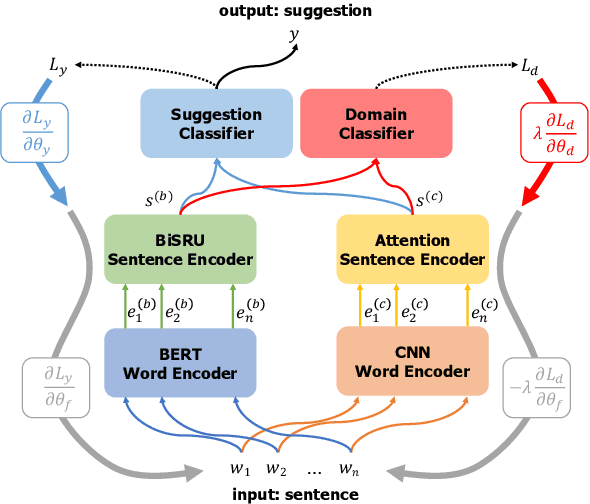
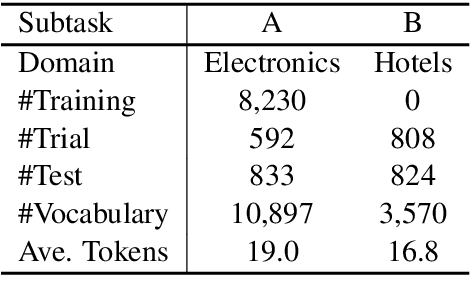
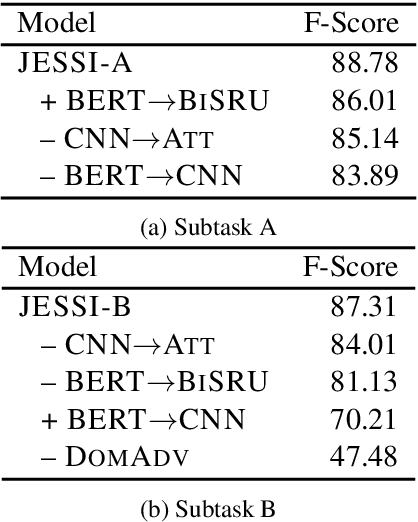
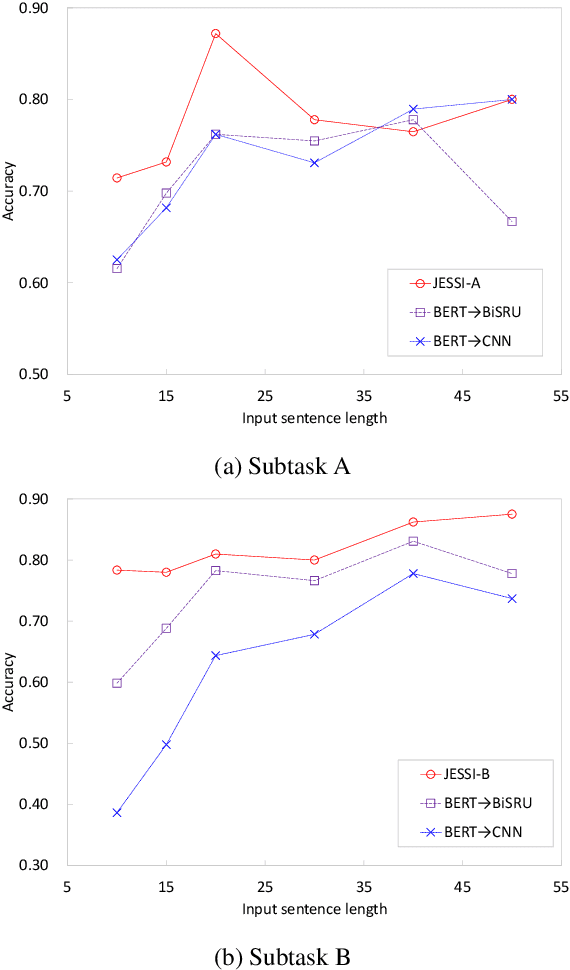
This paper describes our system, Joint Encoders for Stable Suggestion Inference (JESSI), for the SemEval 2019 Task 9: Suggestion Mining from Online Reviews and Forums. JESSI is a combination of two sentence encoders: (a) one using multiple pre-trained word embeddings learned from log-bilinear regression (GloVe) and translation (CoVe) models, and (b) one on top of word encodings from a pre-trained deep bidirectional transformer (BERT). We include a domain adversarial training module when training for out-of-domain samples. Our experiments show that while BERT performs exceptionally well for in-domain samples, several runs of the model show that it is unstable for out-of-domain samples. The problem is mitigated tremendously by (1) combining BERT with a non-BERT encoder, and (2) using an RNN-based classifier on top of BERT. Our final models obtained second place with 77.78\% F-Score on Subtask A (i.e. in-domain) and achieved an F-Score of 79.59\% on Subtask B (i.e. out-of-domain), even without using any additional external data.
A Robust Parser Based on Syntactic Information
Feb 22, 1995

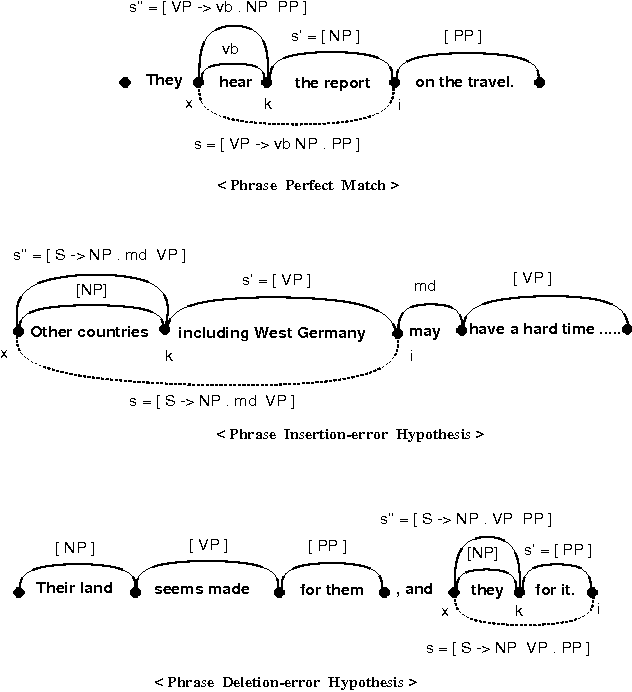

In this paper, we propose a robust parser which can parse extragrammatical sentences. This parser can recover them using only syntactic information. It can be easily modified and extended because it utilize only syntactic information.