 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Retrieval for Reasoning-Intensive Retrieval
Jan 08, 2026We study leveraging adaptive retrieval to ensure sufficient "bridge" documents are retrieved for reasoning-intensive retrieval. Bridge documents are those that contribute to the reasoning process yet are not directly relevant to the initial query. While existing reasoning-based reranker pipelines attempt to surface these documents in ranking, they suffer from bounded recall. Naive solution with adaptive retrieval into these pipelines often leads to planning error propagation. To address this, we propose REPAIR, a framework that bridges this gap by repurposing reasoning plans as dense feedback signals for adaptive retrieval. Our key distinction is enabling mid-course correction during reranking through selective adaptive retrieval, retrieving documents that support the pivotal plan. Experimental results on reasoning-intensive retrieval and complex QA tasks demonstrate that our method outperforms existing baselines by 5.6%pt.
Relevance to Utility: Process-Supervised Rewrite for RAG
Sep 19, 2025Retrieval-Augmented Generation systems often suffer from a gap between optimizing retrieval relevance and generative utility: retrieved documents may be topically relevant but still lack the content needed for effective reasoning during generation. While existing "bridge" modules attempt to rewrite the retrieved text for better generation, we show how they fail to capture true document utility. In this work, we propose R2U, with a key distinction of directly optimizing to maximize the probability of generating a correct answer through process supervision. As such direct observation is expensive, we also propose approximating an efficient distillation pipeline by scaling the supervision from LLMs, which helps the smaller rewriter model generalize better. We evaluate our method across multiple open-domain question-answering benchmarks. The empirical results demonstrate consistent improvements over strong bridging baselines.
Chaining Event Spans for Temporal Relation Grounding
Jun 17, 2025Accurately understanding temporal relations between events is a critical building block of diverse tasks, such as temporal reading comprehension (TRC) and relation extraction (TRE). For example in TRC, we need to understand the temporal semantic differences between the following two questions that are lexically near-identical: "What finished right before the decision?" or "What finished right after the decision?". To discern the two questions, existing solutions have relied on answer overlaps as a proxy label to contrast similar and dissimilar questions. However, we claim that answer overlap can lead to unreliable results, due to spurious overlaps of two dissimilar questions with coincidentally identical answers. To address the issue, we propose a novel approach that elicits proper reasoning behaviors through a module for predicting time spans of events. We introduce the Timeline Reasoning Network (TRN) operating in a two-step inductive reasoning process: In the first step model initially answers each question with semantic and syntactic information. The next step chains multiple questions on the same event to predict a timeline, which is then used to ground the answers. Results on the TORQUE and TB-dense, TRC and TRE tasks respectively, demonstrate that TRN outperforms previous methods by effectively resolving the spurious overlaps using the predicted timeline.
Intended Target Identification for Anomia Patients with Gradient-based Selective Augmentation
Jun 17, 2025In this study, we investigate the potential of language models (LMs) in aiding patients experiencing anomia, a difficulty identifying the names of items. Identifying the intended target item from patient's circumlocution involves the two challenges of term failure and error: (1) The terms relevant to identifying the item remain unseen. (2) What makes the challenge unique is inherent perturbed terms by semantic paraphasia, which are not exactly related to the target item, hindering the identification process. To address each, we propose robustifying the model from semantically paraphasic errors and enhancing the model with unseen terms with gradient-based selective augmentation. Specifically, the gradient value controls augmented data quality amid semantic errors, while the gradient variance guides the inclusion of unseen but relevant terms. Due to limited domain-specific datasets, we evaluate the model on the Tip-of-the-Tongue dataset as an intermediary task and then apply our findings to real patient data from AphasiaBank. Our results demonstrate strong performance against baselines, aiding anomia patients by addressing the outlined challenges.
* EMNLP 2024 Findings (long)
Counterfactual-Consistency Prompting for Relative Temporal Understanding in Large Language Models
Feb 17, 2025Despite the advanced capabilities of large language models (LLMs), their temporal reasoning ability remains underdeveloped. Prior works have highlighted this limitation, particularly in maintaining temporal consistency when understanding events. For example, models often confuse mutually exclusive temporal relations like ``before'' and ``after'' between events and make inconsistent predictions. In this work, we tackle the issue of temporal inconsistency in LLMs by proposing a novel counterfactual prompting approach. Our method generates counterfactual questions and enforces collective constraints, enhancing the model's consistency. We evaluate our method on multiple datasets, demonstrating significant improvements in event ordering for explicit and implicit events and temporal commonsense understanding by effectively addressing temporal inconsistencies.
FLARE: FP-Less PTQ and Low-ENOB ADC Based AMS-PiM for Error-Resilient, Fast, and Efficient Transformer Acceleration
Nov 22, 2024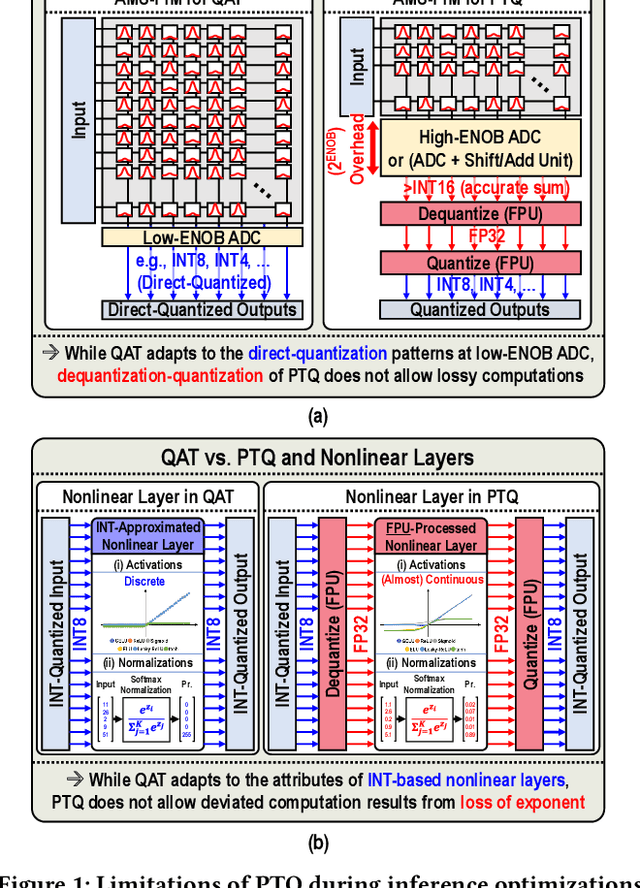
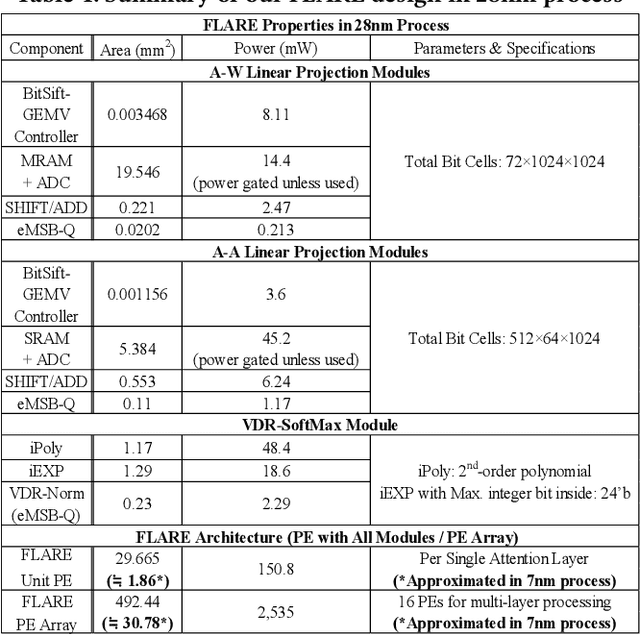
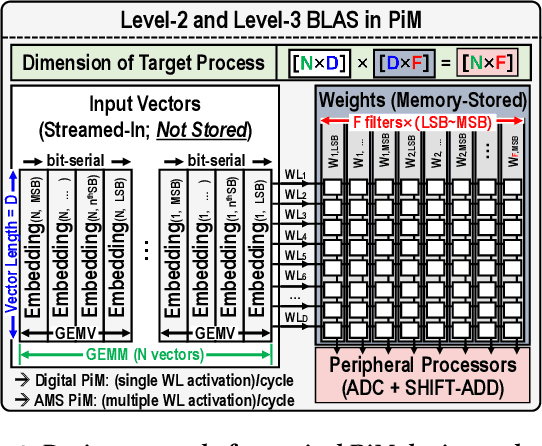
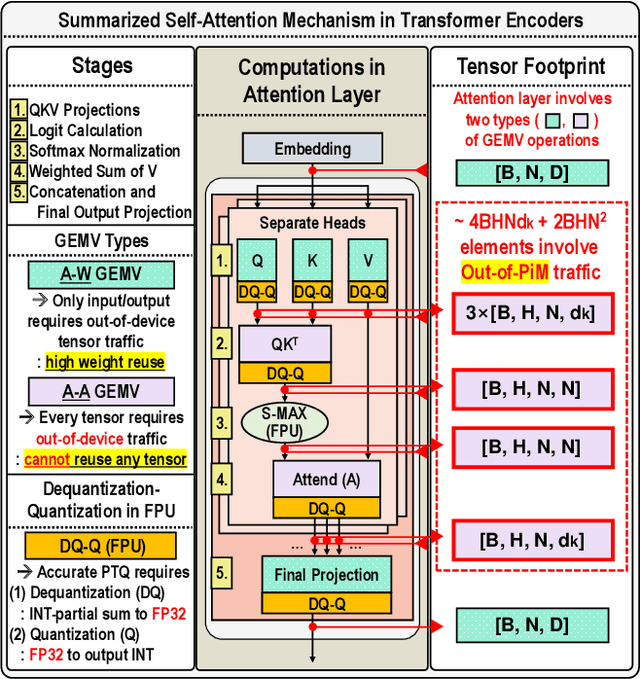
Encoder-based transformers, powered by self-attention layers, have revolutionized machine learning with their context-aware representations. However, their quadratic growth in computational and memory demands presents significant bottlenecks. Analog-Mixed-Signal Process-in-Memory (AMS-PiM) architectures address these challenges by enabling efficient on-chip processing. Traditionally, AMS-PiM relies on Quantization-Aware Training (QAT), which is hardware-efficient but requires extensive retraining to adapt models to AMS-PiMs, making it increasingly impractical for transformer models. Post-Training Quantization (PTQ) mitigates this training overhead but introduces significant hardware inefficiencies. PTQ relies on dequantization-quantization (DQ-Q) processes, floating-point units (FPUs), and high-ENOB (Effective Number of Bits) analog-to-digital converters (ADCs). Particularly, High-ENOB ADCs scale exponentially in area and energy ($2^{ENOB}$), reduce sensing margins, and increase susceptibility to process, voltage, and temperature (PVT) variations, further compounding PTQ's challenges in AMS-PiM systems. To overcome these limitations, we propose RAP, an AMS-PiM architecture that eliminates DQ-Q processes, introduces FPU- and division-free nonlinear processing, and employs a low-ENOB-ADC-based sparse Matrix Vector multiplication technique. Using the proposed techniques, RAP improves error resiliency, area/energy efficiency, and computational speed while preserving numerical stability. Experimental results demonstrate that RAP outperforms state-of-the-art GPUs and conventional PiM architectures in energy efficiency, latency, and accuracy, making it a scalable solution for the efficient deployment of transformers.
Space-Time Video Regularity and Visual Fidelity: Compression, Resolution and Frame Rate Adaptation
Mar 31, 2021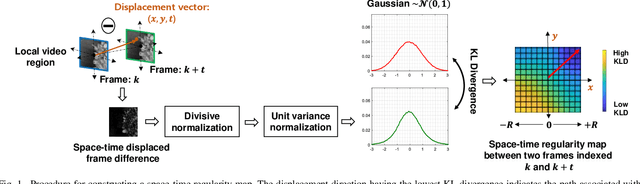
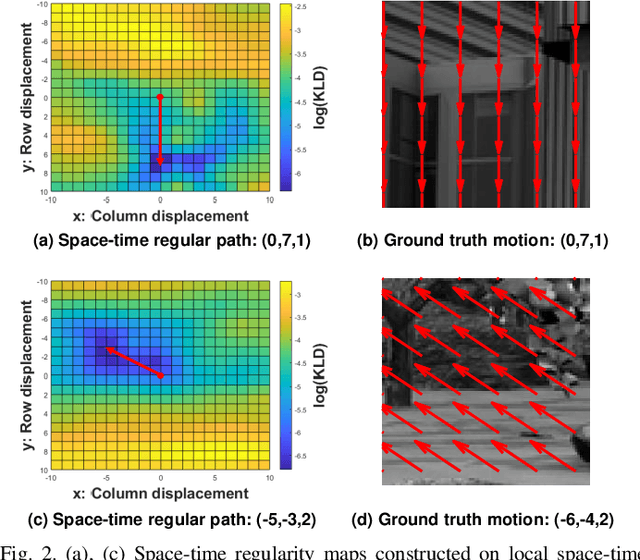
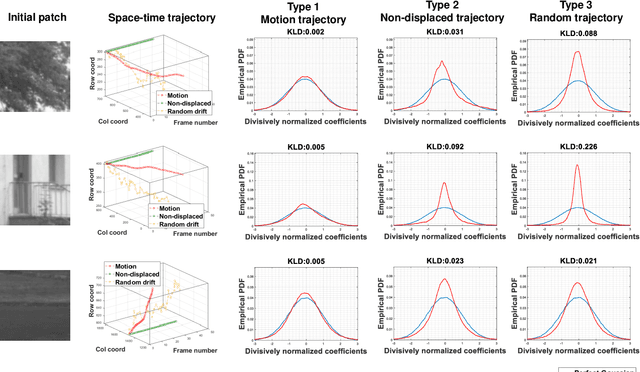
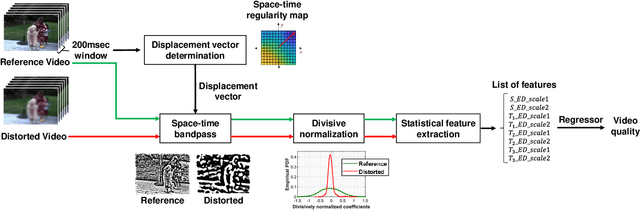
In order to be able to deliver today's voluminous amount of video contents through limited bandwidth channels in a perceptually optimal way, it is important to consider perceptual trade-offs of compression and space-time downsampling protocols. In this direction, we have studied and developed new models of natural video statistics (NVS), which are useful because high-quality videos contain statistical regularities that are disturbed by distortions. Specifically, we model the statistics of divisively normalized difference between neighboring frames that are relatively displaced. In an extensive empirical study, we found that those paths of space-time displaced frame differences that provide maximal regularity against our NVS model generally align best with motion trajectories. Motivated by this, we build a new video quality prediction engine that extracts NVS features from displaced frame differences, and combines them in a learned regressor that can accurately predict perceptual quality. As a stringent test of the new model, we apply it to the difficult problem of predicting the quality of videos subjected not only to compression, but also to downsampling in space and/or time. We show that the new quality model achieves state-of-the-art (SOTA) prediction performance compared on the new ETRI-LIVE Space-Time Subsampled Video Quality (STSVQ) database, which is dedicated to this problem. Downsampling protocols are of high interest to the streaming video industry, given rapid increases in frame resolutions and frame rates.
A Subjective and Objective Study of Space-Time Subsampled Video Quality
Jan 29, 2021
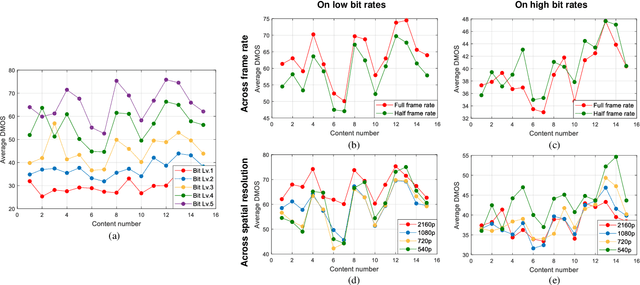
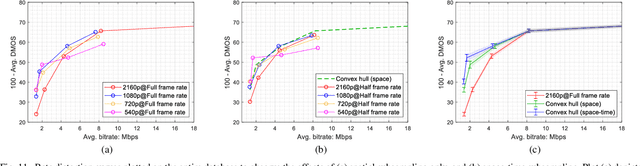
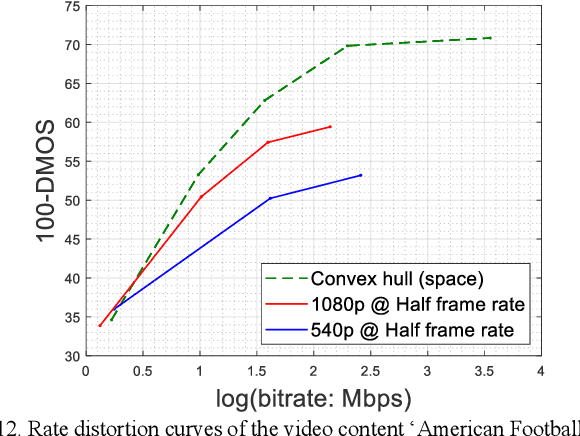
Video dimensions are continuously increasing to provide more realistic and immersive experiences to global streaming and social media viewers. However, increments in video parameters such as spatial resolution and frame rate are inevitably associated with larger data volumes. Transmitting increasingly voluminous videos through limited bandwidth networks in a perceptually optimal way is a current challenge affecting billions of viewers. One recent practice adopted by video service providers is space-time resolution adaptation in conjunction with video compression. Consequently, it is important to understand how different levels of space-time subsampling and compression affect the perceptual quality of videos. Towards making progress in this direction, we constructed a large new resource, called the ETRI-LIVE Space-Time Subsampled Video Quality (ETRI-LIVE STSVQ) database, containing 437 videos generated by applying various levels of combined space-time subsampling and video compression on 15 diverse video contents. We also conducted a large-scale human study on the new dataset, collecting about 15,000 subjective judgments of video quality. We provide a rate-distortion analysis of the collected subjective scores, enabling us to investigate the perceptual impact of space-time subsampling at different bit rates. We also evaluated and compared the performance of leading video quality models on the new database.
On the Space-Time Statistics of Motion Pictures
Jan 29, 2021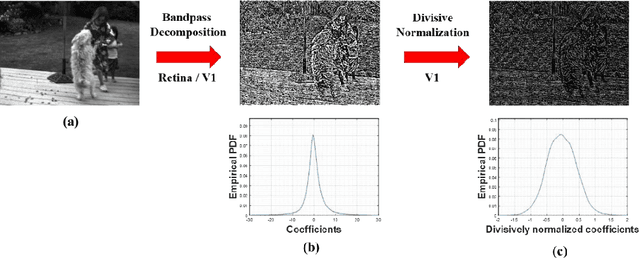
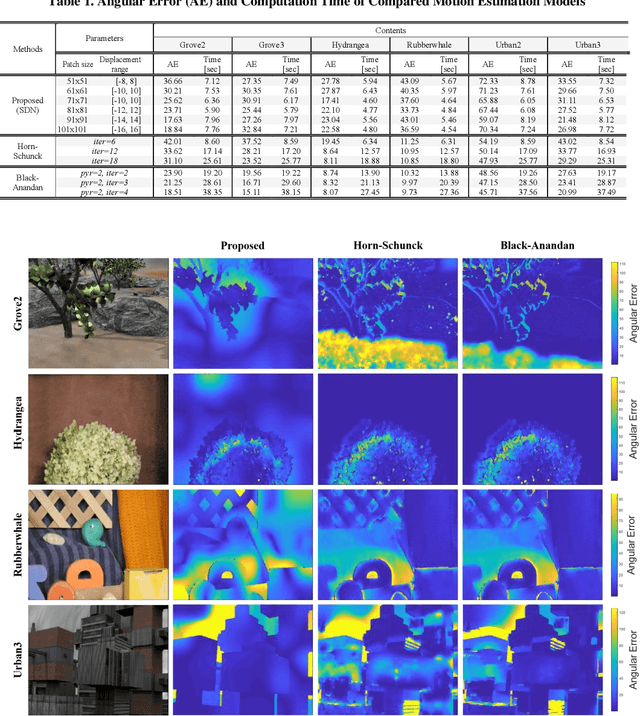
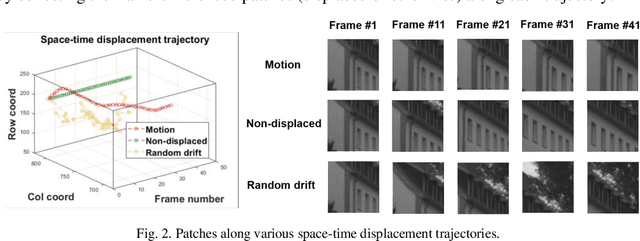
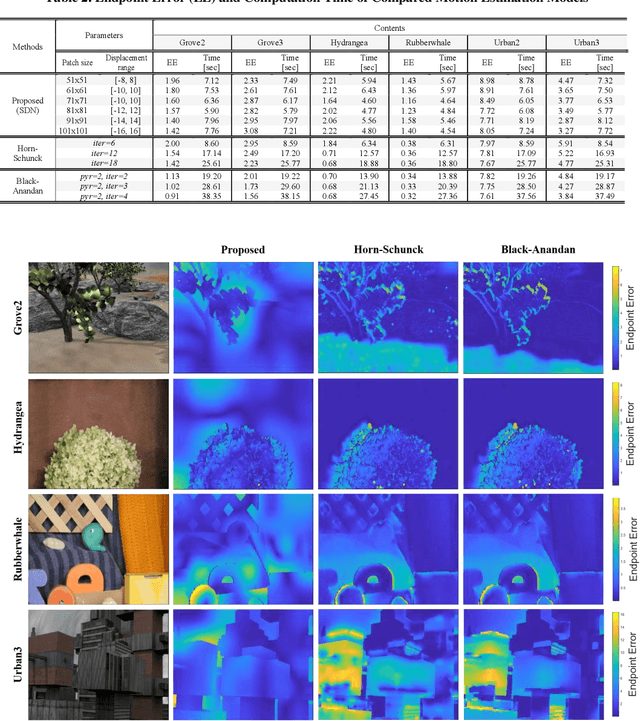
It is well-known that natural images possess statistical regularities that can be captured by bandpass decomposition and divisive normalization processes that approximate early neural processing in the human visual system. We expand on these studies and present new findings on the properties of space-time natural statistics that are inherent in motion pictures. Our model relies on the concept of temporal bandpass (e.g. lag) filtering in LGN and area V1, which is similar to smoothed frame differencing of video frames. Specifically, we model the statistics of the differences between adjacent or neighboring video frames that have been slightly spatially displaced relative to one another. We find that when these space-time differences are further subjected to locally pooled divisive normalization, statistical regularities (or lack thereof) arise that depend on the local motion trajectory. We find that bandpass and divisively normalized frame-differences that are displaced along the motion direction exhibit stronger statistical regularities than for other displacements. Conversely, the direction-dependent regularities of displaced frame differences can be used to estimate the image motion (optical flow) by finding the space-time displacement paths that best preserve statistical regularity.
Sample Efficient Reinforcement Learning with REINFORCE
Oct 22, 2020Policy gradient methods are among the most effective methods for large-scale reinforcement learning, and their empirical success has prompted several works that develop the foundation of their global convergence theory. However, prior works have either required exact gradients or state-action visitation measure based mini-batch stochastic gradients with a diverging batch size, which limit their applicability in practical scenarios. In this paper, we consider classical policy gradient methods that compute an approximate gradient with a single trajectory or a fixed size mini-batch of trajectories, along with the widely-used REINFORCE gradient estimation procedure. By controlling the number of "bad" episodes and resorting to the classical doubling trick, we establish an anytime sub-linear high probability regret bound as well as almost sure global convergence of the average regret with an asymptotically sub-linear rate. These provide the first set of global convergence and sample efficiency results for the well-known REINFORCE algorithm and contribute to a better understanding of its performance in practice.