 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterous World Models
Dec 19, 2025



Recent progress in 3D reconstruction has made it easy to create realistic digital twins from everyday environments. However, current digital twins remain largely static and are limited to navigation and view synthesis without embodied interactivity. To bridge this gap, we introduce Dexterous World Model (DWM), a scene-action-conditioned video diffusion framework that models how dexterous human actions induce dynamic changes in static 3D scenes. Given a static 3D scene rendering and an egocentric hand motion sequence, DWM generates temporally coherent videos depicting plausible human-scene interactions. Our approach conditions video generation on (1) static scene renderings following a specified camera trajectory to ensure spatial consistency, and (2) egocentric hand mesh renderings that encode both geometry and motion cues to model action-conditioned dynamics directly. To train DWM, we construct a hybrid interaction video dataset. Synthetic egocentric interactions provide fully aligned supervision for joint locomotion and manipulation learning, while fixed-camera real-world videos contribute diverse and realistic object dynamics. Experiments demonstrate that DWM enables realistic and physically plausible interactions, such as grasping, opening, and moving objects, while maintaining camera and scene consistency. This framework represents a first step toward video diffusion-based interactive digital twins and enables embodied simulation from egocentric actions.
Target-Aware Video Diffusion Models
Mar 24, 2025We present a target-aware video diffusion model that generates videos from an input image in which an actor interacts with a specified target while performing a desired action. The target is defined by a segmentation mask and the desired action is described via a text prompt. Unlike existing controllable image-to-video diffusion models that often rely on dense structural or motion cues to guide the actor's movements toward the target, our target-aware model requires only a simple mask to indicate the target, leveraging the generalization capabilities of pretrained models to produce plausible actions. This makes our method particularly effective for human-object interaction (HOI) scenarios, where providing precise action guidance is challenging, and further enables the use of video diffusion models for high-level action planning in applications such as robotics. We build our target-aware model by extending a baseline model to incorporate the target mask as an additional input. To enforce target awareness, we introduce a special token that encodes the target's spatial information within the text prompt. We then fine-tune the model with our curated dataset using a novel cross-attention loss that aligns the cross-attention maps associated with this token with the input target mask. To further improve performance, we selectively apply this loss to the most semantically relevant transformer blocks and attention regions. Experimental results show that our target-aware model outperforms existing solutions in generating videos where actors interact accurately with the specified targets. We further demonstrate its efficacy in two downstream applications: video content creation and zero-shot 3D HOI motion synthesis.
GALA: Generating Animatable Layered Assets from a Single Scan
Jan 23, 2024We present GALA, a framework that takes as input a single-layer clothed 3D human mesh and decomposes it into complete multi-layered 3D assets. The outputs can then be combined with other assets to create novel clothed human avatars with any pose. Existing reconstruction approaches often treat clothed humans as a single-layer of geometry and overlook the inherent compositionality of humans with hairstyles, clothing, and accessories, thereby limiting the utility of the meshes for downstream applications. Decomposing a single-layer mesh into separate layers is a challenging task because it requires the synthesis of plausible geometry and texture for the severely occluded regions. Moreover, even with successful decomposition, meshes are not normalized in terms of poses and body shapes, failing coherent composition with novel identities and poses. To address these challenges, we propose to leverage the general knowledge of a pretrained 2D diffusion model as geometry and appearance prior for humans and other assets. We first separate the input mesh using the 3D surface segmentation extracted from multi-view 2D segmentations. Then we synthesize the missing geometry of different layers in both posed and canonical spaces using a novel pose-guided Score Distillation Sampling (SDS) loss. Once we complete inpainting high-fidelity 3D geometry, we also apply the same SDS loss to its texture to obtain the complete appearance including the initially occluded regions. Through a series of decomposition steps, we obtain multiple layers of 3D assets in a shared canonical space normalized in terms of poses and human shapes, hence supporting effortless composition to novel identities and reanimation with novel poses. Our experiments demonstrate the effectiveness of our approach for decomposition, canonicalization, and composition tasks compared to existing solutions.
NCHO: Unsupervised Learning for Neural 3D Composition of Humans and Objects
May 23, 2023Deep generative models have been recently extended to synthesizing 3D digital humans. However, previous approaches treat clothed humans as a single chunk of geometry without considering the compositionality of clothing and accessories. As a result, individual items cannot be naturally composed into novel identities, leading to limited expressiveness and controllability of generative 3D avatars. While several methods attempt to address this by leveraging synthetic data, the interaction between humans and objects is not authentic due to the domain gap, and manual asset creation is difficult to scale for a wide variety of objects. In this work, we present a novel framework for learning a compositional generative model of humans and objects (backpacks, coats, scarves, and more) from real-world 3D scans. Our compositional model is interaction-aware, meaning the spatial relationship between humans and objects, and the mutual shape change by physical contact is fully incorporated. The key challenge is that, since humans and objects are in contact, their 3D scans are merged into a single piece. To decompose them without manual annotations, we propose to leverage two sets of 3D scans of a single person with and without objects. Our approach learns to decompose objects and naturally compose them back into a generative human model in an unsupervised manner. Despite our simple setup requiring only the capture of a single subject with objects, our experiments demonstrate the strong generalization of our model by enabling the natural composition of objects to diverse identities in various poses and the composition of multiple objects, which is unseen in training data.
Semi-supervised Feature-Level Attribute Manipulation for Fashion Image Retrieval
Jul 11, 2019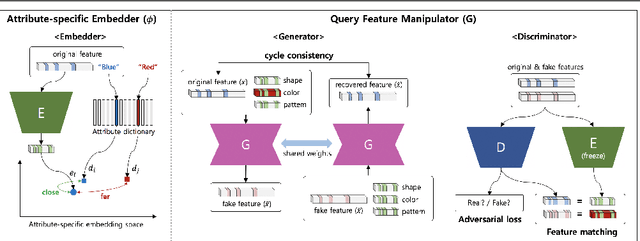
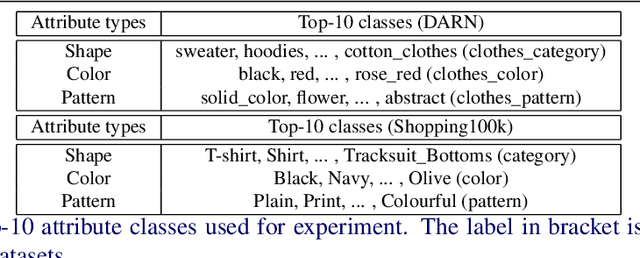

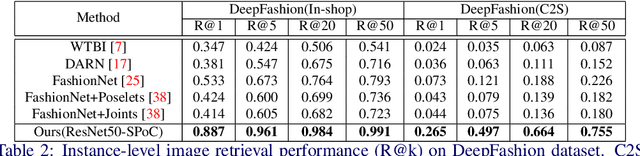
With a growing demand for the search by image, many works have studied the task of fashion instance-level image retrieval (FIR). Furthermore, the recent works introduce a concept of fashion attribute manipulation (FAM) which manipulates a specific attribute (e.g color) of a fashion item while maintaining the rest of the attributes (e.g shape, and pattern). In this way, users can search not only "the same" items but also "similar" items with the desired attributes. FAM is a challenging task in that the attributes are hard to define, and the unique characteristics of a query are hard to be preserved. Although both FIR and FAM are important in real-life applications, most of the previous studies have focused on only one of these problem. In this study, we aim to achieve competitive performance on both FIR and FAM. To do so, we propose a novel method that converts a query into a representation with the desired attributes. We introduce a new idea of attribute manipulation at the feature level, by matching the distribution of manipulated features with real features. In this fashion, the attribute manipulation can be done independently from learning a representation from the image. By introducing the feature-level attribute manipulation, the previous methods for FIR can perform attribute manipulation without sacrificing their retrieval performance.
Unsupervised Visual Attribute Transfer with Reconfigurable Generative Adversarial Networks
Jul 31, 2017



Learning to transfer visual attributes requires supervision dataset. Corresponding images with varying attribute values with the same identity are required for learning the transfer function. This largely limits their applications, because capturing them is often a difficult task. To address the issue, we propose an unsupervised method to learn to transfer visual attribute. The proposed method can learn the transfer function without any corresponding images. Inspecting visualization results from various unsupervised attribute transfer tasks, we verify the effectiveness of the proposed method.
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
May 15, 2017
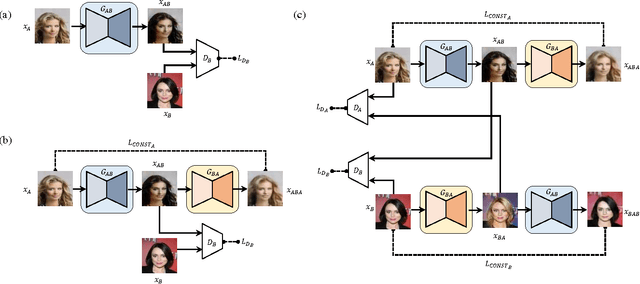
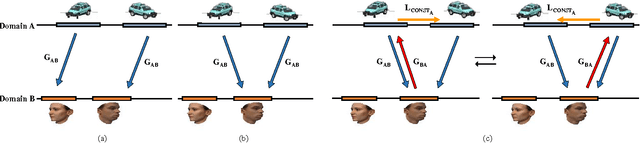
While humans easily recognize relations between data from different domains without any supervision, learning to automatically discover them is in general very challenging and needs many ground-truth pairs that illustrate the relations. To avoid costly pairing, we address the task of discovering cross-domain relations given unpaired data. We propose a method based on generative adversarial networks that learns to discover relations between different domains (DiscoGAN). Using the discovered relations, our proposed network successfully transfers style from one domain to another while preserving key attributes such as orientation and face identity. Source code for official implementation is publicly available https://github.com/SKTBrain/DiscoGAN