 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic LoRA: Why and When to Tune Weights vs. Rewrite Prompts
Jan 19, 2026Large language models (LLMs) can be adapted either through numerical updates that alter model parameters or symbolic manipulations that work on discrete prompts or logical constraints. While numerical fine-tuning excels at injecting new factual knowledge, symbolic updates offer flexible control of style and alignment without retraining. We introduce a neurosymbolic LoRA framework that dynamically combines these two complementary strategies. Specifically, we present a unified monitoring signal and a reward-based classifier to decide when to employ LoRA for deeper factual reconstruction and when to apply TextGrad for token-level edits. Our approach remains memory-efficient by offloading the symbolic transformations to an external LLM only when needed. Additionally, the refined prompts produced during symbolic editing serve as high-quality, reusable training data, an important benefit in data-scarce domains like mathematical reasoning. Extensive experiments across multiple LLM backbones show that neurosymbolic LoRA consistently outperforms purely numerical or purely symbolic baselines, demonstrating superior adaptability and improved performance. Our findings highlight the value of interleaving numerical and symbolic updates to unlock a new level of versatility in language model fine-tuning.
On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
Sep 30, 2024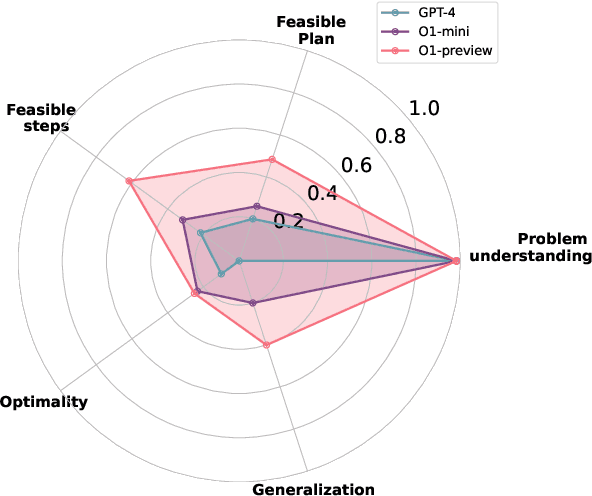
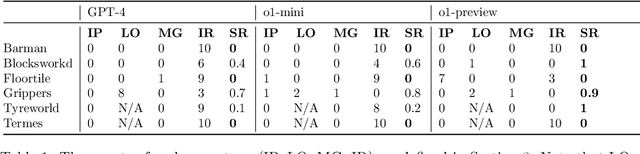
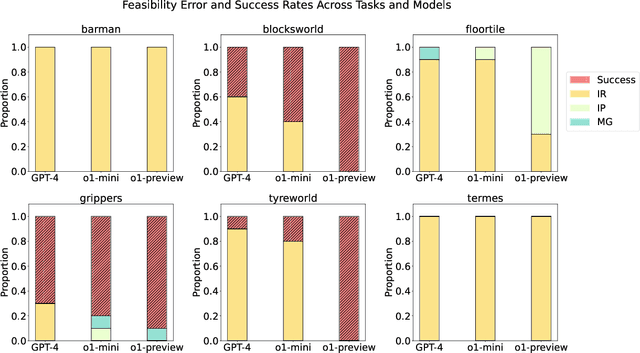
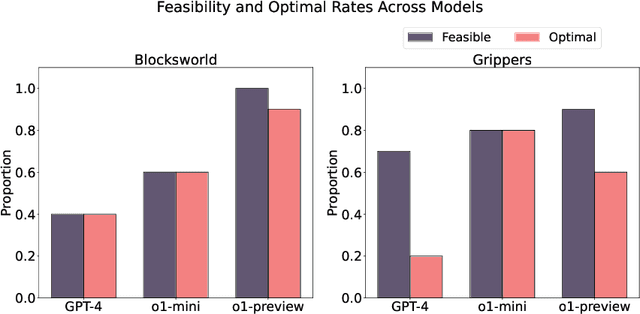
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $\textit{Barman}$, $\textit{Tyreworld}$) and spatially complex environments (e.g., $\textit{Termes}$, $\textit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning.
Expressive Gaussian Human Avatars from Monocular RGB Video
Jul 03, 2024



Nuanced expressiveness, particularly through fine-grained hand and facial expressions, is pivotal for enhancing the realism and vitality of digital human representations. In this work, we focus on investigating the expressiveness of human avatars when learned from monocular RGB video; a setting that introduces new challenges in capturing and animating fine-grained details. To this end, we introduce EVA, a drivable human model that meticulously sculpts fine details based on 3D Gaussians and SMPL-X, an expressive parametric human model. Focused on enhancing expressiveness, our work makes three key contributions. First, we highlight the critical importance of aligning the SMPL-X model with RGB frames for effective avatar learning. Recognizing the limitations of current SMPL-X prediction methods for in-the-wild videos, we introduce a plug-and-play module that significantly ameliorates misalignment issues. Second, we propose a context-aware adaptive density control strategy, which is adaptively adjusting the gradient thresholds to accommodate the varied granularity across body parts. Last but not least, we develop a feedback mechanism that predicts per-pixel confidence to better guide the learning of 3D Gaussians. Extensive experiments on two benchmarks demonstrate the superiority of our framework both quantitatively and qualitatively, especially on the fine-grained hand and facial details. See the project website at \url{https://evahuman.github.io}
Outline, Then Details: Syntactically Guided Coarse-To-Fine Code Generation
May 08, 2023



For a complicated algorithm, its implementation by a human programmer usually starts with outlining a rough control flow followed by iterative enrichments, eventually yielding carefully generated syntactic structures and variables in a hierarchy. However, state-of-the-art large language models generate codes in a single pass, without intermediate warm-ups to reflect the structured thought process of "outline-then-detail". Inspired by the recent success of chain-of-thought prompting, we propose ChainCoder, a program synthesis language model that generates Python code progressively, i.e. from coarse to fine in multiple passes. We first decompose source code into layout frame components and accessory components via abstract syntax tree parsing to construct a hierarchical representation. We then reform our prediction target into a multi-pass objective, each pass generates a subsequence, which is concatenated in the hierarchy. Finally, a tailored transformer architecture is leveraged to jointly encode the natural language descriptions and syntactically aligned I/O data samples. Extensive evaluations show that ChainCoder outperforms state-of-the-arts, demonstrating that our progressive generation eases the reasoning procedure and guides the language model to generate higher-quality solutions. Our codes are available at: https://github.com/VITA-Group/ChainCoder.
Symbolic Visual Reinforcement Learning: A Scalable Framework with Object-Level Abstraction and Differentiable Expression Search
Dec 30, 2022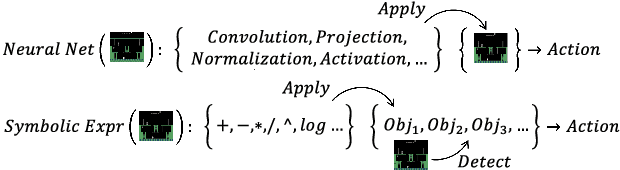
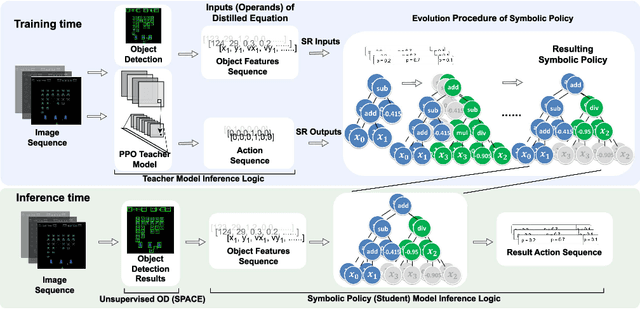
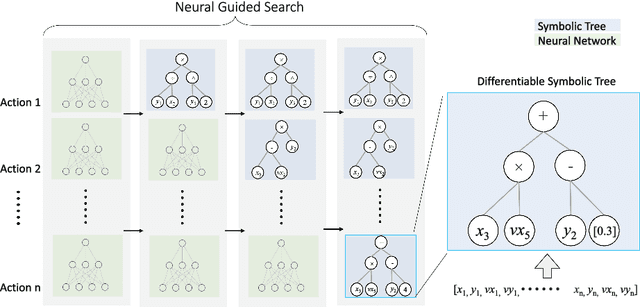
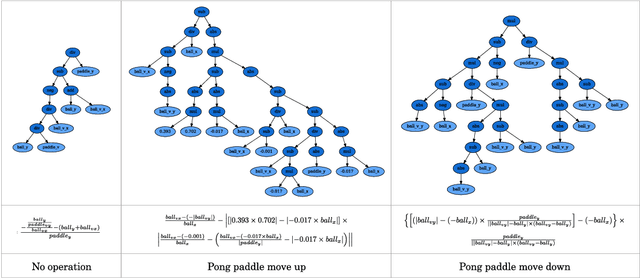
Learning efficient and interpretable policies has been a challenging task in reinforcement learning (RL), particularly in the visual RL setting with complex scenes. While neural networks have achieved competitive performance, the resulting policies are often over-parameterized black boxes that are difficult to interpret and deploy efficiently. More recent symbolic RL frameworks have shown that high-level domain-specific programming logic can be designed to handle both policy learning and symbolic planning. However, these approaches rely on coded primitives with little feature learning, and when applied to high-dimensional visual scenes, they can suffer from scalability issues and perform poorly when images have complex object interactions. To address these challenges, we propose \textit{Differentiable Symbolic Expression Search} (DiffSES), a novel symbolic learning approach that discovers discrete symbolic policies using partially differentiable optimization. By using object-level abstractions instead of raw pixel-level inputs, DiffSES is able to leverage the simplicity and scalability advantages of symbolic expressions, while also incorporating the strengths of neural networks for feature learning and optimization. Our experiments demonstrate that DiffSES is able to generate symbolic policies that are simpler and more and scalable than state-of-the-art symbolic RL methods, with a reduced amount of symbolic prior knowledge.