 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsuring Reliability in Programming Knowledge Tracing: A Re-evaluation of Attention-augmented Models and Experimental Protocols
May 06, 2026Programming Knowledge Tracing (PKT) has recently advanced through hybrid approaches that integrate attention-based feature modeling for code representation with RNN-based sequential prediction. While these models report strong empirical performance, their reliability can be sensitive to subtle implementation and experimental design choices. This study revisits representative PKT models and shows that reported gains can be substantially influenced by model configuration and sequence construction practices. We identify issues in attention dimension settings that affect performance estimates, and demonstrate that improper ordering of student attempts, such as ignoring ServerTimestamp, can violate temporal causality and lead to overly optimistic results. To ensure consistent evaluation, hyperparameters are selected via grid search guided by a single designated fold and then fixed uniformly across all folds during cross-validation. We further analyze the role of assignment-wise characteristics and systematically explore the impact of maximum sequence length. Using this protocol, we re-evaluate PKT models on the CodeWorkout dataset. Our results show that, under controlled and consistent settings, the performance gap between attention-enhanced models and standard DKT is significantly reduced, and increased architectural complexity does not consistently translate into superior performance. Beyond individual model comparisons, this work provides practical guidance for reliable and comparable evaluation in programming knowledge tracing.
KTCF: Actionable Recourse in Knowledge Tracing via Counterfactual Explanations for Education
Jan 14, 2026Using Artificial Intelligence to improve teaching and learning benefits greater adaptivity and scalability in education. Knowledge Tracing (KT) is recognized for student modeling task due to its superior performance and application potential in education. To this end, we conceptualize and investigate counterfactual explanation as the connection from XAI for KT to education. Counterfactual explanations offer actionable recourse, are inherently causal and local, and easy for educational stakeholders to understand who are often non-experts. We propose KTCF, a counterfactual explanation generation method for KT that accounts for knowledge concept relationships, and a post-processing scheme that converts a counterfactual explanation into a sequence of educational instructions. We experiment on a large-scale educational dataset and show our KTCF method achieves superior and robust performance over existing methods, with improvements ranging from 5.7% to 34% across metrics. Additionally, we provide a qualitative evaluation of our post-processing scheme, demonstrating that the resulting educational instructions help in reducing large study burden. We show that counterfactuals have the potential to advance the responsible and practical use of AI in education. Future works on XAI for KT may benefit from educationally grounded conceptualization and developing stakeholder-centered methods.
Evaluating LLMs for Police Decision-Making: A Framework Based on Police Action Scenarios
Jan 07, 2026The use of Large Language Models (LLMs) in police operations is growing, yet an evaluation framework tailored to police operations remains absent. While LLM's responses may not always be legally incorrect, their unverified use still can lead to severe issues such as unlawful arrests and improper evidence collection. To address this, we propose PAS (Police Action Scenarios), a systematic framework covering the entire evaluation process. Applying this framework, we constructed a novel QA dataset from over 8,000 official documents and established key metrics validated through statistical analysis with police expert judgements. Experimental results show that commercial LLMs struggle with our new police-related tasks, particularly in providing fact-based recommendations. This study highlights the necessity of an expandable evaluation framework to ensure reliable AI-driven police operations. We release our data and prompt template.
Pedagogy-R1: Pedagogically-Aligned Reasoning Model with Balanced Educational Benchmark
May 24, 2025Recent advances in large reasoning models (LRMs) show strong performance in structured domains such as mathematics and programming; however, they often lack pedagogical coherence and realistic teaching behaviors. To bridge this gap, we introduce Pedagogy-R1, a framework that adapts LRMs for classroom use through three innovations: (1) a distillation-based pipeline that filters and refines model outputs for instruction-tuning, (2) the Well-balanced Educational Benchmark (WBEB), which evaluates performance across subject knowledge, pedagogical knowledge, tracing, essay scoring, and teacher decision-making, and (3) a Chain-of-Pedagogy (CoP) prompting strategy for generating and eliciting teacher-style reasoning. Our mixed-method evaluation combines quantitative metrics with qualitative analysis, providing the first systematic assessment of LRMs' pedagogical strengths and limitations.
Counterfactual Fairness Evaluation of Machine Learning Models on Educational Datasets
Apr 15, 2025As machine learning models are increasingly used in educational settings, from detecting at-risk students to predicting student performance, algorithmic bias and its potential impacts on students raise critical concerns about algorithmic fairness. Although group fairness is widely explored in education, works on individual fairness in a causal context are understudied, especially on counterfactual fairness. This paper explores the notion of counterfactual fairness for educational data by conducting counterfactual fairness analysis of machine learning models on benchmark educational datasets. We demonstrate that counterfactual fairness provides meaningful insight into the causality of sensitive attributes and causal-based individual fairness in education.
From Prediction to Application: Language Model-based Code Knowledge Tracing with Domain Adaptive Pre-Training and Automatic Feedback System with Pedagogical Prompting for Comprehensive Programming Education
Aug 31, 2024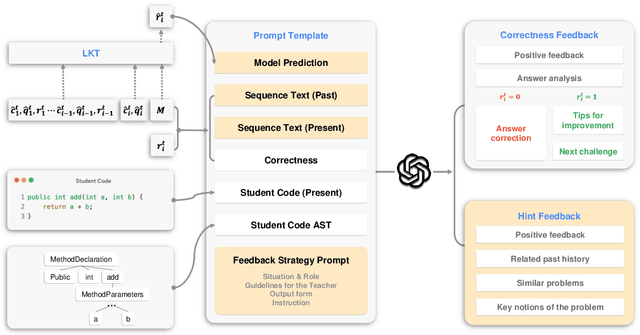
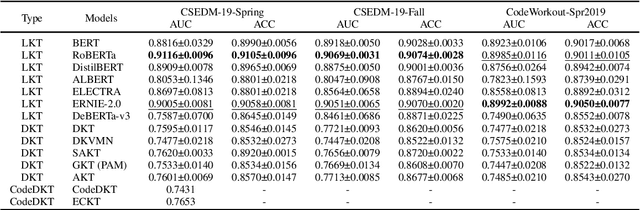
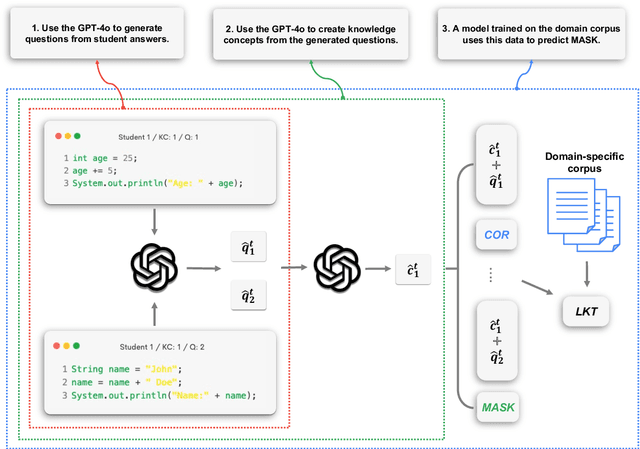
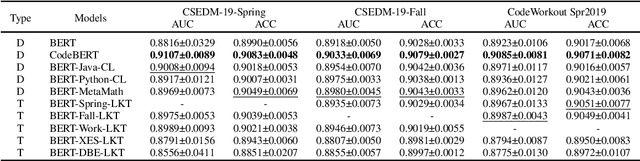
Knowledge Tracing (KT) is a critical component in online learning, but traditional approaches face limitations in interpretability and cross-domain adaptability. This paper introduces Language Model-based Code Knowledge Tracing (CodeLKT), an innovative application of Language model-based Knowledge Tracing (LKT) to programming education. CodeLKT leverages pre-trained language models to process learning data, demonstrating superior performance over existing KT and Code KT models. We explore Domain Adaptive Pre-Training (DAPT) and Task Adaptive Pre-Training (TAPT), showing enhanced performance in the coding domain and investigating cross-domain transfer between mathematics and coding. Additionally, we present an theoretically-informed integrated system combining CodeLKT with large language models to generate personalized, in-depth feedback to support students' programming learning. This work advances the field of Code Knowledge Tracing by expanding the knowledge base with language model-based approach and offering practical implications for programming education through data-informed feedback.
Language Model Can Do Knowledge Tracing: Simple but Effective Method to Integrate Language Model and Knowledge Tracing Task
Jun 05, 2024Knowledge Tracing (KT) is a critical task in online learning for modeling student knowledge over time. Despite the success of deep learning-based KT models, which rely on sequences of numbers as data, most existing approaches fail to leverage the rich semantic information in the text of questions and concepts. This paper proposes Language model-based Knowledge Tracing (LKT), a novel framework that integrates pre-trained language models (PLMs) with KT methods. By leveraging the power of language models to capture semantic representations, LKT effectively incorporates textual information and significantly outperforms previous KT models on large benchmark datasets. Moreover, we demonstrate that LKT can effectively address the cold-start problem in KT by leveraging the semantic knowledge captured by PLMs. Interpretability of LKT is enhanced compared to traditional KT models due to its use of text-rich data. We conducted the local interpretable model-agnostic explanation technique and analysis of attention scores to interpret the model performance further. Our work highlights the potential of integrating PLMs with KT and paves the way for future research in KT domain.
LLaVA-Docent: Instruction Tuning with Multimodal Large Language Model to Support Art Appreciation Education
Feb 09, 2024



Art appreciation is vital in nurturing critical thinking and emotional intelligence among learners. However, traditional art appreciation education has often been hindered by limited access to art resources, especially for disadvantaged students, and an imbalanced emphasis on STEM subjects in mainstream education. In response to these challenges, recent technological advancements have paved the way for innovative solutions. This study explores the application of multi-modal large language models (MLLMs) in art appreciation education, focusing on developing LLaVA-Docent, a model that leverages these advancements. Our approach involved a comprehensive literature review and consultations with experts in the field, leading to developing a robust data framework. Utilizing this framework, we generated a virtual dialogue dataset that was leveraged by GPT-4. This dataset was instrumental in training the MLLM, named LLaVA-Docent. Six researchers conducted quantitative and qualitative evaluations of LLaVA-Docent to assess its effectiveness, benchmarking it against the GPT-4 model in a few-shot setting. The evaluation process revealed distinct strengths and weaknesses of the LLaVA-Docent model. Our findings highlight the efficacy of LLaVA-Docent in enhancing the accessibility and engagement of art appreciation education. By harnessing the potential of MLLMs, this study makes a significant contribution to the field of art education, proposing a novel methodology that reimagines the way art appreciation is taught and experienced.
Difficulty-Focused Contrastive Learning for Knowledge Tracing with a Large Language Model-Based Difficulty Prediction
Dec 19, 2023



This paper presents novel techniques for enhancing the performance of knowledge tracing (KT) models by focusing on the crucial factor of question and concept difficulty level. Despite the acknowledged significance of difficulty, previous KT research has yet to exploit its potential for model optimization and has struggled to predict difficulty from unseen data. To address these problems, we propose a difficulty-centered contrastive learning method for KT models and a Large Language Model (LLM)-based framework for difficulty prediction. These innovative methods seek to improve the performance of KT models and provide accurate difficulty estimates for unseen data. Our ablation study demonstrates the efficacy of these techniques by demonstrating enhanced KT model performance. Nonetheless, the complex relationship between language and difficulty merits further investigation.
MonaCoBERT: Monotonic attention based ConvBERT for Knowledge Tracing
Aug 19, 2022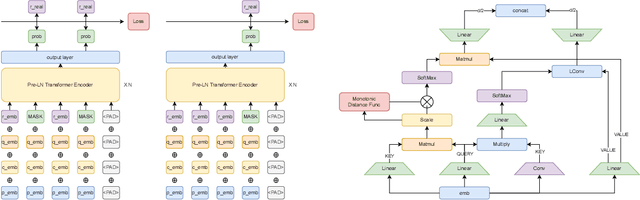
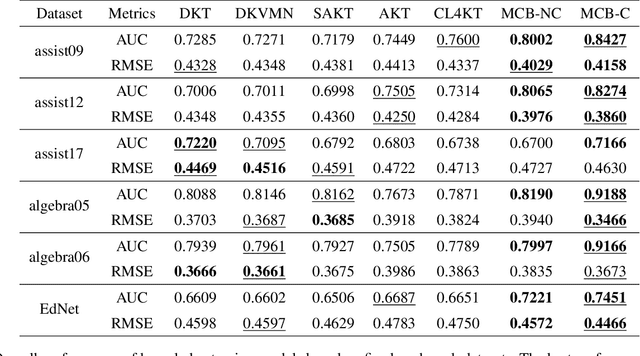
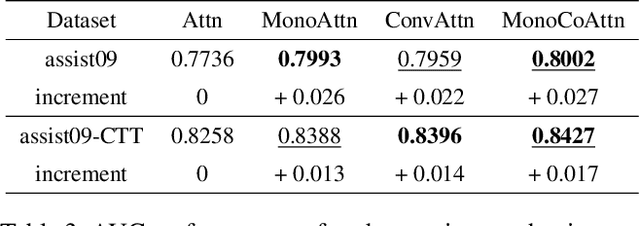
Knowledge tracing (KT) is a field of study that predicts the future performance of students based on prior performance datasets collected from educational applications such as intelligent tutoring systems, learning management systems, and online courses. Some previous studies on KT have concentrated only on the interpretability of the model, whereas others have focused on enhancing the performance. Models that consider both interpretability and the performance improvement have been insufficient. Moreover, models that focus on performance improvements have not shown an overwhelming performance compared with existing models. In this study, we propose MonaCoBERT, which achieves the best performance on most benchmark datasets and has significant interpretability. MonaCoBERT uses a BERT-based architecture with monotonic convolutional multihead attention, which reflects forgetting behavior of the students and increases the representation power of the model. We can also increase the performance and interpretability using a classical test-theory-based (CTT-based) embedding strategy that considers the difficulty of the question. To determine why MonaCoBERT achieved the best performance and interpret the results quantitatively, we conducted ablation studies and additional analyses using Grad-CAM, UMAP, and various visualization techniques. The analysis results demonstrate that both attention components complement one another and that CTT-based embedding represents information on both global and local difficulties. We also demonstrate that our model represents the relationship between concepts.