 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
May 28, 2026Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
Your Agents Are Aging Too: Agent Lifespan Engineering for Deployed Systems
May 25, 2026Long-lived AI agents are increasingly deployed as persistent operational systems, yet they are still evaluated like freshly initialized models. Day-one benchmarks miss a basic systems question: how long does an agent remain reliable after deployment? Even when model weights are frozen, an agent's effective state keeps changing as it compresses interaction history, retrieves from a growing memory store, revises facts after updates, and undergoes routine maintenance. Reliability therefore becomes a lifespan property of the full agent harness, not only a snapshot property of the base model. We introduce AgingBench, a longitudinal reliability benchmark for agent lifespan engineering: measuring not only whether deployed agents degrade, but what form the degradation takes and where repair should target. AgingBench organizes agent aging into four mechanisms: compression aging, interference aging, revision aging, and maintenance aging. To diagnose these failures, AgingBench uses temporal dependency graphs and paired counterfactual probes that produce diagnostic profiles for the write, retrieval, and utilization stages of the memory pipeline. Across 7 scenarios, 14 models, multiple memory policies, and both runner-controlled and autonomous agents, over ~400 runs spanning 8 - 200 sessions show that agent aging is not one-dimensional: behavioral tests can remain clean while factual precision decays; derived-state tracking can collapse sharply within a single model; and the same wrong answer can require different repairs depending on what the diagnostic profile points to. These results suggest that reliable agent deployment requires lifespan evaluation, mechanism-level diagnosis, and stage-targeted repair, not only stronger day-one models.
Distilling Game Code World Model Generation into Lightweight Large Language Models
May 23, 2026Large Language Models (LLMs) have shown great ability in generating executable code from natural language, opening the possibility of automatically constructing environments for AI agents. Recent work on Code World Models (CWMs) demonstrates that LLMs can translate game rules into Python implementations compatible with solvers like Monte Carlo Tree Search. We study this problem in game settings, where generated environments must implement rules, legal actions, state transitions, observations, and rewards. We refer to these game-specific executable models as Game Code World Models (GameCWMs). However, current approaches to generating code world models rely on frontier models and inference-time refinement loops, limiting accessibility and scalability. This work investigates whether GameCWM generation capabilities can be distilled into smaller models through post-training. We introduce: (1) a curated dataset of 30 games spanning perfect and imperfect information games, (2) a verification framework that evaluates generated code against structural and semantic game properties, and (3) a post-training pipeline combining Supervised Fine-Tuning (SFT) with Reinforcement Learning with Verifiable Rewards (RLVR). We experiment with Qwen2.5-3B-Instruct and find that SFT can increase syntactic correctness, while RLVR can improve execution-level adherence to game rules, thereby improving Qwen's ability to generate valid GameCWMs in both perfect and imperfect information games. Overall, our pipeline makes Qwen2.5-3B-Instruct more capable of generating valid GameCWMs, thereby offering a scalable path toward automatic environment generation from natural language.
HASS: Hierarchical Simulation of Logopenic Aphasic Speech for Scalable PPA Detection
Mar 25, 2026Building a diagnosis model for primary progressive aphasia (PPA) has been challenging due to the data scarcity. Collecting clinical data at scale is limited by the high vulnerability of clinical population and the high cost of expert labeling. To circumvent this, previous studies simulate dysfluent speech to generate training data. However, those approaches are not comprehensive enough to simulate PPA as holistic, multi-level phenotypes, instead relying on isolated dysfluencies. To address this, we propose a novel, clinically grounded simulation framework, Hierarchical Aphasic Speech Simulation (HASS). HASS aims to simulate behaviors of logopenic variant of PPA (lvPPA) with varying degrees of severity. To this end, semantic, phonological, and temporal deficits of lvPPA are systematically identified by clinical experts, and simulated. We demonstrate that our framework enables more accurate and generalizable detection models.
MEMO: Memory-Augmented Model Context Optimization for Robust Multi-Turn Multi-Agent LLM Games
Mar 09, 2026Multi-turn, multi-agent LLM game evaluations often exhibit substantial run-to-run variance. In long-horizon interactions, small early deviations compound across turns and are amplified by multi-agent coupling. This biases win rate estimates and makes rankings unreliable across repeated tournaments. Prompt choice worsens this further by producing different effective policies. We address both instability and underperformance with MEMO (Memory-augmented MOdel context optimization), a self-play framework that optimizes inference-time context by coupling retention and exploration. Retention maintains a persistent memory bank that stores structured insights from self-play trajectories and injects them as priors during later play. Exploration runs tournament-style prompt evolution with uncertainty-aware selection via TrueSkill, and uses prioritized replay to revisit rare and decisive states. Across five text-based games, MEMO raises mean win rate from 25.1% to 49.5% for GPT-4o-mini and from 20.9% to 44.3% for Qwen-2.5-7B-Instruct, using $2,000$ self-play games per task. Run-to-run variance also drops, giving more stable rankings across prompt variations. These results suggest that multi-agent LLM game performance and robustness have substantial room for improvement through context optimization. MEMO achieves the largest gains in negotiation and imperfect-information games, while RL remains more effective in perfect-information settings.
NeuroHex: Highly-Efficient Hex Coordinate System for Creating World Models to Enable Adaptive AI
Mar 03, 2026NeuroHex is a hexagonal coordinate system designed to support highly efficient world models and reference frames for online adaptive AI systems. Inspired by the hexadirectional firing structure of grid cells in the human brain, NeuroHex adopts a cubic isometric hexagonal coordinate formulation that provides full 60° rotational symmetry and low-cost translation, rotation and distance computation. We develop a mathematical framework that incorporates ring indexing, quantized angular encoding, and a hierarchical library of foundational, simple, and complex geometric shape primitives. These constructs allow low-overhead point-in-shape tests and spatial matching operations that are expensive in Cartesian coordinate systems. To support realistic settings, the NeuroHex framework can process OpenStreetMap (OSM) data sets using an OSM-to-NeuroHex (OSM2Hex) conversion tool. The OSM2Hex spatial abstraction processing pipeline can achieve a reduction of 90-99% in geometric complexity while maintaining the relevant spatial structure map for navigation. Our initial results, based on actual city and neighborhood scale data sets, demonstrate that NeuroHex offers a highly efficient substrate for building dynamic world models to enable adaptive spatial reasoning in autonomous AI systems with continuous online learning capability.
* 8 + 1 pages, 9 figures, published at NICE 2026
Can Generative Artificial Intelligence Survive Data Contamination? Theoretical Guarantees under Contaminated Recursive Training
Feb 17, 2026Generative Artificial Intelligence (AI), such as large language models (LLMs), has become a transformative force across science, industry, and society. As these systems grow in popularity, web data becomes increasingly interwoven with this AI-generated material and it is increasingly difficult to separate them from naturally generated content. As generative models are updated regularly, later models will inevitably be trained on mixtures of human-generated data and AI-generated data from earlier versions, creating a recursive training process with data contamination. Existing theoretical work has examined only highly simplified settings, where both the real data and the generative model are discrete or Gaussian, where it has been shown that such recursive training leads to model collapse. However, real data distributions are far more complex, and modern generative models are far more flexible than Gaussian and linear mechanisms. To fill this gap, we study recursive training in a general framework with minimal assumptions on the real data distribution and allow the underlying generative model to be a general universal approximator. In this framework, we show that contaminated recursive training still converges, with a convergence rate equal to the minimum of the baseline model's convergence rate and the fraction of real data used in each iteration. To the best of our knowledge, this is the first (positive) theoretical result on recursive training without distributional assumptions on the data. We further extend the analysis to settings where sampling bias is present in data collection and support all theoretical results with empirical studies.
Neurosymbolic LoRA: Why and When to Tune Weights vs. Rewrite Prompts
Jan 19, 2026Large language models (LLMs) can be adapted either through numerical updates that alter model parameters or symbolic manipulations that work on discrete prompts or logical constraints. While numerical fine-tuning excels at injecting new factual knowledge, symbolic updates offer flexible control of style and alignment without retraining. We introduce a neurosymbolic LoRA framework that dynamically combines these two complementary strategies. Specifically, we present a unified monitoring signal and a reward-based classifier to decide when to employ LoRA for deeper factual reconstruction and when to apply TextGrad for token-level edits. Our approach remains memory-efficient by offloading the symbolic transformations to an external LLM only when needed. Additionally, the refined prompts produced during symbolic editing serve as high-quality, reusable training data, an important benefit in data-scarce domains like mathematical reasoning. Extensive experiments across multiple LLM backbones show that neurosymbolic LoRA consistently outperforms purely numerical or purely symbolic baselines, demonstrating superior adaptability and improved performance. Our findings highlight the value of interleaving numerical and symbolic updates to unlock a new level of versatility in language model fine-tuning.
Enhancing Self-Driving Segmentation in Adverse Weather Conditions: A Dual Uncertainty-Aware Training Approach to SAM Optimization
Sep 05, 2025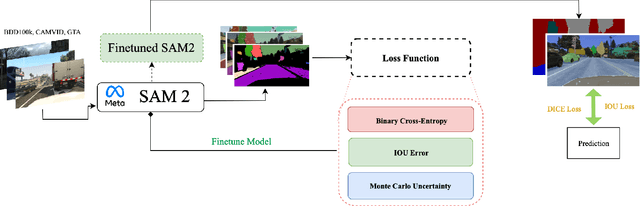



Recent advances in vision foundation models, such as the Segment Anything Model (SAM) and its successor SAM2, have achieved state-of-the-art performance on general image segmentation benchmarks. However, these models struggle in adverse weather conditions where visual ambiguity is high, largely due to their lack of uncertainty quantification. Inspired by progress in medical imaging, where uncertainty-aware training has improved reliability in ambiguous cases, we investigate two approaches to enhance segmentation robustness for autonomous driving. First, we introduce a multi-step finetuning procedure for SAM2 that incorporates uncertainty metrics directly into the loss function, improving overall scene recognition. Second, we adapt the Uncertainty-Aware Adapter (UAT), originally designed for medical image segmentation, to driving contexts. We evaluate both methods on CamVid, BDD100K, and GTA driving datasets. Experiments show that UAT-SAM outperforms standard SAM in extreme weather, while SAM2 with uncertainty-aware loss achieves improved performance across diverse driving scenes. These findings underscore the value of explicit uncertainty modeling for safety-critical autonomous driving in challenging environments.
FlexGS: Train Once, Deploy Everywhere with Many-in-One Flexible 3D Gaussian Splatting
Jun 04, 20253D Gaussian splatting (3DGS) has enabled various applications in 3D scene representation and novel view synthesis due to its efficient rendering capabilities. However, 3DGS demands relatively significant GPU memory, limiting its use on devices with restricted computational resources. Previous approaches have focused on pruning less important Gaussians, effectively compressing 3DGS but often requiring a fine-tuning stage and lacking adaptability for the specific memory needs of different devices. In this work, we present an elastic inference method for 3DGS. Given an input for the desired model size, our method selects and transforms a subset of Gaussians, achieving substantial rendering performance without additional fine-tuning. We introduce a tiny learnable module that controls Gaussian selection based on the input percentage, along with a transformation module that adjusts the selected Gaussians to complement the performance of the reduced model. Comprehensive experiments on ZipNeRF, MipNeRF and Tanks\&Temples scenes demonstrate the effectiveness of our approach. Code is available at https://flexgs.github.io.