 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBastion: Budget-Aware Speculative Decoding with Tree-structured Block Diffusion Drafting
May 28, 2026Block-diffusion drafters have recently emerged as a powerful alternative for speculative decoding by predicting multiple future-token distributions in a single parallel step. However, since these parallel predictions are sampled from position-wise marginals rather than fully conditioned sequences, committing to a single greedy path often fails to capture the target model's preferred trajectory. To address this, we propose BASTION, a budget-aware speculative decoding framework with tree-based diffusion drafting. Unlike existing methods that rely on static tree topologies, BASTION dynamically constructs query-dependent trees by balancing draft quality against hardware constraints. Our framework integrates three synergistic components: (1) an acceptance surrogate that estimates expected accepted length via path confidence, (2) an online latency estimator that calibrates a hardware-aware roofline model, and (3) an adaptive best-first expansion that grows the tree until marginal gains no longer justify incremental verification costs. BASTION is training-free, preserves the target model's distribution, and requires no per-setting tuning. Across diverse benchmarks and GPU architectures, BASTION achieves up to a 6.61x speedup over standard autoregressive decoding, outperforming state-of-the-art block-diffusion baselines by 39%.
The PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
Multi-Robot Motion Planning from Vision and Language using Heat-Inspired Diffusion
Dec 15, 2025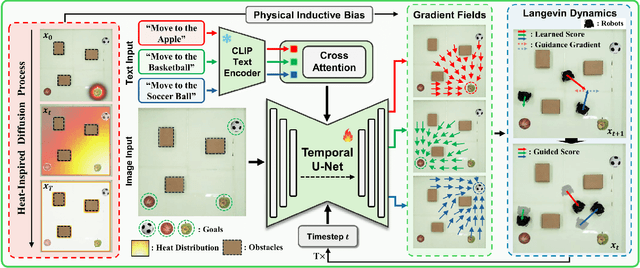

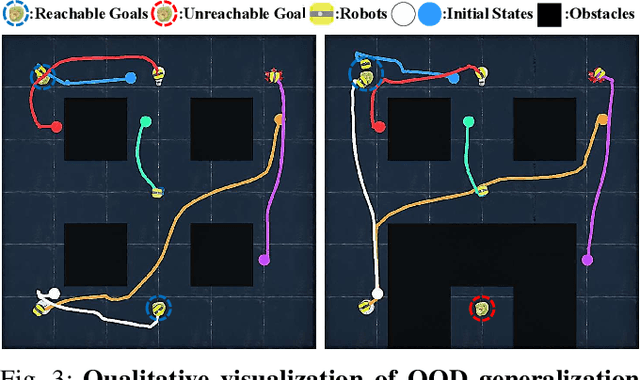
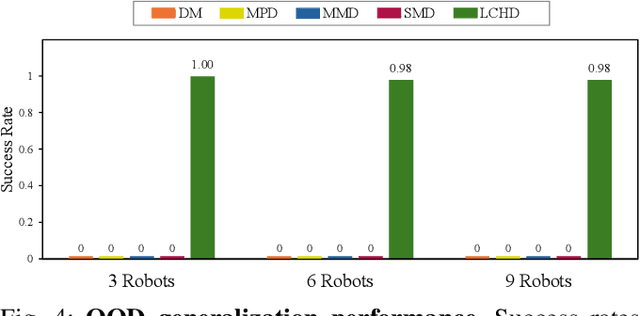
Diffusion models have recently emerged as powerful tools for robot motion planning by capturing the multi-modal distribution of feasible trajectories. However, their extension to multi-robot settings with flexible, language-conditioned task specifications remains limited. Furthermore, current diffusion-based approaches incur high computational cost during inference and struggle with generalization because they require explicit construction of environment representations and lack mechanisms for reasoning about geometric reachability. To address these limitations, we present Language-Conditioned Heat-Inspired Diffusion (LCHD), an end-to-end vision-based framework that generates language-conditioned, collision-free trajectories. LCHD integrates CLIP-based semantic priors with a collision-avoiding diffusion kernel serving as a physical inductive bias that enables the planner to interpret language commands strictly within the reachable workspace. This naturally handles out-of-distribution scenarios -- in terms of reachability -- by guiding robots toward accessible alternatives that match the semantic intent, while eliminating the need for explicit obstacle information at inference time. Extensive evaluations on diverse real-world-inspired maps, along with real-robot experiments, show that LCHD consistently outperforms prior diffusion-based planners in success rate, while reducing planning latency.
MMM: Quantum-Chemical Molecular Representation Learning for Combinatorial Drug Recommendation
Oct 09, 2025Drug recommendation is an essential task in machine learning-based clinical decision support systems. However, the risk of drug-drug interactions (DDI) between co-prescribed medications remains a significant challenge. Previous studies have used graph neural networks (GNNs) to represent drug structures. Regardless, their simplified discrete forms cannot fully capture the molecular binding affinity and reactivity. Therefore, we propose Multimodal DDI Prediction with Molecular Electron Localization Function (ELF) Maps (MMM), a novel framework that integrates three-dimensional (3D) quantum-chemical information into drug representation learning. It generates 3D electron density maps using the ELF. To capture both therapeutic relevance and interaction risks, MMM combines ELF-derived features that encode global electronic properties with a bipartite graph encoder that models local substructure interactions. This design enables learning complementary characteristics of drug molecules. We evaluate MMM in the MIMIC-III dataset (250 drugs, 442 substructures), comparing it with several baseline models. In particular, a comparison with the GNN-based SafeDrug model demonstrates statistically significant improvements in the F1-score (p = 0.0387), Jaccard (p = 0.0112), and the DDI rate (p = 0.0386). These results demonstrate the potential of ELF-based 3D representations to enhance prediction accuracy and support safer combinatorial drug prescribing in clinical practice.
Multi-channel convolutional neural quantum embedding
Sep 26, 2025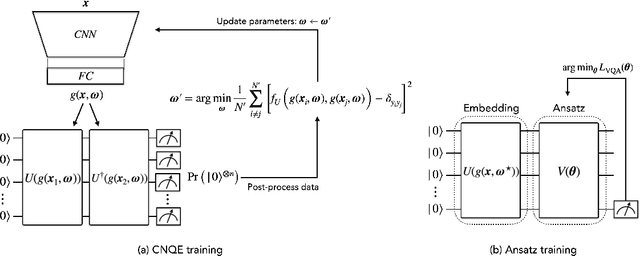
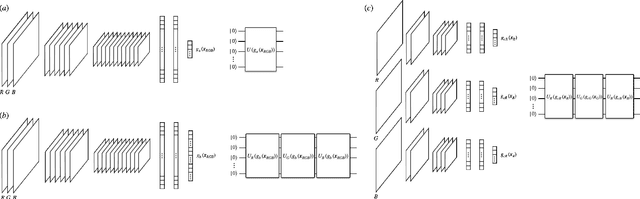
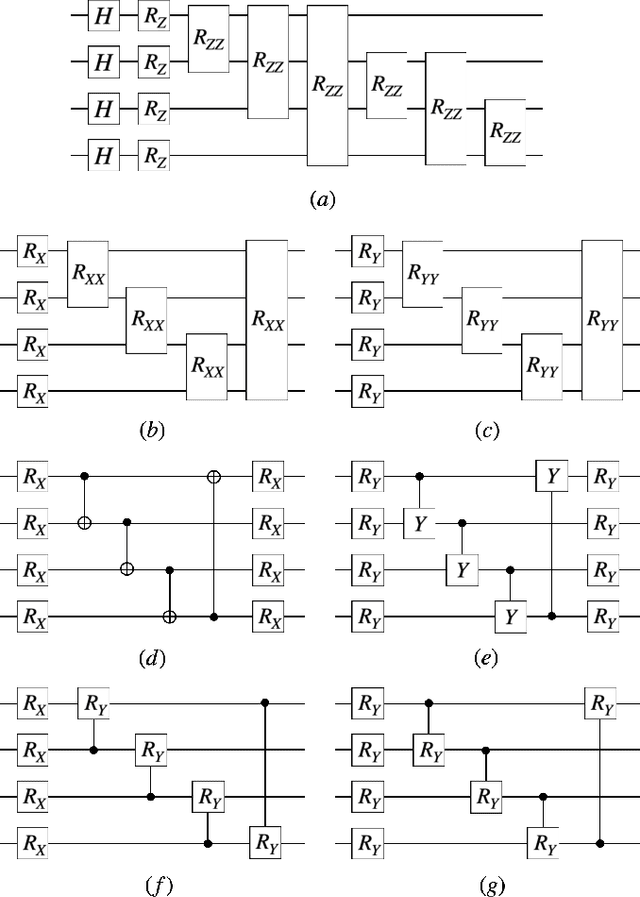
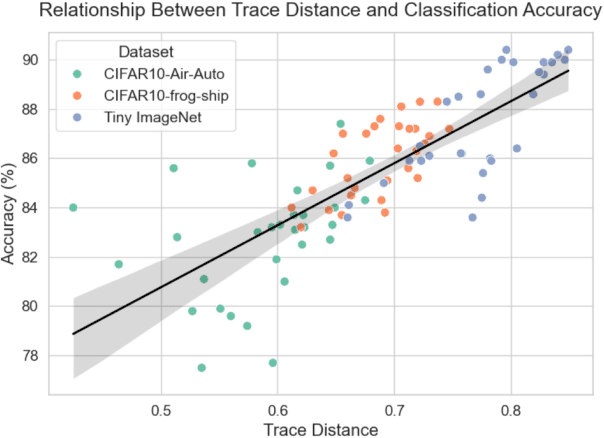
Classification using variational quantum circuits is a promising frontier in quantum machine learning. Quantum supervised learning (QSL) applied to classical data using variational quantum circuits involves embedding the data into a quantum Hilbert space and optimizing the circuit parameters to train the measurement process. In this context, the efficacy of QSL is inherently influenced by the selection of quantum embedding. In this study, we introduce a classical-quantum hybrid approach for optimizing quantum embedding beyond the limitations of the standard circuit model of quantum computation (i.e., completely positive and trace-preserving maps) for general multi-channel data. We benchmark the performance of various models in our framework using the CIFAR-10 and Tiny ImageNet datasets and provide theoretical analyses that guide model design and optimization.
Exploring Multimodal Diffusion Transformers for Enhanced Prompt-based Image Editing
Aug 11, 2025Transformer-based diffusion models have recently superseded traditional U-Net architectures, with multimodal diffusion transformers (MM-DiT) emerging as the dominant approach in state-of-the-art models like Stable Diffusion 3 and Flux.1. Previous approaches have relied on unidirectional cross-attention mechanisms, with information flowing from text embeddings to image latents. In contrast, MMDiT introduces a unified attention mechanism that concatenates input projections from both modalities and performs a single full attention operation, allowing bidirectional information flow between text and image branches. This architectural shift presents significant challenges for existing editing techniques. In this paper, we systematically analyze MM-DiT's attention mechanism by decomposing attention matrices into four distinct blocks, revealing their inherent characteristics. Through these analyses, we propose a robust, prompt-based image editing method for MM-DiT that supports global to local edits across various MM-DiT variants, including few-step models. We believe our findings bridge the gap between existing U-Net-based methods and emerging architectures, offering deeper insights into MMDiT's behavioral patterns.
When Model Knowledge meets Diffusion Model: Diffusion-assisted Data-free Image Synthesis with Alignment of Domain and Class
Jun 18, 2025Open-source pre-trained models hold great potential for diverse applications, but their utility declines when their training data is unavailable. Data-Free Image Synthesis (DFIS) aims to generate images that approximate the learned data distribution of a pre-trained model without accessing the original data. However, existing DFIS meth ods produce samples that deviate from the training data distribution due to the lack of prior knowl edge about natural images. To overcome this limitation, we propose DDIS, the first Diffusion-assisted Data-free Image Synthesis method that leverages a text-to-image diffusion model as a powerful image prior, improving synthetic image quality. DDIS extracts knowledge about the learned distribution from the given model and uses it to guide the diffusion model, enabling the generation of images that accurately align with the training data distribution. To achieve this, we introduce Domain Alignment Guidance (DAG) that aligns the synthetic data domain with the training data domain during the diffusion sampling process. Furthermore, we optimize a single Class Alignment Token (CAT) embedding to effectively capture class-specific attributes in the training dataset. Experiments on PACS and Ima geNet demonstrate that DDIS outperforms prior DFIS methods by generating samples that better reflect the training data distribution, achieving SOTA performance in data-free applications.
Distilling Realizable Students from Unrealizable Teachers
May 14, 2025



We study policy distillation under privileged information, where a student policy with only partial observations must learn from a teacher with full-state access. A key challenge is information asymmetry: the student cannot directly access the teacher's state space, leading to distributional shifts and policy degradation. Existing approaches either modify the teacher to produce realizable but sub-optimal demonstrations or rely on the student to explore missing information independently, both of which are inefficient. Our key insight is that the student should strategically interact with the teacher --querying only when necessary and resetting from recovery states --to stay on a recoverable path within its own observation space. We introduce two methods: (i) an imitation learning approach that adaptively determines when the student should query the teacher for corrections, and (ii) a reinforcement learning approach that selects where to initialize training for efficient exploration. We validate our methods in both simulated and real-world robotic tasks, demonstrating significant improvements over standard teacher-student baselines in training efficiency and final performance. The project website is available at : https://portal-cornell.github.io/CritiQ_ReTRy/
Guiding Reasoning in Small Language Models with LLM Assistance
Apr 14, 2025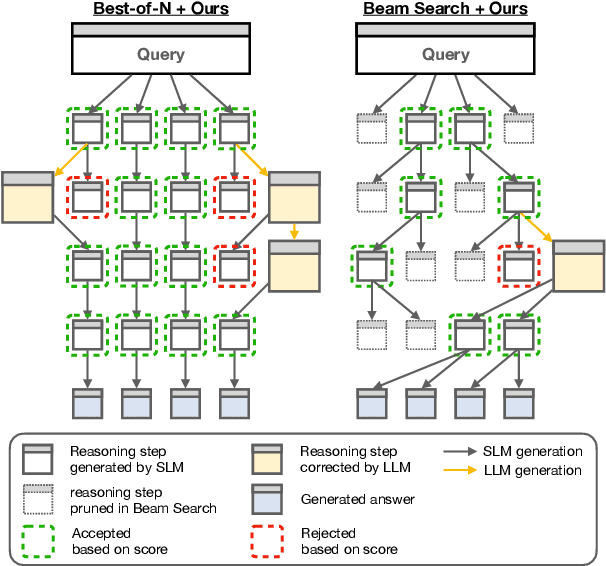
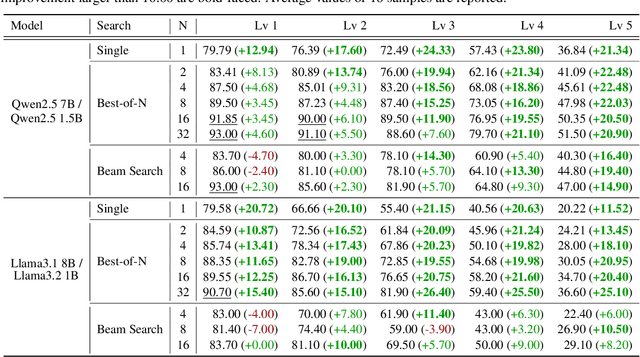
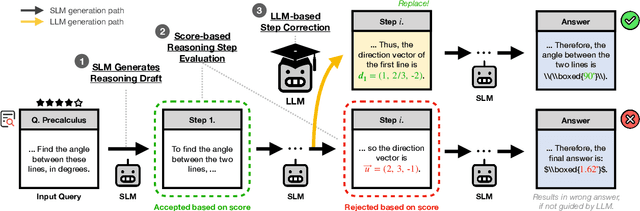

The limited reasoning capabilities of small language models (SLMs) cast doubt on their suitability for tasks demanding deep, multi-step logical deduction. This paper introduces a framework called Small Reasons, Large Hints (SMART), which selectively augments SLM reasoning with targeted guidance from large language models (LLMs). Inspired by the concept of cognitive scaffolding, SMART employs a score-based evaluation to identify uncertain reasoning steps and injects corrective LLM-generated reasoning only when necessary. By framing structured reasoning as an optimal policy search, our approach steers the reasoning trajectory toward correct solutions without exhaustive sampling. Our experiments on mathematical reasoning datasets demonstrate that targeted external scaffolding significantly improves performance, paving the way for collaborative use of both SLM and LLM to tackle complex reasoning tasks that are currently unsolvable by SLMs alone.
Evaluating Visual Explanations of Attention Maps for Transformer-based Medical Imaging
Mar 12, 2025Although Vision Transformers (ViTs) have recently demonstrated superior performance in medical imaging problems, they face explainability issues similar to previous architectures such as convolutional neural networks. Recent research efforts suggest that attention maps, which are part of decision-making process of ViTs can potentially address the explainability issue by identifying regions influencing predictions, especially in models pretrained with self-supervised learning. In this work, we compare the visual explanations of attention maps to other commonly used methods for medical imaging problems. To do so, we employ four distinct medical imaging datasets that involve the identification of (1) colonic polyps, (2) breast tumors, (3) esophageal inflammation, and (4) bone fractures and hardware implants. Through large-scale experiments on the aforementioned datasets using various supervised and self-supervised pretrained ViTs, we find that although attention maps show promise under certain conditions and generally surpass GradCAM in explainability, they are outperformed by transformer-specific interpretability methods. Our findings indicate that the efficacy of attention maps as a method of interpretability is context-dependent and may be limited as they do not consistently provide the comprehensive insights required for robust medical decision-making.