 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifficulty-Focused Contrastive Learning for Knowledge Tracing with a Large Language Model-Based Difficulty Prediction
Dec 19, 2023



This paper presents novel techniques for enhancing the performance of knowledge tracing (KT) models by focusing on the crucial factor of question and concept difficulty level. Despite the acknowledged significance of difficulty, previous KT research has yet to exploit its potential for model optimization and has struggled to predict difficulty from unseen data. To address these problems, we propose a difficulty-centered contrastive learning method for KT models and a Large Language Model (LLM)-based framework for difficulty prediction. These innovative methods seek to improve the performance of KT models and provide accurate difficulty estimates for unseen data. Our ablation study demonstrates the efficacy of these techniques by demonstrating enhanced KT model performance. Nonetheless, the complex relationship between language and difficulty merits further investigation.
Faster Greedy MAP Inference for Determinantal Point Processes
Jun 14, 2017
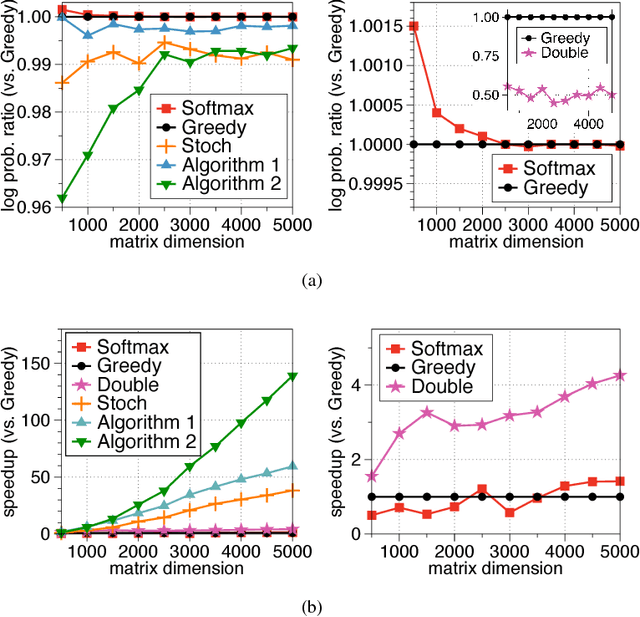
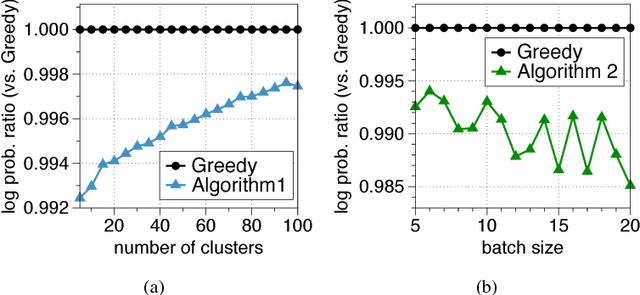
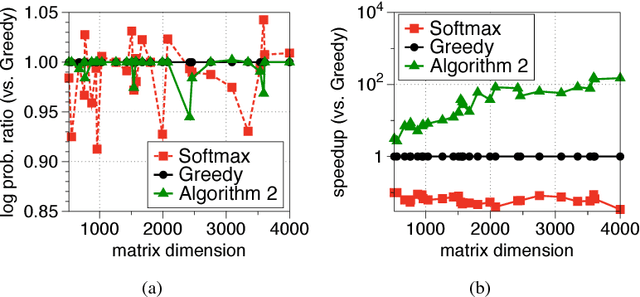
Determinantal point processes (DPPs) are popular probabilistic models that arise in many machine learning tasks, where distributions of diverse sets are characterized by matrix determinants. In this paper, we develop fast algorithms to find the most likely configuration (MAP) of large-scale DPPs, which is NP-hard in general. Due to the submodular nature of the MAP objective, greedy algorithms have been used with empirical success. Greedy implementations require computation of log-determinants, matrix inverses or solving linear systems at each iteration. We present faster implementations of the greedy algorithms by utilizing the complementary benefits of two log-determinant approximation schemes: (a) first-order expansions to the matrix log-determinant function and (b) high-order expansions to the scalar log function with stochastic trace estimators. In our experiments, our algorithms are orders of magnitude faster than their competitors, while sacrificing marginal accuracy.