 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedagogy-R1: Pedagogically-Aligned Reasoning Model with Balanced Educational Benchmark
May 24, 2025Recent advances in large reasoning models (LRMs) show strong performance in structured domains such as mathematics and programming; however, they often lack pedagogical coherence and realistic teaching behaviors. To bridge this gap, we introduce Pedagogy-R1, a framework that adapts LRMs for classroom use through three innovations: (1) a distillation-based pipeline that filters and refines model outputs for instruction-tuning, (2) the Well-balanced Educational Benchmark (WBEB), which evaluates performance across subject knowledge, pedagogical knowledge, tracing, essay scoring, and teacher decision-making, and (3) a Chain-of-Pedagogy (CoP) prompting strategy for generating and eliciting teacher-style reasoning. Our mixed-method evaluation combines quantitative metrics with qualitative analysis, providing the first systematic assessment of LRMs' pedagogical strengths and limitations.
ScholarBench: A Bilingual Benchmark for Abstraction, Comprehension, and Reasoning Evaluation in Academic Contexts
May 22, 2025



Prior benchmarks for evaluating the domain-specific knowledge of large language models (LLMs) lack the scalability to handle complex academic tasks. To address this, we introduce \texttt{ScholarBench}, a benchmark centered on deep expert knowledge and complex academic problem-solving, which evaluates the academic reasoning ability of LLMs and is constructed through a three-step process. \texttt{ScholarBench} targets more specialized and logically complex contexts derived from academic literature, encompassing five distinct problem types. Unlike prior benchmarks, \texttt{ScholarBench} evaluates the abstraction, comprehension, and reasoning capabilities of LLMs across eight distinct research domains. To ensure high-quality evaluation data, we define category-specific example attributes and design questions that are aligned with the characteristic research methodologies and discourse structures of each domain. Additionally, this benchmark operates as an English-Korean bilingual dataset, facilitating simultaneous evaluation for linguistic capabilities of LLMs in both languages. The benchmark comprises 5,031 examples in Korean and 5,309 in English, with even state-of-the-art models like o3-mini achieving an average evaluation score of only 0.543, demonstrating the challenging nature of this benchmark.
Conformal mapping Coordinates Physics-Informed Neural Networks (CoCo-PINNs): learning neural networks for designing neutral inclusions
Jan 14, 2025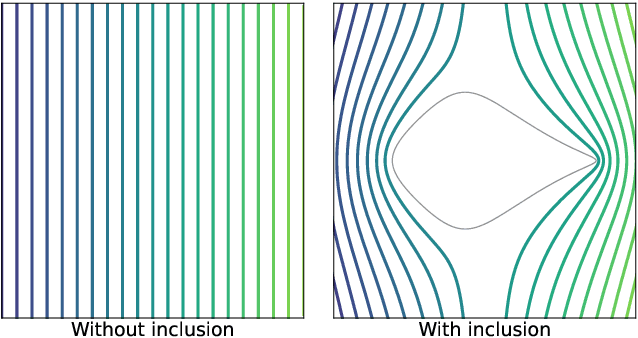



We focus on designing and solving the neutral inclusion problem via neural networks. The neutral inclusion problem has a long history in the theory of composite materials, and it is exceedingly challenging to identify the precise condition that precipitates a general-shaped inclusion into a neutral inclusion. Physics-informed neural networks (PINNs) have recently become a highly successful approach to addressing both forward and inverse problems associated with partial differential equations. We found that traditional PINNs perform inadequately when applied to the inverse problem of designing neutral inclusions with arbitrary shapes. In this study, we introduce a novel approach, Conformal mapping Coordinates Physics-Informed Neural Networks (CoCo-PINNs), which integrates complex analysis techniques into PINNs. This method exhibits strong performance in solving forward-inverse problems to construct neutral inclusions of arbitrary shapes in two dimensions, where the imperfect interface condition on the inclusion's boundary is modeled by training neural networks. Notably, we mathematically prove that training with a single linear field is sufficient to achieve neutrality for untrained linear fields in arbitrary directions, given a minor assumption. We demonstrate that CoCo-PINNs offer enhanced performances in terms of credibility, consistency, and stability.
Error analysis for finite element operator learning methods for solving parametric second-order elliptic PDEs
Apr 27, 2024In this paper, we provide a theoretical analysis of a type of operator learning method without data reliance based on the classical finite element approximation, which is called the finite element operator network (FEONet). We first establish the convergence of this method for general second-order linear elliptic PDEs with respect to the parameters for neural network approximation. In this regard, we address the role of the condition number of the finite element matrix in the convergence of the method. Secondly, we derive an explicit error estimate for the self-adjoint case. For this, we investigate some regularity properties of the solution in certain function classes for a neural network approximation, verifying the sufficient condition for the solution to have the desired regularity. Finally, we will also conduct some numerical experiments that support the theoretical findings, confirming the role of the condition number of the finite element matrix in the overall convergence.
Asymptotic Properties for Bayesian Neural Network in Besov Space
Jun 01, 2022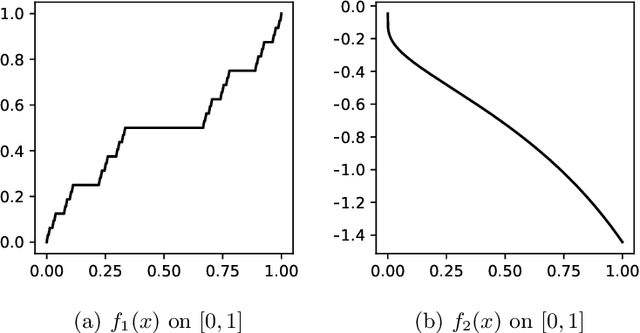


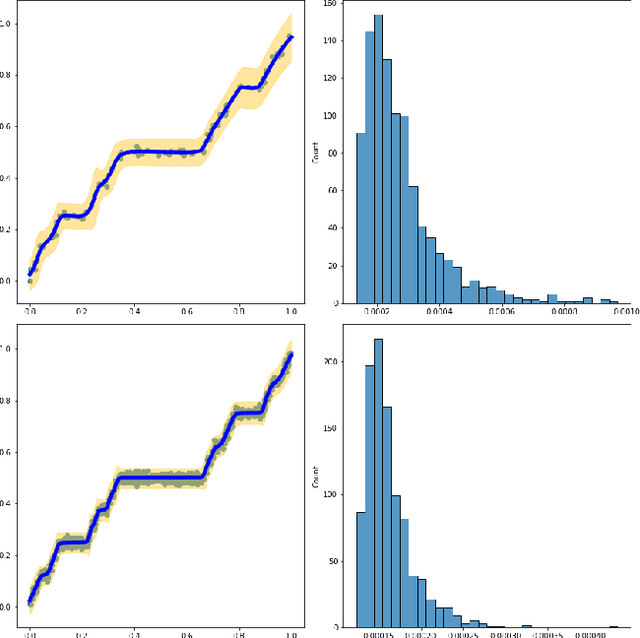
Neural networks have shown great predictive power when dealing with various unstructured data such as images and natural languages. The Bayesian neural network captures the uncertainty of prediction by putting a prior distribution for the parameter of the model and computing the posterior distribution. In this paper, we show that the Bayesian neural network using spike-and-slab prior has consistency with nearly minimax convergence rate when the true regression function is in the Besov space. Even when the smoothness of the regression function is unknown the same posterior convergence rate holds and thus the spike and slab prior is adaptive to the smoothness of the regression function. We also consider the shrinkage prior and show that it has the same convergence rate. In other words, we propose a practical Bayesian neural network with guaranteed asymptotic properties.
Generalized double Pareto shrinkage
Jan 26, 2013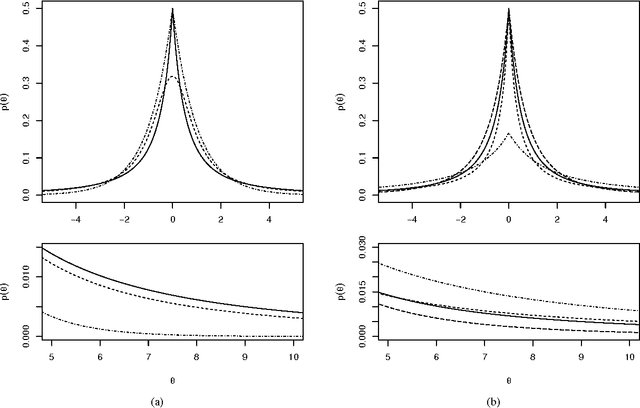
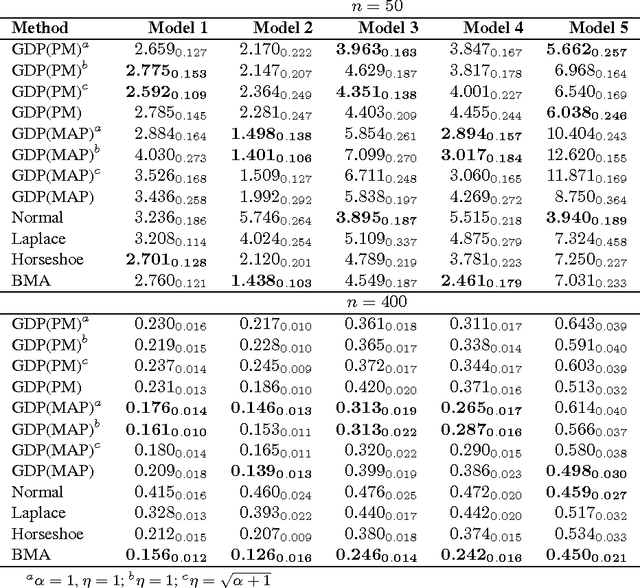
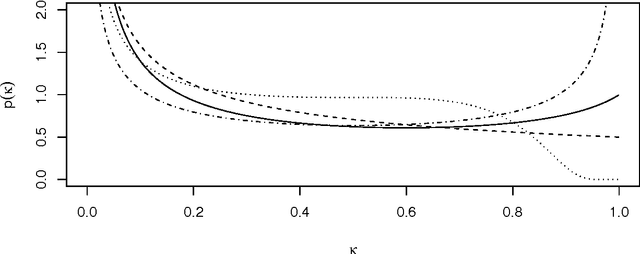
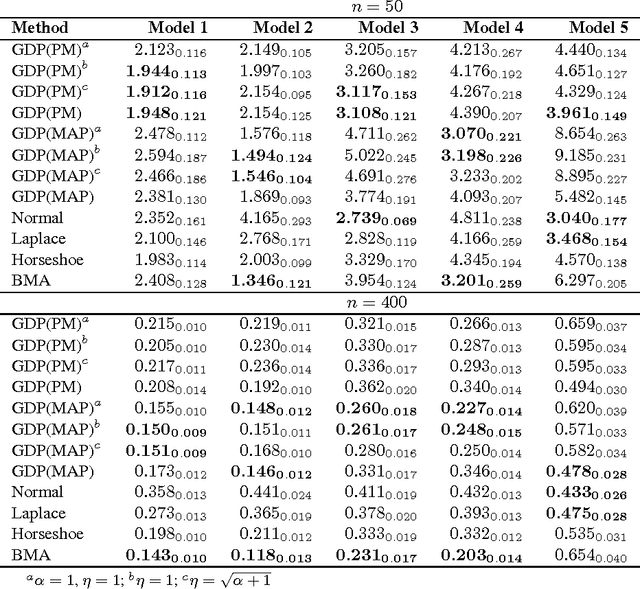
We propose a generalized double Pareto prior for Bayesian shrinkage estimation and inferences in linear models. The prior can be obtained via a scale mixture of Laplace or normal distributions, forming a bridge between the Laplace and Normal-Jeffreys' priors. While it has a spike at zero like the Laplace density, it also has a Student's $t$-like tail behavior. Bayesian computation is straightforward via a simple Gibbs sampling algorithm. We investigate the properties of the maximum a posteriori estimator, as sparse estimation plays an important role in many problems, reveal connections with some well-established regularization procedures, and show some asymptotic results. The performance of the prior is tested through simulations and an application.