 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Active Learning with Gaussian Processes Guided by LLM Relevance Scoring for Dense Passage Retrieval
Apr 20, 2026While Large Language Models (LLMs) exhibit exceptional zero-shot relevance modeling, their high computational cost necessitates framing passage retrieval as a budget-constrained global optimization problem. Existing approaches passively rely on first-stage dense retrievers, which leads to two limitations: (1) failing to retrieve relevant passages in semantically distinct clusters, and (2) failing to propagate relevance signals to the broader corpus. To address these limitations, we propose Bayesian Active Learning with Gaussian Processes guided by LLM relevance scoring (BAGEL), a novel framework that propagates sparse LLM relevance signals across the embedding space to guide global exploration. BAGEL models the multimodal relevance distribution across the entire embedding space with a query-specific Gaussian Process (GP) based on LLM relevance scores. Subsequently, it iteratively selects passages for scoring by strategically balancing the exploitation of high-confidence regions with the exploration of uncertain areas. Extensive experiments across four benchmark datasets and two LLM backbones demonstrate that BAGEL effectively explores and captures complex relevance distributions and outperforms LLM reranking methods under the same LLM budget on all four datasets.
VLM2Rec: Resolving Modality Collapse in Vision-Language Model Embedders for Multimodal Sequential Recommendation
Mar 18, 2026Sequential Recommendation (SR) in multimodal settings typically relies on small frozen pretrained encoders, which limits semantic capacity and prevents Collaborative Filtering (CF) signals from being fully integrated into item representations. Inspired by the recent success of Large Language Models (LLMs) as high-capacity embedders, we investigate the use of Vision-Language Models (VLMs) as CF-aware multimodal encoders for SR. However, we find that standard contrastive supervised fine-tuning (SFT), which adapts VLMs for embedding generation and injects CF signals, can amplify its inherent modality collapse. In this state, optimization is dominated by a single modality while the other degrades, ultimately undermining recommendation accuracy. To address this, we propose VLM2Rec, a VLM embedder-based framework for multimodal sequential recommendation designed to ensure balanced modality utilization. Specifically, we introduce Weak-modality Penalized Contrastive Learning to rectify gradient imbalance during optimization and Cross-Modal Relational Topology Regularization to preserve geometric consistency between modalities. Extensive experiments demonstrate that VLM2Rec consistently outperforms state-of-the-art baselines in both accuracy and robustness across diverse scenarios.
Personalized Federated Recommendation With Knowledge Guidance
Nov 18, 2025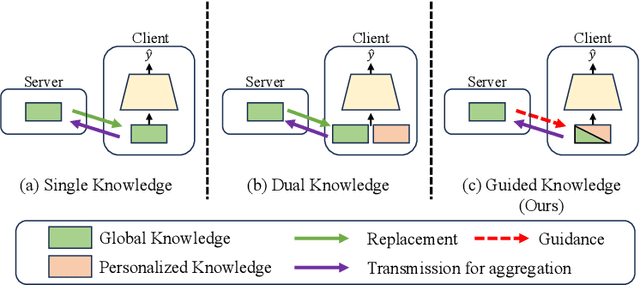
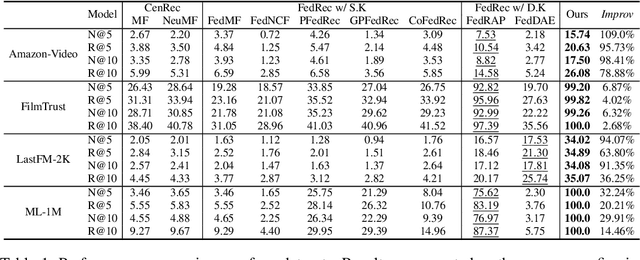
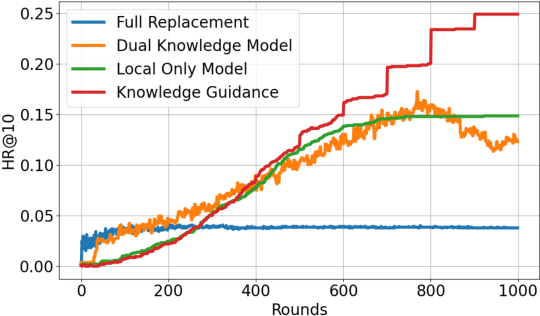
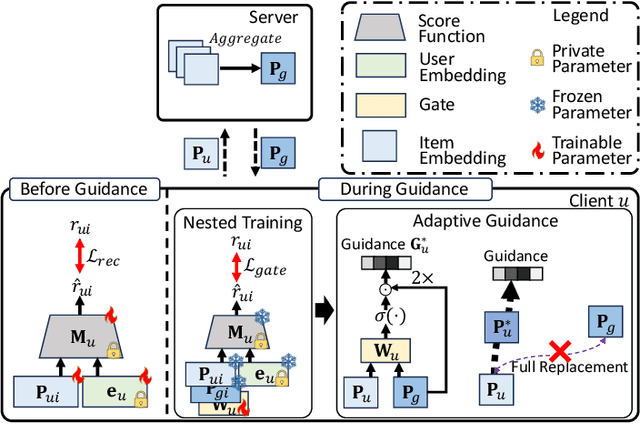
Federated Recommendation (FedRec) has emerged as a key paradigm for building privacy-preserving recommender systems. However, existing FedRec models face a critical dilemma: memory-efficient single-knowledge models suffer from a suboptimal knowledge replacement practice that discards valuable personalization, while high-performance dual-knowledge models are often too memory-intensive for practical on-device deployment. We propose Federated Recommendation with Knowledge Guidance (FedRKG), a model-agnostic framework that resolves this dilemma. The core principle, Knowledge Guidance, avoids full replacement and instead fuses global knowledge into preserved local embeddings, attaining the personalization benefits of dual-knowledge within a single-knowledge memory footprint. Furthermore, we introduce Adaptive Guidance, a fine-grained mechanism that dynamically modulates the intensity of this guidance for each user-item interaction, overcoming the limitations of static fusion methods. Extensive experiments on benchmark datasets demonstrate that FedRKG significantly outperforms state-of-the-art methods, validating the effectiveness of our approach. The code is available at https://github.com/Jaehyung-Lim/fedrkg.
Federated Continual Recommendation
Aug 06, 2025The increasing emphasis on privacy in recommendation systems has led to the adoption of Federated Learning (FL) as a privacy-preserving solution, enabling collaborative training without sharing user data. While Federated Recommendation (FedRec) effectively protects privacy, existing methods struggle with non-stationary data streams, failing to maintain consistent recommendation quality over time. On the other hand, Continual Learning Recommendation (CLRec) methods address evolving user preferences but typically assume centralized data access, making them incompatible with FL constraints. To bridge this gap, we introduce Federated Continual Recommendation (FCRec), a novel task that integrates FedRec and CLRec, requiring models to learn from streaming data while preserving privacy. As a solution, we propose F3CRec, a framework designed to balance knowledge retention and adaptation under the strict constraints of FCRec. F3CRec introduces two key components: Adaptive Replay Memory on the client side, which selectively retains past preferences based on user-specific shifts, and Item-wise Temporal Mean on the server side, which integrates new knowledge while preserving prior information. Extensive experiments demonstrate that F3CRec outperforms existing approaches in maintaining recommendation quality over time in a federated environment.
BemaGANv2: A Tutorial and Comparative Survey of GAN-based Vocoders for Long-Term Audio Generation
Jun 11, 2025This paper presents a tutorial-style survey and implementation guide of BemaGANv2, an advanced GAN-based vocoder designed for high-fidelity and long-term audio generation. Built upon the original BemaGAN architecture, BemaGANv2 incorporates major architectural innovations by replacing traditional ResBlocks in the generator with the Anti-aliased Multi-Periodicity composition (AMP) module, which internally applies the Snake activation function to better model periodic structures. In the discriminator framework, we integrate the Multi-Envelope Discriminator (MED), a novel architecture we originally proposed, to extract rich temporal envelope features crucial for periodicity detection. Coupled with the Multi-Resolution Discriminator (MRD), this combination enables more accurate modeling of long-range dependencies in audio. We systematically evaluate various discriminator configurations, including MSD + MED, MSD + MRD, and MPD + MED + MRD, using objective metrics (FAD, SSIM, PLCC, MCD) and subjective evaluations (MOS, SMOS). This paper also provides a comprehensive tutorial on the model architecture, training methodology, and implementation to promote reproducibility. The code and pre-trained models are available at: https://github.com/dinhoitt/BemaGANv2.
Crafting Query-Aware Selective Attention for Single Image Super-Resolution
Apr 09, 2025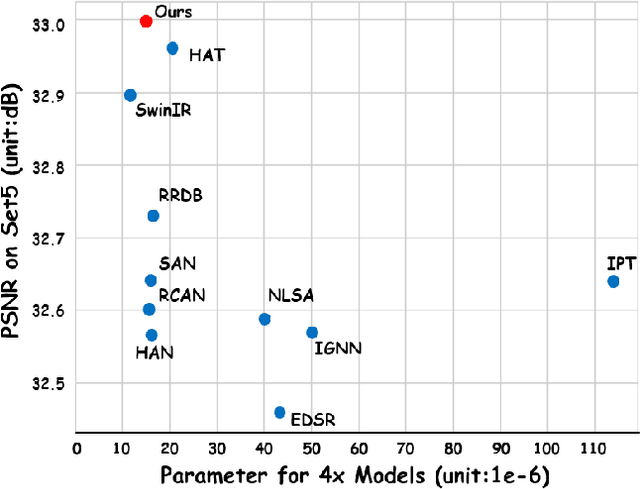
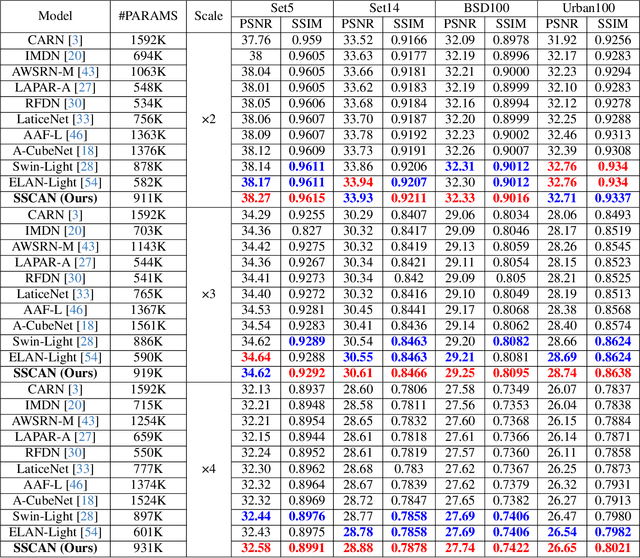

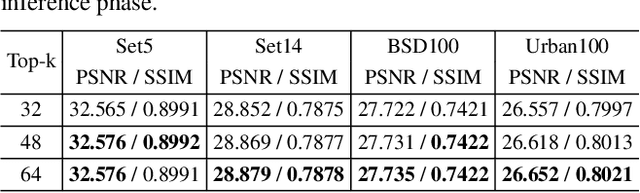
Single Image Super-Resolution (SISR) reconstructs high-resolution images from low-resolution inputs, enhancing image details. While Vision Transformer (ViT)-based models improve SISR by capturing long-range dependencies, they suffer from quadratic computational costs or employ selective attention mechanisms that do not explicitly focus on query-relevant regions. Despite these advancements, prior work has overlooked how selective attention mechanisms should be effectively designed for SISR. We propose SSCAN, which dynamically selects the most relevant key-value windows based on query similarity, ensuring focused feature extraction while maintaining efficiency. In contrast to prior approaches that apply attention globally or heuristically, our method introduces a query-aware window selection strategy that better aligns attention computation with important image regions. By incorporating fixed-sized windows, SSCAN reduces memory usage and enforces linear token-to-token complexity, making it scalable for large images. Our experiments demonstrate that SSCAN outperforms existing attention-based SISR methods, achieving up to 0.14 dB PSNR improvement on urban datasets, guaranteeing both computational efficiency and reconstruction quality in SISR.
Empowering Retrieval-based Conversational Recommendation with Contrasting User Preferences
Mar 27, 2025



Conversational recommender systems (CRSs) are designed to suggest the target item that the user is likely to prefer through multi-turn conversations. Recent studies stress that capturing sentiments in user conversations improves recommendation accuracy. However, they employ a single user representation, which may fail to distinguish between contrasting user intentions, such as likes and dislikes, potentially leading to suboptimal performance. To this end, we propose a novel conversational recommender model, called COntrasting user pReference expAnsion and Learning (CORAL). Firstly, CORAL extracts the user's hidden preferences through contrasting preference expansion using the reasoning capacity of the LLMs. Based on the potential preference, CORAL explicitly differentiates the contrasting preferences and leverages them into the recommendation process via preference-aware learning. Extensive experiments show that CORAL significantly outperforms existing methods in three benchmark datasets, improving up to 99.72% in Recall@10. The code and datasets are available at https://github.com/kookeej/CORAL
A Data Aggregation Visualization System supported by Processing-in-Memory
Mar 11, 2025Data visualization of aggregation queries is one of the most common ways of doing data exploration and data science as it can help identify correlations and patterns in the data. We propose DIVAN, a system that automatically normalizes the one-dimensional axes by frequency to generate large numbers of two-dimensional visualizations. DIVAN normalizes the input data via binning to allocate more pixels to data values that appear more frequently in the dataset. DIVAN can utilize either CPUs or Processing-in-Memory (PIM) architectures to quickly calculate aggregates to support the visualizations. On real world datasets, we show that DIVAN generates visualizations that highlight patterns and correlations, some expected and some unexpected. By using PIM, we can calculate aggregates 45%-64% faster than modern CPUs on large datasets. For use cases with 100 million rows and 32 columns, our system is able to compute 4,960 aggregates (each of size 128x128x128) in about a minute.
FLARE: FP-Less PTQ and Low-ENOB ADC Based AMS-PiM for Error-Resilient, Fast, and Efficient Transformer Acceleration
Nov 22, 2024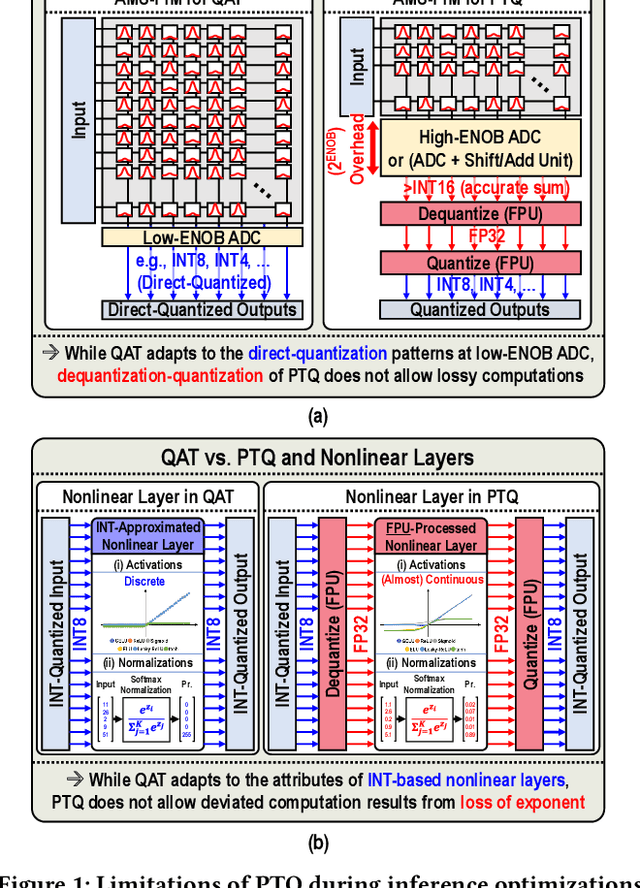
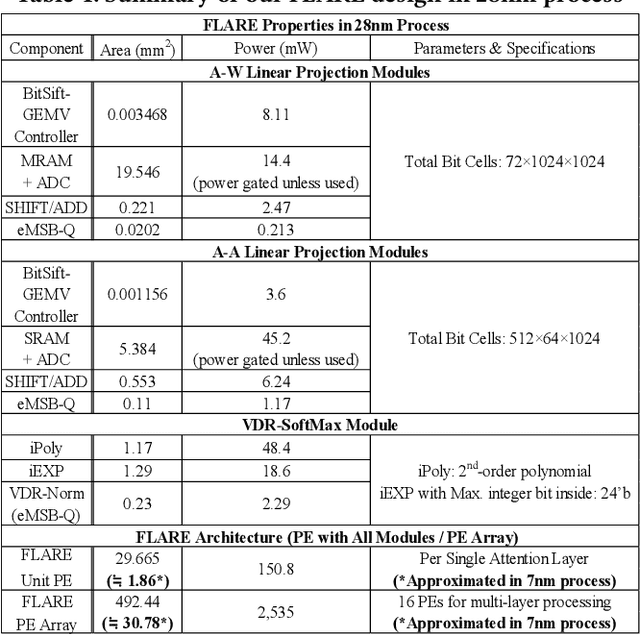
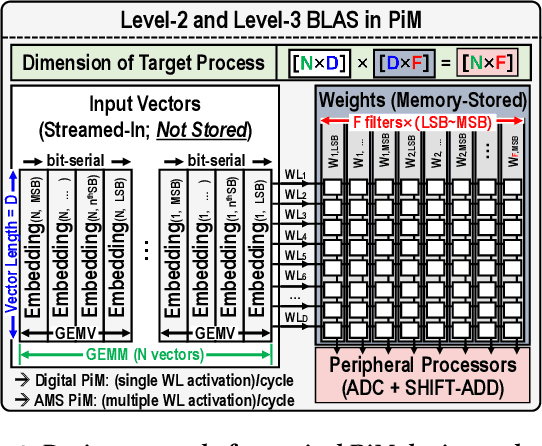
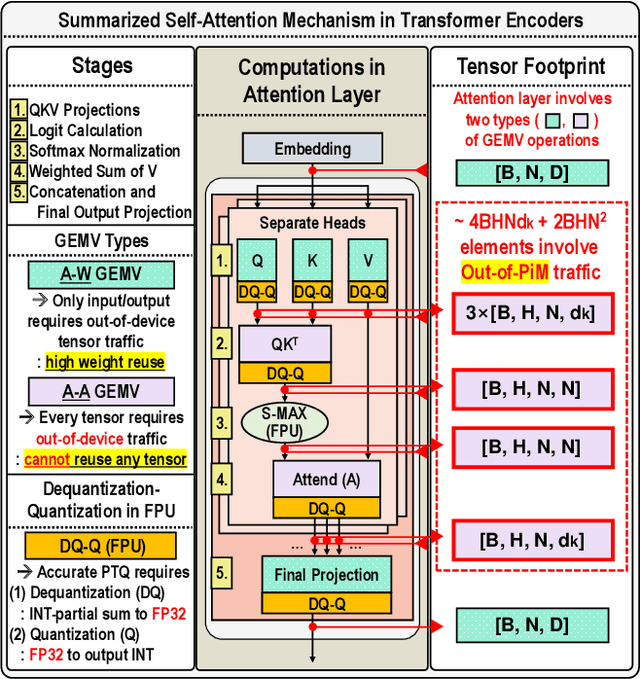
Encoder-based transformers, powered by self-attention layers, have revolutionized machine learning with their context-aware representations. However, their quadratic growth in computational and memory demands presents significant bottlenecks. Analog-Mixed-Signal Process-in-Memory (AMS-PiM) architectures address these challenges by enabling efficient on-chip processing. Traditionally, AMS-PiM relies on Quantization-Aware Training (QAT), which is hardware-efficient but requires extensive retraining to adapt models to AMS-PiMs, making it increasingly impractical for transformer models. Post-Training Quantization (PTQ) mitigates this training overhead but introduces significant hardware inefficiencies. PTQ relies on dequantization-quantization (DQ-Q) processes, floating-point units (FPUs), and high-ENOB (Effective Number of Bits) analog-to-digital converters (ADCs). Particularly, High-ENOB ADCs scale exponentially in area and energy ($2^{ENOB}$), reduce sensing margins, and increase susceptibility to process, voltage, and temperature (PVT) variations, further compounding PTQ's challenges in AMS-PiM systems. To overcome these limitations, we propose RAP, an AMS-PiM architecture that eliminates DQ-Q processes, introduces FPU- and division-free nonlinear processing, and employs a low-ENOB-ADC-based sparse Matrix Vector multiplication technique. Using the proposed techniques, RAP improves error resiliency, area/energy efficiency, and computational speed while preserving numerical stability. Experimental results demonstrate that RAP outperforms state-of-the-art GPUs and conventional PiM architectures in energy efficiency, latency, and accuracy, making it a scalable solution for the efficient deployment of transformers.
MARS: Matching Attribute-aware Representations for Text-based Sequential Recommendation
Sep 04, 2024Sequential recommendation aims to predict the next item a user is likely to prefer based on their sequential interaction history. Recently, text-based sequential recommendation has emerged as a promising paradigm that uses pre-trained language models to exploit textual item features to enhance performance and facilitate knowledge transfer to unseen datasets. However, existing text-based recommender models still struggle with two key challenges: (i) representing users and items with multiple attributes, and (ii) matching items with complex user interests. To address these challenges, we propose a novel model, Matching Attribute-aware Representations for Text-based Sequential Recommendation (MARS). MARS extracts detailed user and item representations through attribute-aware text encoding, capturing diverse user intents with multiple attribute-aware representations. It then computes user-item scores via attribute-wise interaction matching, effectively capturing attribute-level user preferences. Our extensive experiments demonstrate that MARS significantly outperforms existing sequential models, achieving improvements of up to 24.43% and 29.26% in Recall@10 and NDCG@10 across five benchmark datasets. Code is available at https://github.com/junieberry/MARS