 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog2Plan: An Adaptive GUI Automation Framework Integrated with Task Mining Approach
Sep 26, 2025
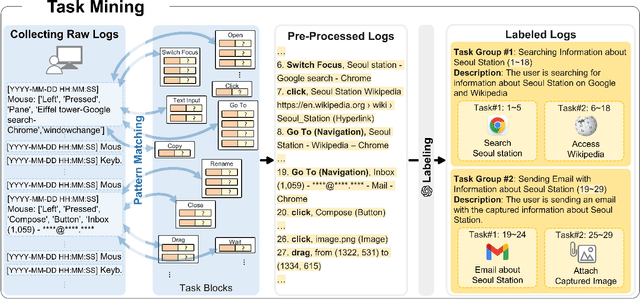


GUI task automation streamlines repetitive tasks, but existing LLM or VLM-based planner-executor agents suffer from brittle generalization, high latency, and limited long-horizon coherence. Their reliance on single-shot reasoning or static plans makes them fragile under UI changes or complex tasks. Log2Plan addresses these limitations by combining a structured two-level planning framework with a task mining approach over user behavior logs, enabling robust and adaptable GUI automation. Log2Plan constructs high-level plans by mapping user commands to a structured task dictionary, enabling consistent and generalizable automation. To support personalization and reuse, it employs a task mining approach from user behavior logs that identifies user-specific patterns. These high-level plans are then grounded into low-level action sequences by interpreting real-time GUI context, ensuring robust execution across varying interfaces. We evaluated Log2Plan on 200 real-world tasks, demonstrating significant improvements in task success rate and execution time. Notably, it maintains over 60.0% success rate even on long-horizon task sequences, highlighting its robustness in complex, multi-step workflows.
Demystifying the Visual Quality Paradox in Multimodal Large Language Models
Jun 18, 2025Recent Multimodal Large Language Models (MLLMs) excel on benchmark vision-language tasks, yet little is known about how input visual quality shapes their responses. Does higher perceptual quality of images already translate to better MLLM understanding? We conduct the first systematic study spanning leading MLLMs and a suite of vision-language benchmarks, applying controlled degradations and stylistic shifts to each image. Surprisingly, we uncover a visual-quality paradox: model, task, and even individual-instance performance can improve when images deviate from human-perceived fidelity. Off-the-shelf restoration pipelines fail to reconcile these idiosyncratic preferences. To close the gap, we introduce Visual-Quality Test-Time Tuning (VQ-TTT)-a lightweight adaptation module that: (1) inserts a learnable, low-rank kernel before the frozen vision encoder to modulate frequency content; and (2) fine-tunes only shallow vision-encoder layers via LoRA. VQ-TTT dynamically adjusts each input image in a single forward pass, aligning it with task-specific model preferences. Across the evaluated MLLMs and all datasets, VQ-TTT lifts significant average accuracy, with no external models, cached features, or extra training data. These findings redefine ``better'' visual inputs for MLLMs and highlight the need for adaptive, rather than universally ``clean'', imagery, in the new era of AI being the main data customer.
FLARE: FP-Less PTQ and Low-ENOB ADC Based AMS-PiM for Error-Resilient, Fast, and Efficient Transformer Acceleration
Nov 22, 2024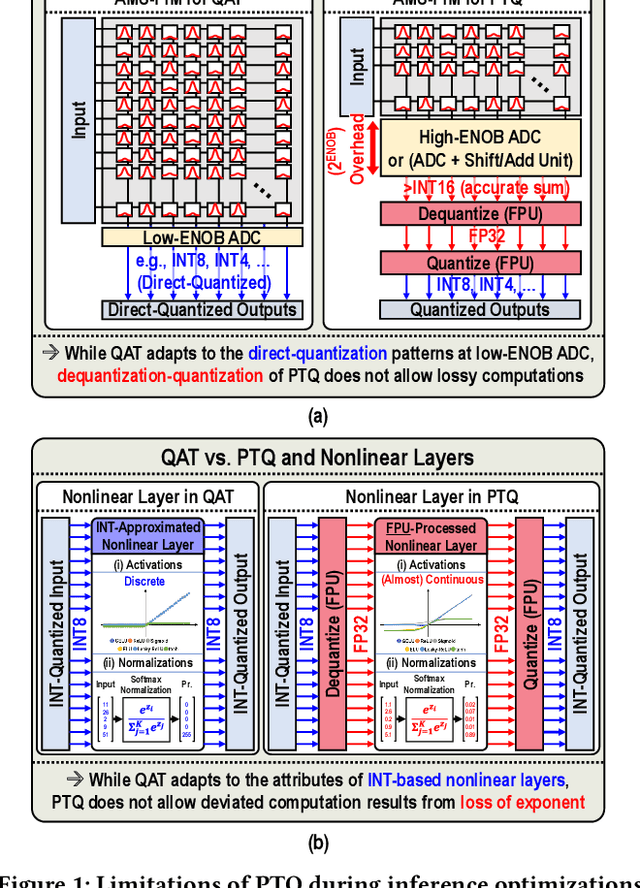
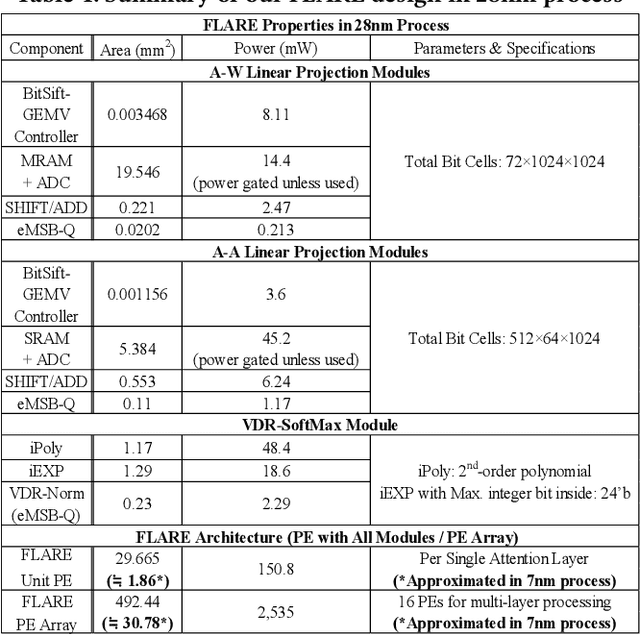
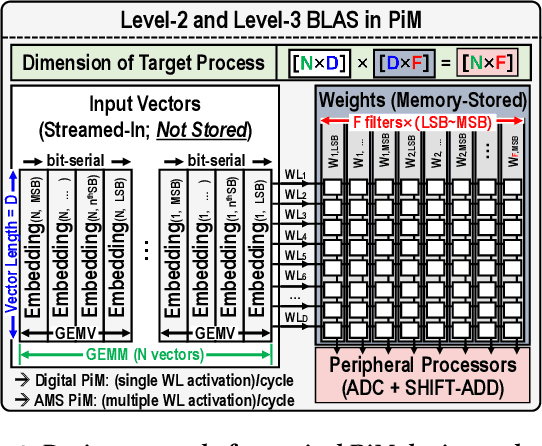
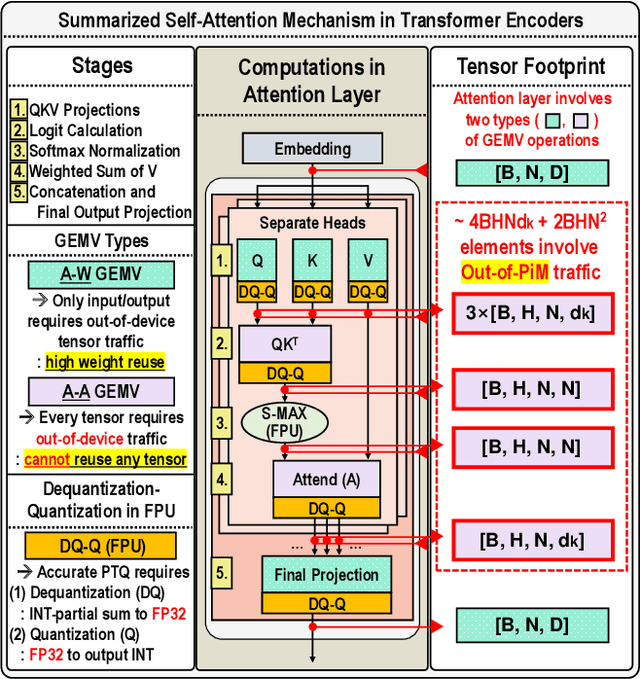
Encoder-based transformers, powered by self-attention layers, have revolutionized machine learning with their context-aware representations. However, their quadratic growth in computational and memory demands presents significant bottlenecks. Analog-Mixed-Signal Process-in-Memory (AMS-PiM) architectures address these challenges by enabling efficient on-chip processing. Traditionally, AMS-PiM relies on Quantization-Aware Training (QAT), which is hardware-efficient but requires extensive retraining to adapt models to AMS-PiMs, making it increasingly impractical for transformer models. Post-Training Quantization (PTQ) mitigates this training overhead but introduces significant hardware inefficiencies. PTQ relies on dequantization-quantization (DQ-Q) processes, floating-point units (FPUs), and high-ENOB (Effective Number of Bits) analog-to-digital converters (ADCs). Particularly, High-ENOB ADCs scale exponentially in area and energy ($2^{ENOB}$), reduce sensing margins, and increase susceptibility to process, voltage, and temperature (PVT) variations, further compounding PTQ's challenges in AMS-PiM systems. To overcome these limitations, we propose RAP, an AMS-PiM architecture that eliminates DQ-Q processes, introduces FPU- and division-free nonlinear processing, and employs a low-ENOB-ADC-based sparse Matrix Vector multiplication technique. Using the proposed techniques, RAP improves error resiliency, area/energy efficiency, and computational speed while preserving numerical stability. Experimental results demonstrate that RAP outperforms state-of-the-art GPUs and conventional PiM architectures in energy efficiency, latency, and accuracy, making it a scalable solution for the efficient deployment of transformers.
Expressive Gaussian Human Avatars from Monocular RGB Video
Jul 03, 2024



Nuanced expressiveness, particularly through fine-grained hand and facial expressions, is pivotal for enhancing the realism and vitality of digital human representations. In this work, we focus on investigating the expressiveness of human avatars when learned from monocular RGB video; a setting that introduces new challenges in capturing and animating fine-grained details. To this end, we introduce EVA, a drivable human model that meticulously sculpts fine details based on 3D Gaussians and SMPL-X, an expressive parametric human model. Focused on enhancing expressiveness, our work makes three key contributions. First, we highlight the critical importance of aligning the SMPL-X model with RGB frames for effective avatar learning. Recognizing the limitations of current SMPL-X prediction methods for in-the-wild videos, we introduce a plug-and-play module that significantly ameliorates misalignment issues. Second, we propose a context-aware adaptive density control strategy, which is adaptively adjusting the gradient thresholds to accommodate the varied granularity across body parts. Last but not least, we develop a feedback mechanism that predicts per-pixel confidence to better guide the learning of 3D Gaussians. Extensive experiments on two benchmarks demonstrate the superiority of our framework both quantitatively and qualitatively, especially on the fine-grained hand and facial details. See the project website at \url{https://evahuman.github.io}
Towards Efficient Neural Scene Graphs by Learning Consistency Fields
Oct 09, 2022
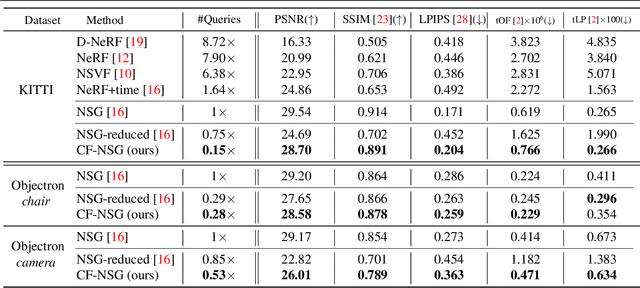
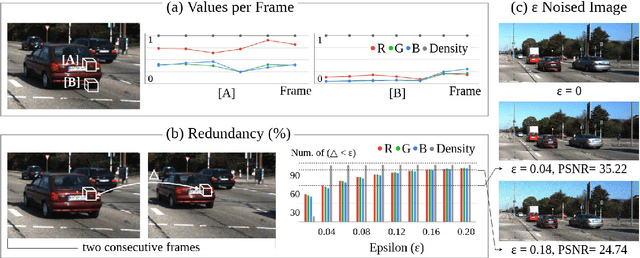

Neural Radiance Fields (NeRF) achieves photo-realistic image rendering from novel views, and the Neural Scene Graphs (NSG) \cite{ost2021neural} extends it to dynamic scenes (video) with multiple objects. Nevertheless, computationally heavy ray marching for every image frame becomes a huge burden. In this paper, taking advantage of significant redundancy across adjacent frames in videos, we propose a feature-reusing framework. From the first try of naively reusing the NSG features, however, we learn that it is crucial to disentangle object-intrinsic properties consistent across frames from transient ones. Our proposed method, \textit{Consistency-Field-based NSG (CF-NSG)}, reformulates neural radiance fields to additionally consider \textit{consistency fields}. With disentangled representations, CF-NSG takes full advantage of the feature-reusing scheme and performs an extended degree of scene manipulation in a more controllable manner. We empirically verify that CF-NSG greatly improves the inference efficiency by using 85\% less queries than NSG without notable degradation in rendering quality. Code will be available at: https://github.com/ldynx/CF-NSG