 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Reasoning in Small Language Models with LLM Assistance
Paper and Code
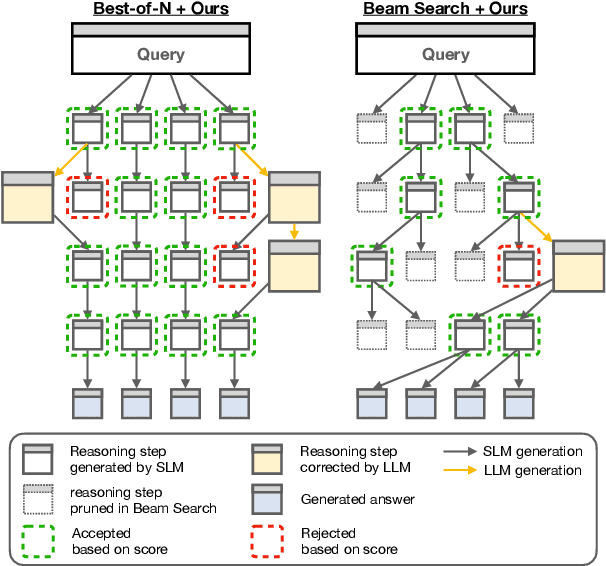
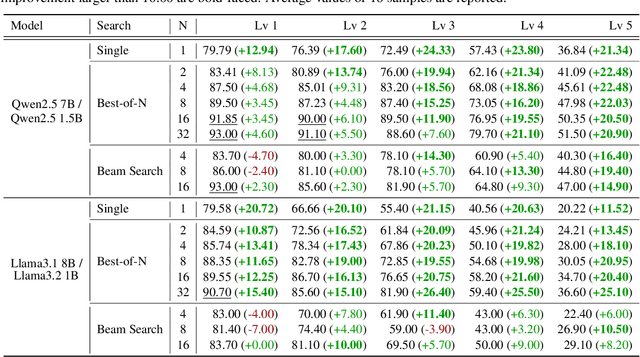
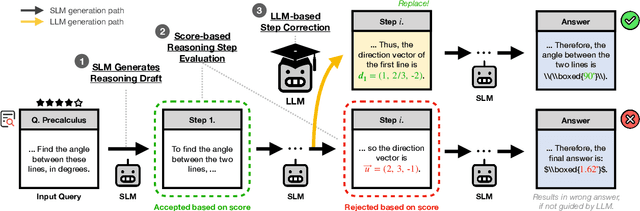

The limited reasoning capabilities of small language models (SLMs) cast doubt on their suitability for tasks demanding deep, multi-step logical deduction. This paper introduces a framework called Small Reasons, Large Hints (SMART), which selectively augments SLM reasoning with targeted guidance from large language models (LLMs). Inspired by the concept of cognitive scaffolding, SMART employs a score-based evaluation to identify uncertain reasoning steps and injects corrective LLM-generated reasoning only when necessary. By framing structured reasoning as an optimal policy search, our approach steers the reasoning trajectory toward correct solutions without exhaustive sampling. Our experiments on mathematical reasoning datasets demonstrate that targeted external scaffolding significantly improves performance, paving the way for collaborative use of both SLM and LLM to tackle complex reasoning tasks that are currently unsolvable by SLMs alone.