 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multi-Robot Networks via MLLM-Driven Sensing, Communication, and Computation: A Comprehensive Survey
Mar 31, 2026Imagine advanced humanoid robots, powered by multimodal large language models (MLLMs), coordinating missions across industries like warehouse logistics, manufacturing, and safety rescue. While individual robots show local autonomy, realistic tasks demand coordination among multiple agents sharing vast streams of sensor data. Communication is indispensable, yet transmitting comprehensive data can overwhelm networks, especially when a system-level orchestrator or cloud-based MLLM fuses multimodal inputs for route planning or anomaly detection. These tasks are often initiated by high-level natural language instructions. This intent serves as a filter for resource optimization: by understanding the goal via MLLMs, the system can selectively activate relevant sensing modalities, dynamically allocate bandwidth, and determine computation placement. Thus, R2X is fundamentally an intent-to-resource orchestration problem where sensing, communication, and computation are jointly optimized to maximize task-level success under resource constraints. This survey examines how integrated design paves the way for multi-robot coordination under MLLM guidance. We review state-of-the-art sensing modalities, communication strategies, and computing approaches, highlighting how reasoning is split between on-device models and powerful edge/cloud servers. We present four end-to-end demonstrations (sense -> communicate -> compute -> act): (i) digital-twin warehouse navigation with predictive link context, (ii) mobility-driven proactive MCS control, (iii) a FollowMe robot with a semantic-sensing switch, and (iv) real-hardware open-vocabulary trash sorting via edge-assisted MLLM grounding. We emphasize system-level metrics -- payload, latency, and success -- to show why R2X orchestration outperforms purely on-device baselines.
Correlation-Weighted Multi-Reward Optimization for Compositional Generation
Mar 19, 2026Text-to-image models produce images that align well with natural language prompts, but compositional generation has long been a central challenge. Models often struggle to satisfy multiple concepts within a single prompt, frequently omitting some concepts and resulting in partial success. Such failures highlight the difficulty of jointly optimizing multiple concepts during reward optimization, where competing concepts can interfere with one another. To address this limitation, we propose Correlation-Weighted Multi-Reward Optimization (\ours), a framework that leverages the correlation structure among concept rewards to adaptively weight each attribute concept in optimization. By accounting for interactions among concepts, \ours balances competing reward signals and emphasizes concepts that are partially satisfied yet inconsistently generated across samples, improving compositional generation. Specifically, we decompose multi-concept prompts into pre-defined concept groups (\eg, objects, attributes, and relations) and obtain reward signals from dedicated reward models for each concept. We then adaptively reweight these rewards, assigning higher weights to conflicting or hard-to-satisfy concepts using correlation-based difficulty estimation. By focusing optimization on the most challenging concepts within each group, \ours encourages the model to consistently satisfy all requested attributes simultaneously. We apply our approach to train state-of-the-art diffusion models, SD3.5 and FLUX.1-dev, and demonstrate consistent improvements on challenging multi-concept benchmarks, including ConceptMix, GenEval 2, and T2I-CompBench.
Consistency-Preserving Concept Erasure via Unsafe-Safe Pairing and Directional Fisher-weighted Adaptation
Feb 05, 2026With the increasing versatility of text-to-image diffusion models, the ability to selectively erase undesirable concepts (e.g., harmful content) has become indispensable. However, existing concept erasure approaches primarily focus on removing unsafe concepts without providing guidance toward corresponding safe alternatives, which often leads to failure in preserving the structural and semantic consistency between the original and erased generations. In this paper, we propose a novel framework, PAIRed Erasing (PAIR), which reframes concept erasure from simple removal to consistency-preserving semantic realignment using unsafe-safe pairs. We first generate safe counterparts from unsafe inputs while preserving structural and semantic fidelity, forming paired unsafe-safe multimodal data. Leveraging these pairs, we introduce two key components: (1) Paired Semantic Realignment, a guided objective that uses unsafe-safe pairs to explicitly map target concepts to semantically aligned safe anchors; and (2) Fisher-weighted Initialization for DoRA, which initializes parameter-efficient low-rank adaptation matrices using unsafe-safe pairs, encouraging the generation of safe alternatives while selectively suppressing unsafe concepts. Together, these components enable fine-grained erasure that removes only the targeted concepts while maintaining overall semantic consistency. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art baselines, achieving effective concept erasure while preserving structural integrity, semantic coherence, and generation quality.
Neural Particle Automata: Learning Self-Organizing Particle Dynamics
Jan 22, 2026We introduce Neural Particle Automata (NPA), a Lagrangian generalization of Neural Cellular Automata (NCA) from static lattices to dynamic particle systems. Unlike classical Eulerian NCA where cells are pinned to pixels or voxels, NPA model each cell as a particle with a continuous position and internal state, both updated by a shared, learnable neural rule. This particle-based formulation yields clear individuation of cells, allows heterogeneous dynamics, and concentrates computation only on regions where activity is present. At the same time, particle systems pose challenges: neighborhoods are dynamic, and a naive implementation of local interactions scale quadratically with the number of particles. We address these challenges by replacing grid-based neighborhood perception with differentiable Smoothed Particle Hydrodynamics (SPH) operators backed by memory-efficient, CUDA-accelerated kernels, enabling scalable end-to-end training. Across tasks including morphogenesis, point-cloud classification, and particle-based texture synthesis, we show that NPA retain key NCA behaviors such as robustness and self-regeneration, while enabling new behaviors specific to particle systems. Together, these results position NPA as a compact neural model for learning self-organizing particle dynamics.
MergeRec: Model Merging for Data-Isolated Cross-Domain Sequential Recommendation
Jan 05, 2026Modern recommender systems trained on domain-specific data often struggle to generalize across multiple domains. Cross-domain sequential recommendation has emerged as a promising research direction to address this challenge; however, existing approaches face fundamental limitations, such as reliance on overlapping users or items across domains, or unrealistic assumptions that ignore privacy constraints. In this work, we propose a new framework, MergeRec, based on model merging under a new and realistic problem setting termed data-isolated cross-domain sequential recommendation, where raw user interaction data cannot be shared across domains. MergeRec consists of three key components: (1) merging initialization, (2) pseudo-user data construction, and (3) collaborative merging optimization. First, we initialize a merged model using training-free merging techniques. Next, we construct pseudo-user data by treating each item as a virtual sequence in each domain, enabling the synthesis of meaningful training samples without relying on real user interactions. Finally, we optimize domain-specific merging weights through a joint objective that combines a recommendation loss, which encourages the merged model to identify relevant items, and a distillation loss, which transfers collaborative filtering signals from the fine-tuned source models. Extensive experiments demonstrate that MergeRec not only preserves the strengths of the original models but also significantly enhances generalizability to unseen domains. Compared to conventional model merging methods, MergeRec consistently achieves superior performance, with average improvements of up to 17.21% in Recall@10, highlighting the potential of model merging as a scalable and effective approach for building universal recommender systems. The source code is available at https://github.com/DIALLab-SKKU/MergeRec.
Large Multimodal Models-Empowered Task-Oriented Autonomous Communications: Design Methodology and Implementation Challenges
Oct 23, 2025Large language models (LLMs) and large multimodal models (LMMs) have achieved unprecedented breakthrough, showcasing remarkable capabilities in natural language understanding, generation, and complex reasoning. This transformative potential has positioned them as key enablers for 6G autonomous communications among machines, vehicles, and humanoids. In this article, we provide an overview of task-oriented autonomous communications with LLMs/LMMs, focusing on multimodal sensing integration, adaptive reconfiguration, and prompt/fine-tuning strategies for wireless tasks. We demonstrate the framework through three case studies: LMM-based traffic control, LLM-based robot scheduling, and LMM-based environment-aware channel estimation. From experimental results, we show that the proposed LLM/LMM-aided autonomous systems significantly outperform conventional and discriminative deep learning (DL) model-based techniques, maintaining robustness under dynamic objectives, varying input parameters, and heterogeneous multimodal conditions where conventional static optimization degrades.
When Model Knowledge meets Diffusion Model: Diffusion-assisted Data-free Image Synthesis with Alignment of Domain and Class
Jun 18, 2025Open-source pre-trained models hold great potential for diverse applications, but their utility declines when their training data is unavailable. Data-Free Image Synthesis (DFIS) aims to generate images that approximate the learned data distribution of a pre-trained model without accessing the original data. However, existing DFIS meth ods produce samples that deviate from the training data distribution due to the lack of prior knowl edge about natural images. To overcome this limitation, we propose DDIS, the first Diffusion-assisted Data-free Image Synthesis method that leverages a text-to-image diffusion model as a powerful image prior, improving synthetic image quality. DDIS extracts knowledge about the learned distribution from the given model and uses it to guide the diffusion model, enabling the generation of images that accurately align with the training data distribution. To achieve this, we introduce Domain Alignment Guidance (DAG) that aligns the synthetic data domain with the training data domain during the diffusion sampling process. Furthermore, we optimize a single Class Alignment Token (CAT) embedding to effectively capture class-specific attributes in the training dataset. Experiments on PACS and Ima geNet demonstrate that DDIS outperforms prior DFIS methods by generating samples that better reflect the training data distribution, achieving SOTA performance in data-free applications.
Difference Inversion: Interpolate and Isolate the Difference with Token Consistency for Image Analogy Generation
Jun 09, 2025How can we generate an image B' that satisfies A:A'::B:B', given the input images A,A' and B? Recent works have tackled this challenge through approaches like visual in-context learning or visual instruction. However, these methods are typically limited to specific models (e.g. InstructPix2Pix. Inpainting models) rather than general diffusion models (e.g. Stable Diffusion, SDXL). This dependency may lead to inherited biases or lower editing capabilities. In this paper, we propose Difference Inversion, a method that isolates only the difference from A and A' and applies it to B to generate a plausible B'. To address model dependency, it is crucial to structure prompts in the form of a "Full Prompt" suitable for input to stable diffusion models, rather than using an "Instruction Prompt". To this end, we accurately extract the Difference between A and A' and combine it with the prompt of B, enabling a plug-and-play application of the difference. To extract a precise difference, we first identify it through 1) Delta Interpolation. Additionally, to ensure accurate training, we propose the 2) Token Consistency Loss and 3) Zero Initialization of Token Embeddings. Our extensive experiments demonstrate that Difference Inversion outperforms existing baselines both quantitatively and qualitatively, indicating its ability to generate more feasible B' in a model-agnostic manner.
Ultra-reliable urban air mobility networks
Oct 23, 2024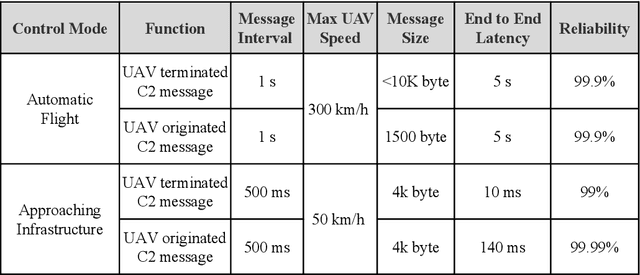



Recently, urban air mobility (UAM) has attracted attention as an emerging technology that will bring innovation to urban transportation and aviation systems. Since the UAM systems pursue fully autonomous flight without a pilot, wireless communication is a key function not only for flight control signals, but also for navigation and safety information. The essential information is called a command and control (C2) message, and the UAM networks must be configured so that the UAM can receive the C2 message by securing a continuous link stability without any interruptions. Nevertheless, a lot of prior works have focused only on improving the average performance without solving the low-reliability in the cell edges and coverage holes of urban areas. In this dissertation, we identify the factors that hinder the communication link reliability in considering three-dimensional (3D) urban environments, and propose a antenna configuration, resource utilization, and transmission strategy to enable UAM receiving C2 messages regardless of time and space. First, through stochastic geometry modeling, we analyze the signal blockage effects caused by the urban buildings. The blockage probability is calculated according to the shape, height, and density of the buildings, and the coverage probability of the received signal is derived by reflecting the blockage events. Furthermore, the low-reliability area is identified by analyzing the coverage performance according to the positions of the UAMs. To overcome the low-reliability region, we propose three methods for UAM network operation: i) optimization of antennas elevation tilting, ii) frequency reuse with multi-layered narrow beam, and iii) assistive transmissions by the master UAM.
MARS: Matching Attribute-aware Representations for Text-based Sequential Recommendation
Sep 04, 2024Sequential recommendation aims to predict the next item a user is likely to prefer based on their sequential interaction history. Recently, text-based sequential recommendation has emerged as a promising paradigm that uses pre-trained language models to exploit textual item features to enhance performance and facilitate knowledge transfer to unseen datasets. However, existing text-based recommender models still struggle with two key challenges: (i) representing users and items with multiple attributes, and (ii) matching items with complex user interests. To address these challenges, we propose a novel model, Matching Attribute-aware Representations for Text-based Sequential Recommendation (MARS). MARS extracts detailed user and item representations through attribute-aware text encoding, capturing diverse user intents with multiple attribute-aware representations. It then computes user-item scores via attribute-wise interaction matching, effectively capturing attribute-level user preferences. Our extensive experiments demonstrate that MARS significantly outperforms existing sequential models, achieving improvements of up to 24.43% and 29.26% in Recall@10 and NDCG@10 across five benchmark datasets. Code is available at https://github.com/junieberry/MARS