 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrypto x AI, AI x Crypto: A Survey
Jun 11, 2026The intersection of crypto x AI is spawning papers, products, online posts, and companies. All the surrounding buzz, though, obscures what exactly has been done, what the opportunities and challenges are, and what open questions deserve attention. This survey paper asks what AI can do for blockchain-based technologies (broadly construed as "crypto") (crypto x AI), and vice versa (AI x crypto). We systematize existing work, summarize key takeaways, highlight open research questions, and offer a perspective on pervasive industry misconceptions, concluding that AI and crypto are still in the very early stages of meaningful integration.
MINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
May 28, 2026Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
MEMO: Memory-Augmented Model Context Optimization for Robust Multi-Turn Multi-Agent LLM Games
Mar 09, 2026Multi-turn, multi-agent LLM game evaluations often exhibit substantial run-to-run variance. In long-horizon interactions, small early deviations compound across turns and are amplified by multi-agent coupling. This biases win rate estimates and makes rankings unreliable across repeated tournaments. Prompt choice worsens this further by producing different effective policies. We address both instability and underperformance with MEMO (Memory-augmented MOdel context optimization), a self-play framework that optimizes inference-time context by coupling retention and exploration. Retention maintains a persistent memory bank that stores structured insights from self-play trajectories and injects them as priors during later play. Exploration runs tournament-style prompt evolution with uncertainty-aware selection via TrueSkill, and uses prioritized replay to revisit rare and decisive states. Across five text-based games, MEMO raises mean win rate from 25.1% to 49.5% for GPT-4o-mini and from 20.9% to 44.3% for Qwen-2.5-7B-Instruct, using $2,000$ self-play games per task. Run-to-run variance also drops, giving more stable rankings across prompt variations. These results suggest that multi-agent LLM game performance and robustness have substantial room for improvement through context optimization. MEMO achieves the largest gains in negotiation and imperfect-information games, while RL remains more effective in perfect-information settings.
TabularMath: Evaluating Computational Extrapolation in Tabular Learning via Program-Verified Synthesis
Jan 25, 2026Standard tabular benchmarks mainly focus on the evaluation of a model's capability to interpolate values inside a data manifold, where models good at performing local statistical smoothing are rewarded. However, there exists a very large category of high-value tabular data, including financial modeling and physical simulations, which are generated based upon deterministic computational processes, as opposed to stochastic and noisy relationships. Therefore, we investigate if tabular models can provide an extension from statistical interpolation to computational extrapolation. We propose TabularMath, a diagnostic benchmark of 114 deterministic problems (233,472 rows) generated from verified programs based on GSM8K and AIME. We evaluate 9 tabular architectures and in-context learning (ICL) with GPT-OSS-120B. On standard regression metrics, TabPFN v2.5 performs remarkably well, achieving R^2=0.998 in-distribution and maintaining positive R^2 even under distribution shift, which is unique among the tabular models we tested. When we measure rounded consistency (exact integer match), a different picture emerges: TabPFN v2.5 drops below 10% on out-of-distribution data, while ICL maintains around 40%. This gap between R^2 and exact-match accuracy suggests that tabular models learn smooth function approximations but struggle to recover precise computational outputs under extrapolation. The two paradigms appear complementary: TabPFN scales efficiently with data; ICL achieves exact computation from few examples. We release all code and data to support further investigation.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
Jun 13, 2025Recent reports claim that large language models (LLMs) now outperform elite humans in competitive programming. Drawing on knowledge from a group of medalists in international algorithmic contests, we revisit this claim, examining how LLMs differ from human experts and where limitations still remain. We introduce LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI that are continuously updated to reduce the likelihood of data contamination. A team of Olympiad medalists annotates every problem for algorithmic categories and conducts a line-by-line analysis of failed model-generated submissions. Using this new data and benchmark, we find that frontier models still have significant limitations: without external tools, the best model achieves only 53% pass@1 on medium-difficulty problems and 0% on hard problems, domains where expert humans still excel. We also find that LLMs succeed at implementation-heavy problems but struggle with nuanced algorithmic reasoning and complex case analysis, often generating confidently incorrect justifications. High performance appears largely driven by implementation precision and tool augmentation, not superior reasoning. LiveCodeBench Pro thus highlights the significant gap to human grandmaster levels, while offering fine-grained diagnostics to steer future improvements in code-centric LLM reasoning.
SPIN-Bench: How Well Do LLMs Plan Strategically and Reason Socially?
Mar 16, 2025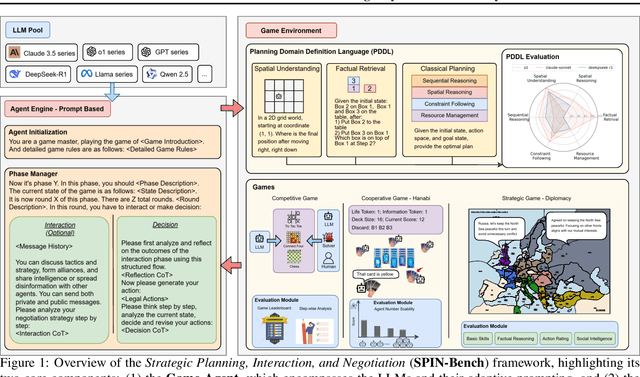
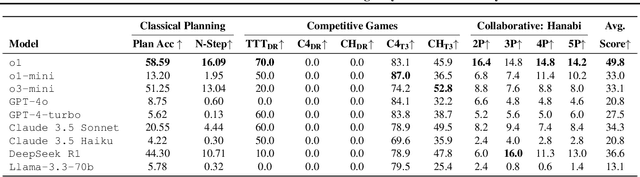

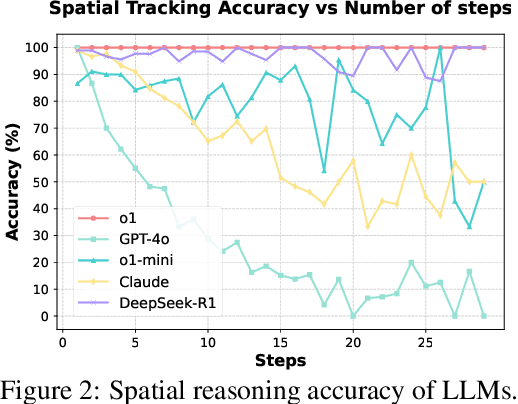
Reasoning and strategic behavior in \emph{social interactions} is a hallmark of intelligence. This form of reasoning is significantly more sophisticated than isolated planning or reasoning tasks in static settings (e.g., math problem solving). In this paper, we present \textit{Strategic Planning, Interaction, and Negotiation} (\textbf{SPIN-Bench}), a new multi-domain evaluation designed to measure the intelligence of \emph{strategic planning} and \emph{social reasoning}. While many existing benchmarks focus on narrow planning or single-agent reasoning, SPIN-Bench combines classical PDDL tasks, competitive board games, cooperative card games, and multi-agent negotiation scenarios in one unified framework. The framework includes both a benchmark as well as an arena to simulate and evaluate the variety of social settings to test reasoning and strategic behavior of AI agents. We formulate the benchmark SPIN-Bench by systematically varying action spaces, state complexity, and the number of interacting agents to simulate a variety of social settings where success depends on not only methodical and step-wise decision making, but also \emph{conceptual inference} of other (adversarial or cooperative) participants. Our experiments reveal that while contemporary LLMs handle \emph{basic fact retrieval} and \emph{short-range planning} reasonably well, they encounter significant performance bottlenecks in tasks requiring \emph{deep multi-hop reasoning} over large state spaces and \emph{socially adept} coordination under uncertainty. We envision SPIN-Bench as a catalyst for future research on robust multi-agent planning, social reasoning, and human--AI teaming.
A Benchmark for Understanding and Generating Dialogue between Characters in Stories
Sep 18, 2022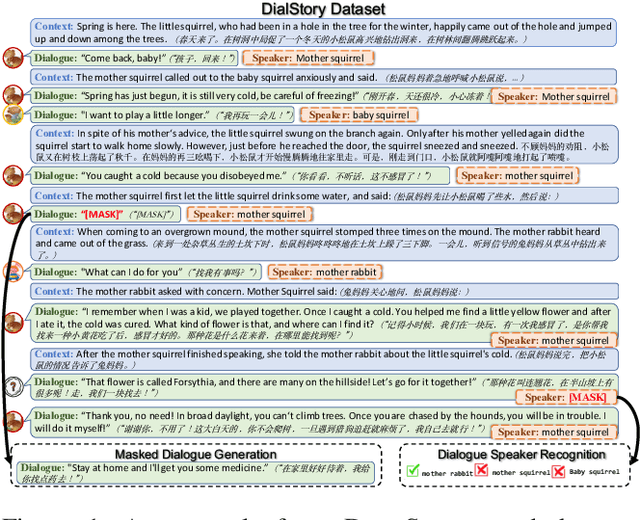
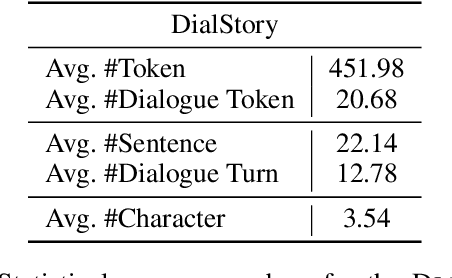
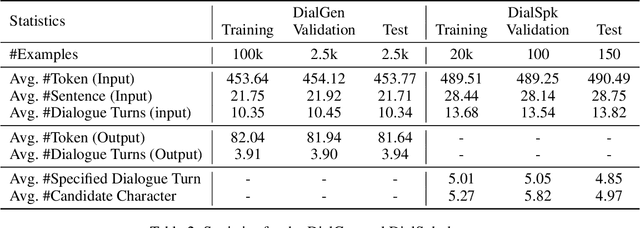
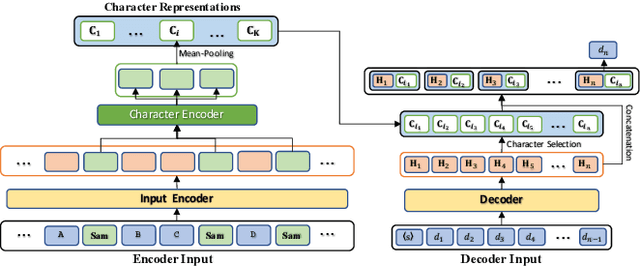
Many classical fairy tales, fiction, and screenplays leverage dialogue to advance story plots and establish characters. We present the first study to explore whether machines can understand and generate dialogue in stories, which requires capturing traits of different characters and the relationships between them. To this end, we propose two new tasks including Masked Dialogue Generation and Dialogue Speaker Recognition, i.e., generating missing dialogue turns and predicting speakers for specified dialogue turns, respectively. We build a new dataset DialStory, which consists of 105k Chinese stories with a large amount of dialogue weaved into the plots to support the evaluation. We show the difficulty of the proposed tasks by testing existing models with automatic and manual evaluation on DialStory. Furthermore, we propose to learn explicit character representations to improve performance on these tasks. Extensive experiments and case studies show that our approach can generate more coherent and informative dialogue, and achieve higher speaker recognition accuracy than strong baselines.
EVA2.0: Investigating Open-Domain Chinese Dialogue Systems with Large-Scale Pre-Training
Mar 17, 2022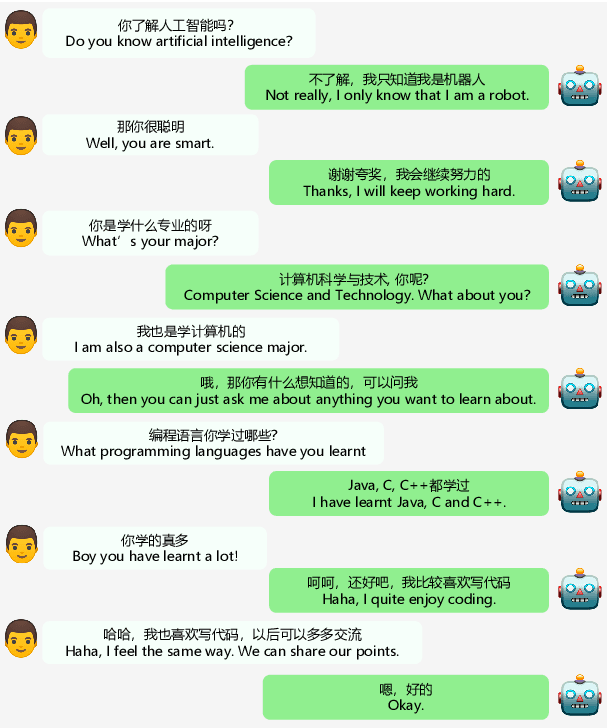


Large-scale pre-training has shown remarkable performance in building open-domain dialogue systems. However, previous works mainly focus on showing and evaluating the conversational performance of the released dialogue model, ignoring the discussion of some key factors towards a powerful human-like chatbot, especially in Chinese scenarios. In this paper, we conduct extensive experiments to investigate these under-explored factors, including data quality control, model architecture designs, training approaches, and decoding strategies. We propose EVA2.0, a large-scale pre-trained open-domain Chinese dialogue model with 2.8 billion parameters, and make our models and code publicly available. To our knowledge, EVA2.0 is the largest open-source Chinese dialogue model. Automatic and human evaluations show that our model significantly outperforms other open-source counterparts. We also discuss the limitations of this work by presenting some failure cases and pose some future directions.