 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: FP-Less PTQ and Low-ENOB ADC Based AMS-PiM for Error-Resilient, Fast, and Efficient Transformer Acceleration
Nov 22, 2024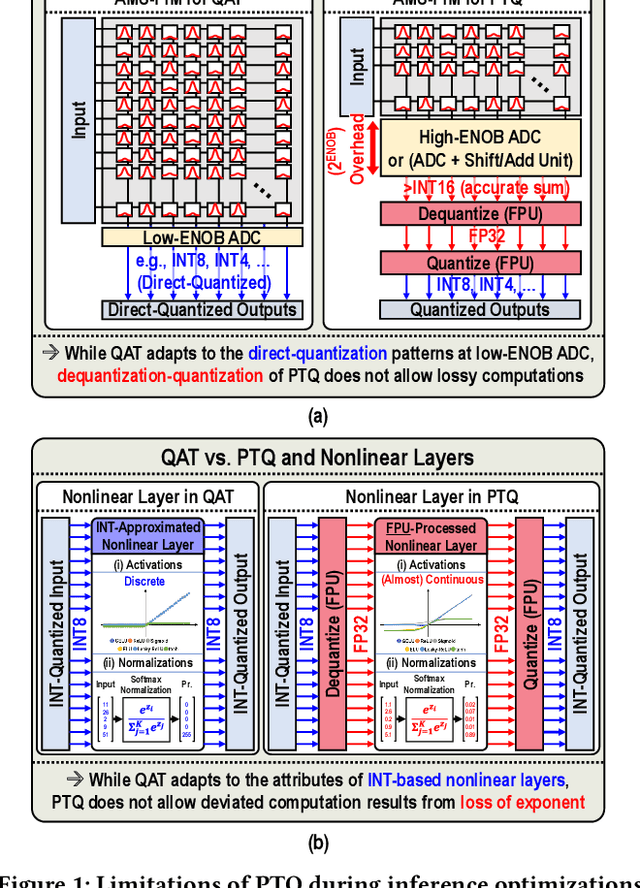
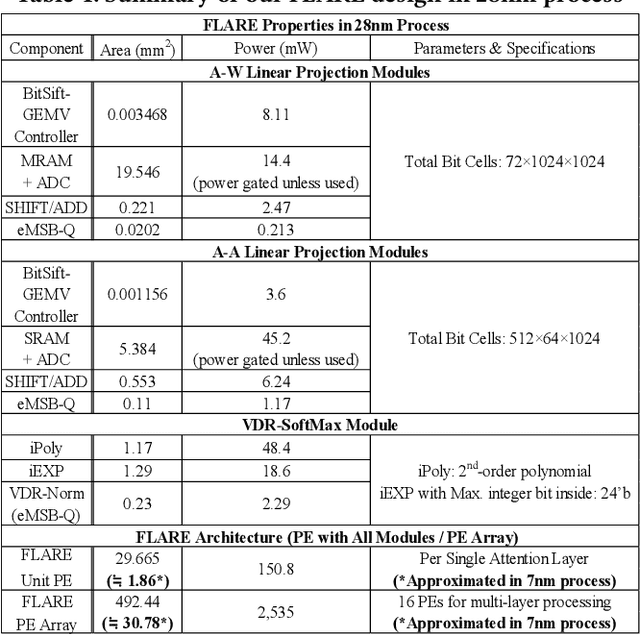
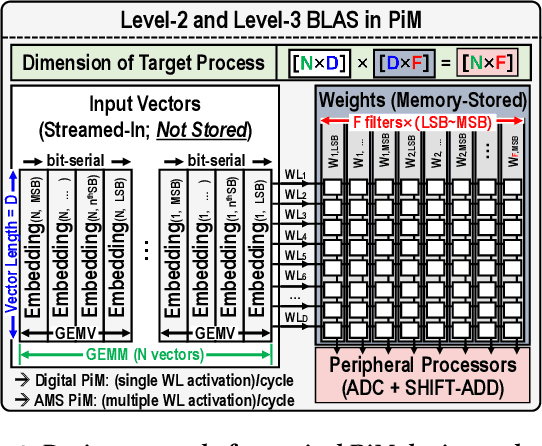
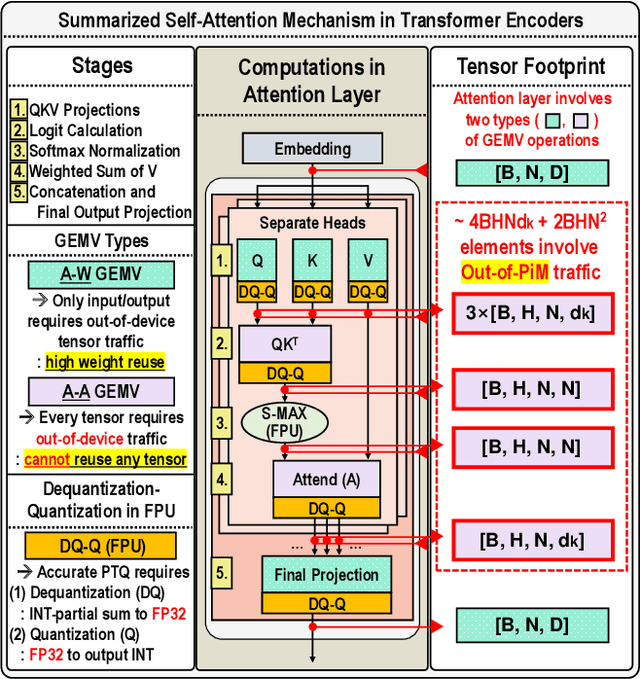
Encoder-based transformers, powered by self-attention layers, have revolutionized machine learning with their context-aware representations. However, their quadratic growth in computational and memory demands presents significant bottlenecks. Analog-Mixed-Signal Process-in-Memory (AMS-PiM) architectures address these challenges by enabling efficient on-chip processing. Traditionally, AMS-PiM relies on Quantization-Aware Training (QAT), which is hardware-efficient but requires extensive retraining to adapt models to AMS-PiMs, making it increasingly impractical for transformer models. Post-Training Quantization (PTQ) mitigates this training overhead but introduces significant hardware inefficiencies. PTQ relies on dequantization-quantization (DQ-Q) processes, floating-point units (FPUs), and high-ENOB (Effective Number of Bits) analog-to-digital converters (ADCs). Particularly, High-ENOB ADCs scale exponentially in area and energy ($2^{ENOB}$), reduce sensing margins, and increase susceptibility to process, voltage, and temperature (PVT) variations, further compounding PTQ's challenges in AMS-PiM systems. To overcome these limitations, we propose RAP, an AMS-PiM architecture that eliminates DQ-Q processes, introduces FPU- and division-free nonlinear processing, and employs a low-ENOB-ADC-based sparse Matrix Vector multiplication technique. Using the proposed techniques, RAP improves error resiliency, area/energy efficiency, and computational speed while preserving numerical stability. Experimental results demonstrate that RAP outperforms state-of-the-art GPUs and conventional PiM architectures in energy efficiency, latency, and accuracy, making it a scalable solution for the efficient deployment of transformers.