 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonaCoBERT: Monotonic attention based ConvBERT for Knowledge Tracing
Paper and Code
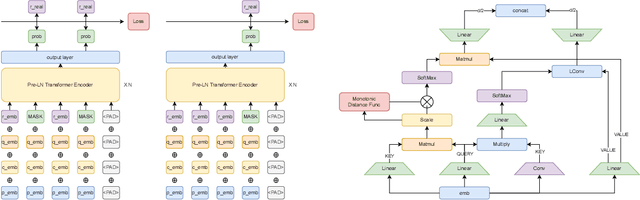
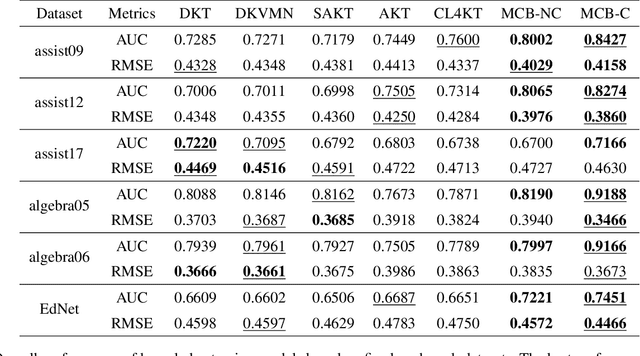
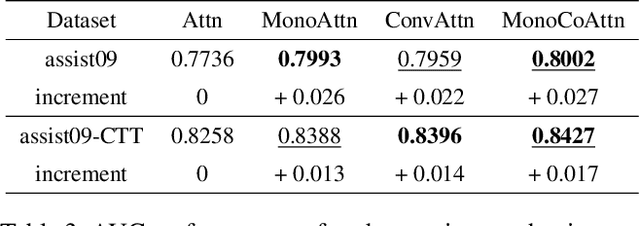
Knowledge tracing (KT) is a field of study that predicts the future performance of students based on prior performance datasets collected from educational applications such as intelligent tutoring systems, learning management systems, and online courses. Some previous studies on KT have concentrated only on the interpretability of the model, whereas others have focused on enhancing the performance. Models that consider both interpretability and the performance improvement have been insufficient. Moreover, models that focus on performance improvements have not shown an overwhelming performance compared with existing models. In this study, we propose MonaCoBERT, which achieves the best performance on most benchmark datasets and has significant interpretability. MonaCoBERT uses a BERT-based architecture with monotonic convolutional multihead attention, which reflects forgetting behavior of the students and increases the representation power of the model. We can also increase the performance and interpretability using a classical test-theory-based (CTT-based) embedding strategy that considers the difficulty of the question. To determine why MonaCoBERT achieved the best performance and interpret the results quantitatively, we conducted ablation studies and additional analyses using Grad-CAM, UMAP, and various visualization techniques. The analysis results demonstrate that both attention components complement one another and that CTT-based embedding represents information on both global and local difficulties. We also demonstrate that our model represents the relationship between concepts.