 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewarding How Models Think Pedagogically: Integrating Pedagogical Reasoning and Thinking Rewards for LLMs in Education
Jan 21, 2026Large language models (LLMs) are increasingly deployed as intelligent tutoring systems, yet research on optimizing LLMs specifically for educational contexts remains limited. Recent works have proposed reinforcement learning approaches for training LLM tutors, but these methods focus solely on optimizing visible responses while neglecting the model's internal thinking process. We introduce PedagogicalRL-Thinking, a framework that extends pedagogical alignment to reasoning LLMs in education through two novel approaches: (1) Pedagogical Reasoning Prompting, which guides internal reasoning using domain-specific educational theory rather than generic instructions; and (2) Thinking Reward, which explicitly evaluates and reinforces the pedagogical quality of the model's reasoning traces. Our experiments reveal that domain-specific, theory-grounded prompting outperforms generic prompting, and that Thinking Reward is most effective when combined with pedagogical prompting. Furthermore, models trained only on mathematics tutoring dialogues show improved performance on educational benchmarks not seen during training, while preserving the base model's factual knowledge. Our quantitative and qualitative analyses reveal that pedagogical thinking reward produces systematic reasoning trace changes, with increased pedagogical reasoning and more structured instructional decision-making in the tutor's thinking process.
OpenLearnLM Benchmark: A Unified Framework for Evaluating Knowledge, Skill, and Attitude in Educational Large Language Models
Jan 20, 2026Large Language Models are increasingly deployed as educational tools, yet existing benchmarks focus on narrow skills and lack grounding in learning sciences. We introduce OpenLearnLM Benchmark, a theory-grounded framework evaluating LLMs across three dimensions derived from educational assessment theory: Knowledge (curriculum-aligned content and pedagogical understanding), Skills (scenario-based competencies organized through a four-level center-role-scenario-subscenario hierarchy), and Attitude (alignment consistency and deception resistance). Our benchmark comprises 124K+ items spanning multiple subjects, educational roles, and difficulty levels based on Bloom's taxonomy. The Knowledge domain prioritizes authentic assessment items from established benchmarks, while the Attitude domain adapts Anthropic's Alignment Faking methodology to detect behavioral inconsistency under varying monitoring conditions. Evaluation of seven frontier models reveals distinct capability profiles: Claude-Opus-4.5 excels in practical skills despite lower content knowledge, while Grok-4.1-fast leads in knowledge but shows alignment concerns. Notably, no single model dominates all dimensions, validating the necessity of multi-axis evaluation. OpenLearnLM provides an open, comprehensive framework for advancing LLM readiness in authentic educational contexts.
Pedagogical Alignment for Vision-Language-Action Models: A Comprehensive Framework for Data, Architecture, and Evaluation in Education
Jan 20, 2026Science demonstrations are important for effective STEM education, yet teachers face challenges in conducting them safely and consistently across multiple occasions, where robotics can be helpful. However, current Vision-Language-Action (VLA) models require substantial computational resources and sacrifice language generation capabilities to maximize efficiency, making them unsuitable for resource-constrained educational settings that require interpretable, explanation-generating systems. We present \textit{Pedagogical VLA Framework}, a framework that applies pedagogical alignment to lightweight VLA models through four components: text healing to restore language generation capabilities, large language model (LLM) distillation to transfer pedagogical knowledge, safety training for educational environments, and pedagogical evaluation adjusted to science education contexts. We evaluate Pedagogical VLA Framework across five science demonstrations spanning physics, chemistry, biology, and earth science, using an evaluation framework developed in collaboration with science education experts. Our evaluation assesses both task performance (success rate, protocol compliance, efficiency, safety) and pedagogical quality through teacher surveys and LLM-as-Judge assessment. We additionally provide qualitative analysis of generated texts. Experimental results demonstrate that Pedagogical VLA Framework achieves comparable task performance to baseline models while producing contextually appropriate educational explanations.
A Training-Free Large Reasoning Model-based Knowledge Tracing Framework for Unified Prediction and Prescription
Jan 05, 2026Knowledge Tracing (KT) aims to estimate a learner's evolving mastery based on interaction histories. Recent studies have explored Large Language Models (LLMs) for KT via autoregressive nature, but such approaches typically require fine-tuning and exhibit unstable or near-random performance. Moreover, prior KT systems primarily focus on prediction and rely on multi-stage pipelines for feedback and recommendation, resulting in increased system complexity and resources. To address this gap, we propose Thinking-KT, a training-free KT framework that incorporates Test-Time Scaling (TTS), enabling even small LLMs to achieve competitive KT performance. Moreover, in this framework, a small LLM can jointly perform KT prediction, personalized feedback generation, and learning recommendation in a unified output without degrading prediction accuracy. Beyond performance, we present the systematic analysis of reasoning traces in KT. Our results demonstrate that TTS is a critical yet underexplored factor in LLM-based KT, and that small LLMs can serve as unified ITS engines.
Pedagogy-R1: Pedagogically-Aligned Reasoning Model with Balanced Educational Benchmark
May 24, 2025Recent advances in large reasoning models (LRMs) show strong performance in structured domains such as mathematics and programming; however, they often lack pedagogical coherence and realistic teaching behaviors. To bridge this gap, we introduce Pedagogy-R1, a framework that adapts LRMs for classroom use through three innovations: (1) a distillation-based pipeline that filters and refines model outputs for instruction-tuning, (2) the Well-balanced Educational Benchmark (WBEB), which evaluates performance across subject knowledge, pedagogical knowledge, tracing, essay scoring, and teacher decision-making, and (3) a Chain-of-Pedagogy (CoP) prompting strategy for generating and eliciting teacher-style reasoning. Our mixed-method evaluation combines quantitative metrics with qualitative analysis, providing the first systematic assessment of LRMs' pedagogical strengths and limitations.
From Prediction to Application: Language Model-based Code Knowledge Tracing with Domain Adaptive Pre-Training and Automatic Feedback System with Pedagogical Prompting for Comprehensive Programming Education
Aug 31, 2024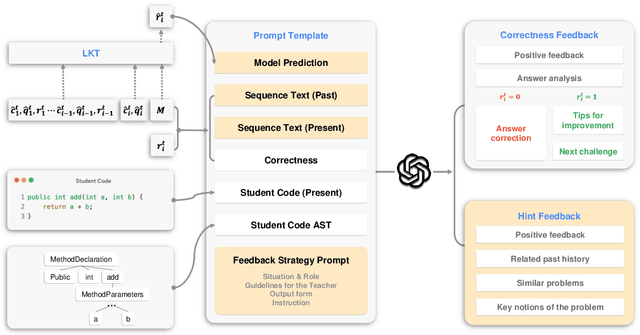
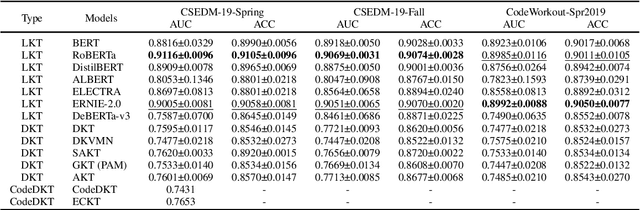
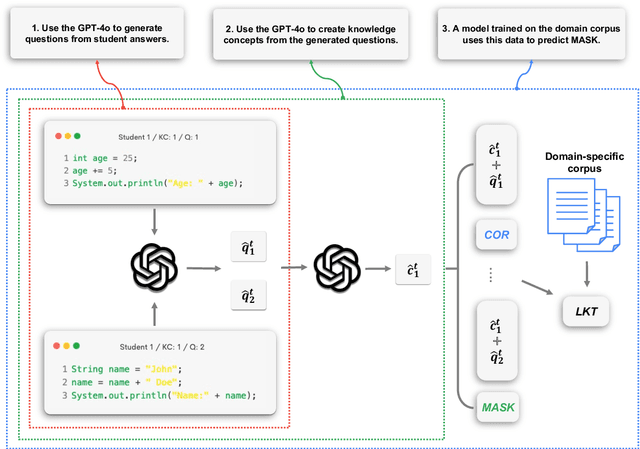
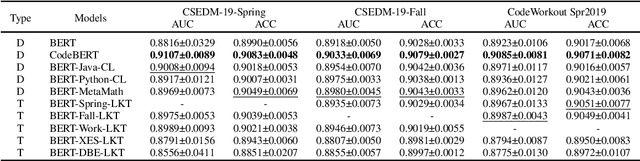
Knowledge Tracing (KT) is a critical component in online learning, but traditional approaches face limitations in interpretability and cross-domain adaptability. This paper introduces Language Model-based Code Knowledge Tracing (CodeLKT), an innovative application of Language model-based Knowledge Tracing (LKT) to programming education. CodeLKT leverages pre-trained language models to process learning data, demonstrating superior performance over existing KT and Code KT models. We explore Domain Adaptive Pre-Training (DAPT) and Task Adaptive Pre-Training (TAPT), showing enhanced performance in the coding domain and investigating cross-domain transfer between mathematics and coding. Additionally, we present an theoretically-informed integrated system combining CodeLKT with large language models to generate personalized, in-depth feedback to support students' programming learning. This work advances the field of Code Knowledge Tracing by expanding the knowledge base with language model-based approach and offering practical implications for programming education through data-informed feedback.
Language Model Can Do Knowledge Tracing: Simple but Effective Method to Integrate Language Model and Knowledge Tracing Task
Jun 05, 2024Knowledge Tracing (KT) is a critical task in online learning for modeling student knowledge over time. Despite the success of deep learning-based KT models, which rely on sequences of numbers as data, most existing approaches fail to leverage the rich semantic information in the text of questions and concepts. This paper proposes Language model-based Knowledge Tracing (LKT), a novel framework that integrates pre-trained language models (PLMs) with KT methods. By leveraging the power of language models to capture semantic representations, LKT effectively incorporates textual information and significantly outperforms previous KT models on large benchmark datasets. Moreover, we demonstrate that LKT can effectively address the cold-start problem in KT by leveraging the semantic knowledge captured by PLMs. Interpretability of LKT is enhanced compared to traditional KT models due to its use of text-rich data. We conducted the local interpretable model-agnostic explanation technique and analysis of attention scores to interpret the model performance further. Our work highlights the potential of integrating PLMs with KT and paves the way for future research in KT domain.
LLaVA-Docent: Instruction Tuning with Multimodal Large Language Model to Support Art Appreciation Education
Feb 09, 2024



Art appreciation is vital in nurturing critical thinking and emotional intelligence among learners. However, traditional art appreciation education has often been hindered by limited access to art resources, especially for disadvantaged students, and an imbalanced emphasis on STEM subjects in mainstream education. In response to these challenges, recent technological advancements have paved the way for innovative solutions. This study explores the application of multi-modal large language models (MLLMs) in art appreciation education, focusing on developing LLaVA-Docent, a model that leverages these advancements. Our approach involved a comprehensive literature review and consultations with experts in the field, leading to developing a robust data framework. Utilizing this framework, we generated a virtual dialogue dataset that was leveraged by GPT-4. This dataset was instrumental in training the MLLM, named LLaVA-Docent. Six researchers conducted quantitative and qualitative evaluations of LLaVA-Docent to assess its effectiveness, benchmarking it against the GPT-4 model in a few-shot setting. The evaluation process revealed distinct strengths and weaknesses of the LLaVA-Docent model. Our findings highlight the efficacy of LLaVA-Docent in enhancing the accessibility and engagement of art appreciation education. By harnessing the potential of MLLMs, this study makes a significant contribution to the field of art education, proposing a novel methodology that reimagines the way art appreciation is taught and experienced.
Difficulty-Focused Contrastive Learning for Knowledge Tracing with a Large Language Model-Based Difficulty Prediction
Dec 19, 2023



This paper presents novel techniques for enhancing the performance of knowledge tracing (KT) models by focusing on the crucial factor of question and concept difficulty level. Despite the acknowledged significance of difficulty, previous KT research has yet to exploit its potential for model optimization and has struggled to predict difficulty from unseen data. To address these problems, we propose a difficulty-centered contrastive learning method for KT models and a Large Language Model (LLM)-based framework for difficulty prediction. These innovative methods seek to improve the performance of KT models and provide accurate difficulty estimates for unseen data. Our ablation study demonstrates the efficacy of these techniques by demonstrating enhanced KT model performance. Nonetheless, the complex relationship between language and difficulty merits further investigation.
MonaCoBERT: Monotonic attention based ConvBERT for Knowledge Tracing
Aug 19, 2022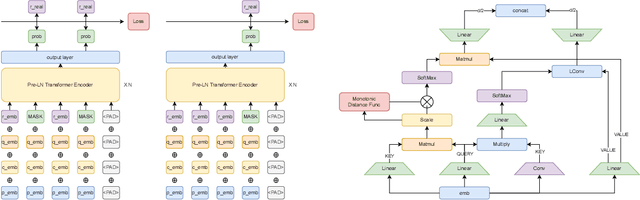
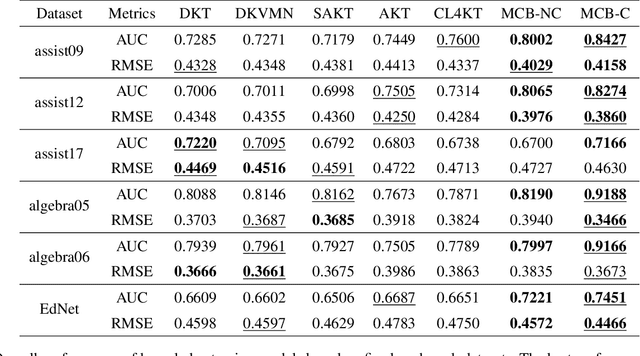
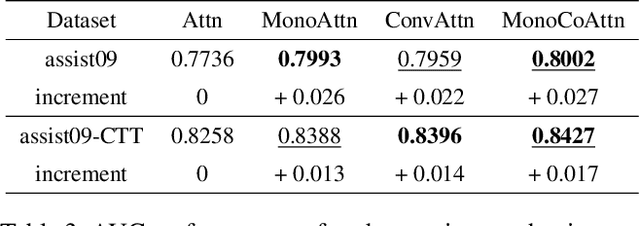
Knowledge tracing (KT) is a field of study that predicts the future performance of students based on prior performance datasets collected from educational applications such as intelligent tutoring systems, learning management systems, and online courses. Some previous studies on KT have concentrated only on the interpretability of the model, whereas others have focused on enhancing the performance. Models that consider both interpretability and the performance improvement have been insufficient. Moreover, models that focus on performance improvements have not shown an overwhelming performance compared with existing models. In this study, we propose MonaCoBERT, which achieves the best performance on most benchmark datasets and has significant interpretability. MonaCoBERT uses a BERT-based architecture with monotonic convolutional multihead attention, which reflects forgetting behavior of the students and increases the representation power of the model. We can also increase the performance and interpretability using a classical test-theory-based (CTT-based) embedding strategy that considers the difficulty of the question. To determine why MonaCoBERT achieved the best performance and interpret the results quantitatively, we conducted ablation studies and additional analyses using Grad-CAM, UMAP, and various visualization techniques. The analysis results demonstrate that both attention components complement one another and that CTT-based embedding represents information on both global and local difficulties. We also demonstrate that our model represents the relationship between concepts.