 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Greedy MAP Inference for Determinantal Point Processes
Paper and Code
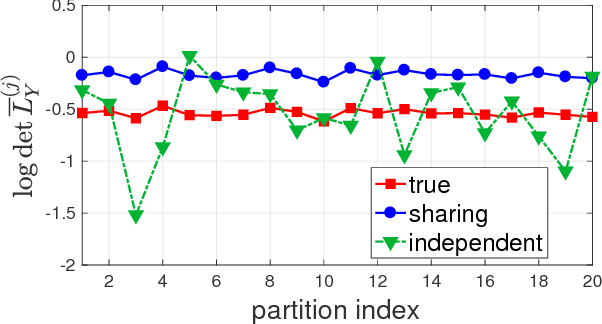
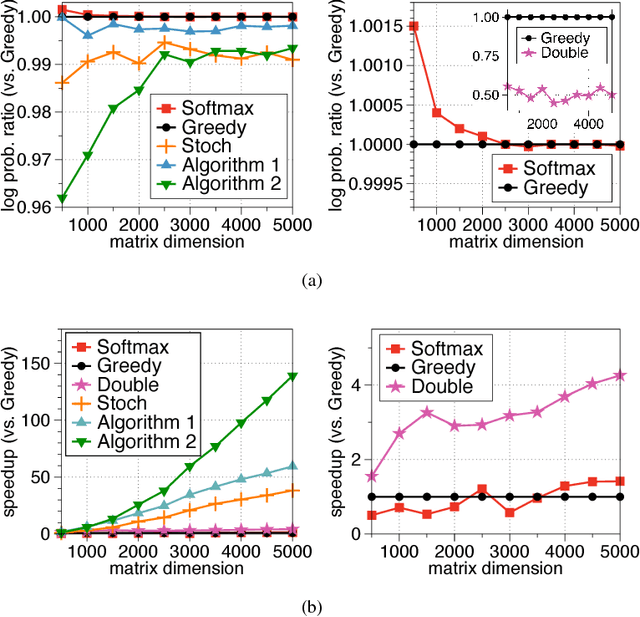
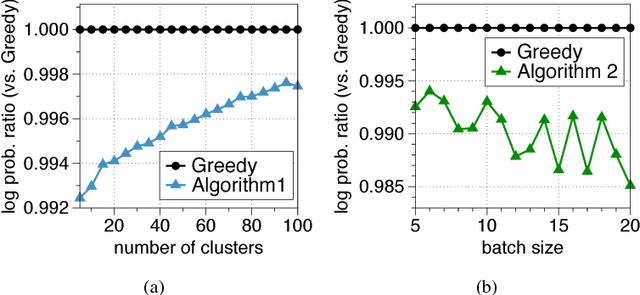
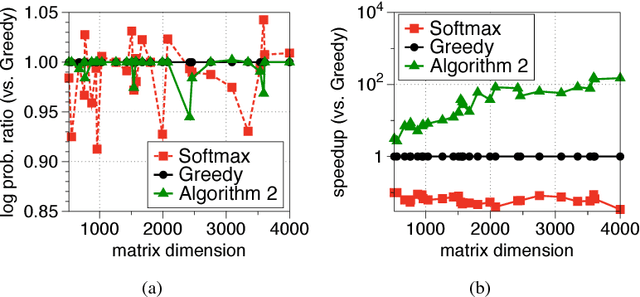
Determinantal point processes (DPPs) are popular probabilistic models that arise in many machine learning tasks, where distributions of diverse sets are characterized by matrix determinants. In this paper, we develop fast algorithms to find the most likely configuration (MAP) of large-scale DPPs, which is NP-hard in general. Due to the submodular nature of the MAP objective, greedy algorithms have been used with empirical success. Greedy implementations require computation of log-determinants, matrix inverses or solving linear systems at each iteration. We present faster implementations of the greedy algorithms by utilizing the complementary benefits of two log-determinant approximation schemes: (a) first-order expansions to the matrix log-determinant function and (b) high-order expansions to the scalar log function with stochastic trace estimators. In our experiments, our algorithms are orders of magnitude faster than their competitors, while sacrificing marginal accuracy.