 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedagogy-R1: Pedagogically-Aligned Reasoning Model with Balanced Educational Benchmark
May 24, 2025Recent advances in large reasoning models (LRMs) show strong performance in structured domains such as mathematics and programming; however, they often lack pedagogical coherence and realistic teaching behaviors. To bridge this gap, we introduce Pedagogy-R1, a framework that adapts LRMs for classroom use through three innovations: (1) a distillation-based pipeline that filters and refines model outputs for instruction-tuning, (2) the Well-balanced Educational Benchmark (WBEB), which evaluates performance across subject knowledge, pedagogical knowledge, tracing, essay scoring, and teacher decision-making, and (3) a Chain-of-Pedagogy (CoP) prompting strategy for generating and eliciting teacher-style reasoning. Our mixed-method evaluation combines quantitative metrics with qualitative analysis, providing the first systematic assessment of LRMs' pedagogical strengths and limitations.
From Prediction to Application: Language Model-based Code Knowledge Tracing with Domain Adaptive Pre-Training and Automatic Feedback System with Pedagogical Prompting for Comprehensive Programming Education
Aug 31, 2024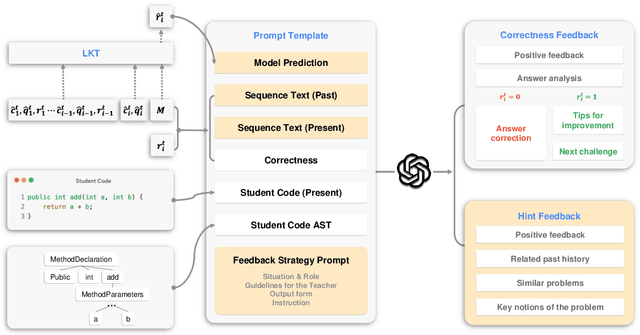
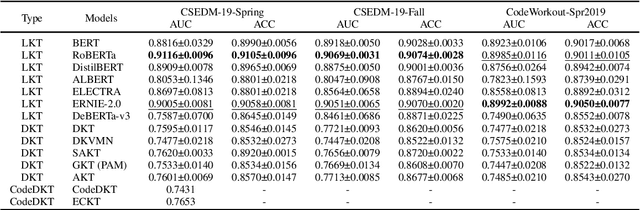
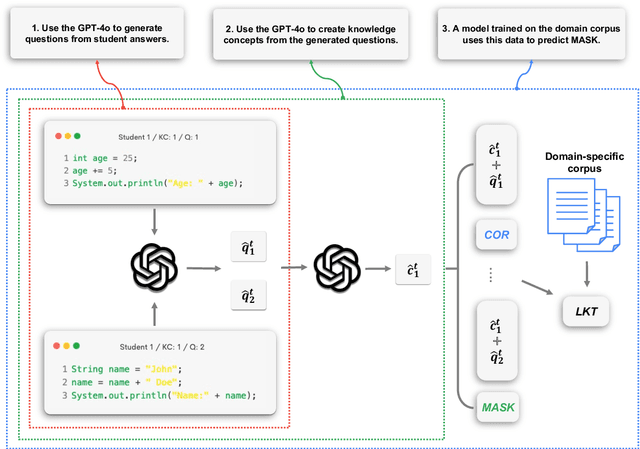
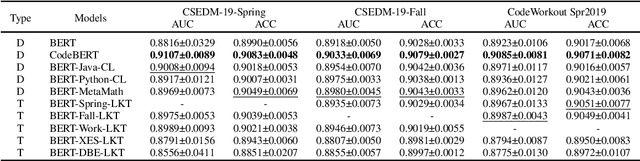
Knowledge Tracing (KT) is a critical component in online learning, but traditional approaches face limitations in interpretability and cross-domain adaptability. This paper introduces Language Model-based Code Knowledge Tracing (CodeLKT), an innovative application of Language model-based Knowledge Tracing (LKT) to programming education. CodeLKT leverages pre-trained language models to process learning data, demonstrating superior performance over existing KT and Code KT models. We explore Domain Adaptive Pre-Training (DAPT) and Task Adaptive Pre-Training (TAPT), showing enhanced performance in the coding domain and investigating cross-domain transfer between mathematics and coding. Additionally, we present an theoretically-informed integrated system combining CodeLKT with large language models to generate personalized, in-depth feedback to support students' programming learning. This work advances the field of Code Knowledge Tracing by expanding the knowledge base with language model-based approach and offering practical implications for programming education through data-informed feedback.
Language Model Can Do Knowledge Tracing: Simple but Effective Method to Integrate Language Model and Knowledge Tracing Task
Jun 05, 2024Knowledge Tracing (KT) is a critical task in online learning for modeling student knowledge over time. Despite the success of deep learning-based KT models, which rely on sequences of numbers as data, most existing approaches fail to leverage the rich semantic information in the text of questions and concepts. This paper proposes Language model-based Knowledge Tracing (LKT), a novel framework that integrates pre-trained language models (PLMs) with KT methods. By leveraging the power of language models to capture semantic representations, LKT effectively incorporates textual information and significantly outperforms previous KT models on large benchmark datasets. Moreover, we demonstrate that LKT can effectively address the cold-start problem in KT by leveraging the semantic knowledge captured by PLMs. Interpretability of LKT is enhanced compared to traditional KT models due to its use of text-rich data. We conducted the local interpretable model-agnostic explanation technique and analysis of attention scores to interpret the model performance further. Our work highlights the potential of integrating PLMs with KT and paves the way for future research in KT domain.
Automatic Speech Recognition (ASR) for the Diagnosis of pronunciation of Speech Sound Disorders in Korean children
Mar 13, 2024



This study presents a model of automatic speech recognition (ASR) designed to diagnose pronunciation issues in children with speech sound disorders (SSDs) to replace manual transcriptions in clinical procedures. Since ASR models trained for general purposes primarily predict input speech into real words, employing a well-known high-performance ASR model for evaluating pronunciation in children with SSDs is impractical. We fine-tuned the wav2vec 2.0 XLS-R model to recognize speech as pronounced rather than as existing words. The model was fine-tuned with a speech dataset from 137 children with inadequate speech production pronouncing 73 Korean words selected for actual clinical diagnosis. The model's predictions of the pronunciations of the words matched the human annotations with about 90% accuracy. While the model still requires improvement in recognizing unclear pronunciation, this study demonstrates that ASR models can streamline complex pronunciation error diagnostic procedures in clinical fields.