 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoNorm: Unify Pre-Norm and Post-Norm with Geodesic Optimization
Jan 29, 2026The placement of normalization layers, specifically Pre-Norm and Post-Norm, remains an open question in Transformer architecture design. In this work, we rethink these approaches through the lens of manifold optimization, interpreting the outputs of the Feed-Forward Network (FFN) and attention layers as update directions in optimization. Building on this perspective, we introduce GeoNorm, a novel method that replaces standard normalization with geodesic updates on the manifold. Furthermore, analogous to learning rate schedules, we propose a layer-wise update decay for the FFN and attention components. Comprehensive experiments demonstrate that GeoNorm consistently outperforms existing normalization methods in Transformer models. Crucially, GeoNorm can be seamlessly integrated into standard Transformer architectures, achieving performance improvements with negligible additional computational cost.
SAS: Simulated Attention Score
Jul 10, 2025The attention mechanism is a core component of the Transformer architecture. Various methods have been developed to compute attention scores, including multi-head attention (MHA), multi-query attention, group-query attention and so on. We further analyze the MHA and observe that its performance improves as the number of attention heads increases, provided the hidden size per head remains sufficiently large. Therefore, increasing both the head count and hidden size per head with minimal parameter overhead can lead to significant performance gains at a low cost. Motivated by this insight, we introduce Simulated Attention Score (SAS), which maintains a compact model size while simulating a larger number of attention heads and hidden feature dimension per head. This is achieved by projecting a low-dimensional head representation into a higher-dimensional space, effectively increasing attention capacity without increasing parameter count. Beyond the head representations, we further extend the simulation approach to feature dimension of the key and query embeddings, enhancing expressiveness by mimicking the behavior of a larger model while preserving the original model size. To control the parameter cost, we also propose Parameter-Efficient Attention Aggregation (PEAA). Comprehensive experiments on a variety of datasets and tasks demonstrate the effectiveness of the proposed SAS method, achieving significant improvements over different attention variants.
FlexGS: Train Once, Deploy Everywhere with Many-in-One Flexible 3D Gaussian Splatting
Jun 04, 20253D Gaussian splatting (3DGS) has enabled various applications in 3D scene representation and novel view synthesis due to its efficient rendering capabilities. However, 3DGS demands relatively significant GPU memory, limiting its use on devices with restricted computational resources. Previous approaches have focused on pruning less important Gaussians, effectively compressing 3DGS but often requiring a fine-tuning stage and lacking adaptability for the specific memory needs of different devices. In this work, we present an elastic inference method for 3DGS. Given an input for the desired model size, our method selects and transforms a subset of Gaussians, achieving substantial rendering performance without additional fine-tuning. We introduce a tiny learnable module that controls Gaussian selection based on the input percentage, along with a transformation module that adjusts the selected Gaussians to complement the performance of the reduced model. Comprehensive experiments on ZipNeRF, MipNeRF and Tanks\&Temples scenes demonstrate the effectiveness of our approach. Code is available at https://flexgs.github.io.
Steepest Descent Density Control for Compact 3D Gaussian Splatting
May 08, 20253D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time, high-resolution novel view synthesis. By representing scenes as a mixture of Gaussian primitives, 3DGS leverages GPU rasterization pipelines for efficient rendering and reconstruction. To optimize scene coverage and capture fine details, 3DGS employs a densification algorithm to generate additional points. However, this process often leads to redundant point clouds, resulting in excessive memory usage, slower performance, and substantial storage demands - posing significant challenges for deployment on resource-constrained devices. To address this limitation, we propose a theoretical framework that demystifies and improves density control in 3DGS. Our analysis reveals that splitting is crucial for escaping saddle points. Through an optimization-theoretic approach, we establish the necessary conditions for densification, determine the minimal number of offspring Gaussians, identify the optimal parameter update direction, and provide an analytical solution for normalizing off-spring opacity. Building on these insights, we introduce SteepGS, incorporating steepest density control, a principled strategy that minimizes loss while maintaining a compact point cloud. SteepGS achieves a ~50% reduction in Gaussian points without compromising rendering quality, significantly enhancing both efficiency and scalability.
Understanding and Mitigating Bottlenecks of State Space Models through the Lens of Recency and Over-smoothing
Dec 31, 2024



Structured State Space Models (SSMs) have emerged as alternatives to transformers. While SSMs are often regarded as effective in capturing long-sequence dependencies, we rigorously demonstrate that they are inherently limited by strong recency bias. Our empirical studies also reveal that this bias impairs the models' ability to recall distant information and introduces robustness issues. Our scaling experiments then discovered that deeper structures in SSMs can facilitate the learning of long contexts. However, subsequent theoretical analysis reveals that as SSMs increase in depth, they exhibit another inevitable tendency toward over-smoothing, e.g., token representations becoming increasingly indistinguishable. This fundamental dilemma between recency and over-smoothing hinders the scalability of existing SSMs. Inspired by our theoretical findings, we propose to polarize two channels of the state transition matrices in SSMs, setting them to zero and one, respectively, simultaneously addressing recency bias and over-smoothing. Experiments demonstrate that our polarization technique consistently enhances the associative recall accuracy of long-range tokens and unlocks SSMs to benefit further from deeper architectures. All source codes are released at https://github.com/VITA-Group/SSM-Bottleneck.
Oscillation Inversion: Understand the structure of Large Flow Model through the Lens of Inversion Method
Nov 17, 2024



We explore the oscillatory behavior observed in inversion methods applied to large-scale text-to-image diffusion models, with a focus on the "Flux" model. By employing a fixed-point-inspired iterative approach to invert real-world images, we observe that the solution does not achieve convergence, instead oscillating between distinct clusters. Through both toy experiments and real-world diffusion models, we demonstrate that these oscillating clusters exhibit notable semantic coherence. We offer theoretical insights, showing that this behavior arises from oscillatory dynamics in rectified flow models. Building on this understanding, we introduce a simple and fast distribution transfer technique that facilitates image enhancement, stroke-based recoloring, as well as visual prompt-guided image editing. Furthermore, we provide quantitative results demonstrating the effectiveness of our method for tasks such as image enhancement, makeup transfer, reconstruction quality, and guided sampling quality. Higher-quality examples of videos and images are available at \href{https://yanyanzheng96.github.io/oscillation_inversion/}{this link}.
Bilateral Guided Radiance Field Processing
Jun 01, 2024
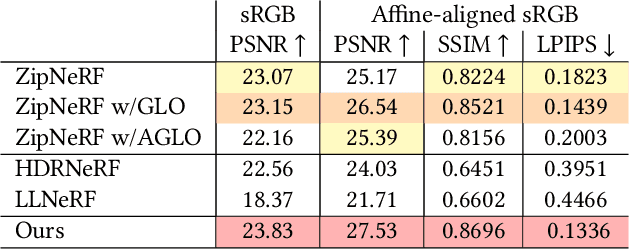

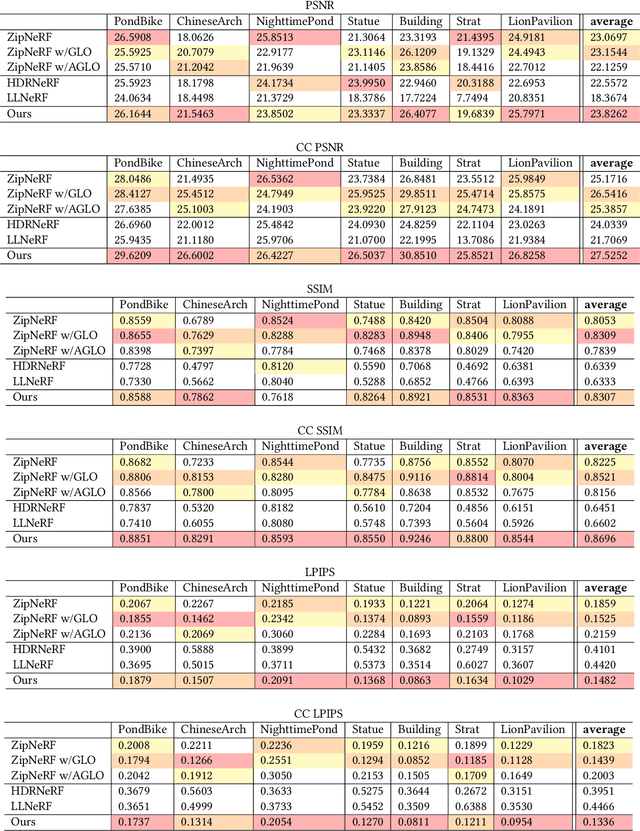
Neural Radiance Fields (NeRF) achieves unprecedented performance in synthesizing novel view synthesis, utilizing multi-view consistency. When capturing multiple inputs, image signal processing (ISP) in modern cameras will independently enhance them, including exposure adjustment, color correction, local tone mapping, etc. While these processings greatly improve image quality, they often break the multi-view consistency assumption, leading to "floaters" in the reconstructed radiance fields. To address this concern without compromising visual aesthetics, we aim to first disentangle the enhancement by ISP at the NeRF training stage and re-apply user-desired enhancements to the reconstructed radiance fields at the finishing stage. Furthermore, to make the re-applied enhancements consistent between novel views, we need to perform imaging signal processing in 3D space (i.e. "3D ISP"). For this goal, we adopt the bilateral grid, a locally-affine model, as a generalized representation of ISP processing. Specifically, we optimize per-view 3D bilateral grids with radiance fields to approximate the effects of camera pipelines for each input view. To achieve user-adjustable 3D finishing, we propose to learn a low-rank 4D bilateral grid from a given single view edit, lifting photo enhancements to the whole 3D scene. We demonstrate our approach can boost the visual quality of novel view synthesis by effectively removing floaters and performing enhancements from user retouching. The source code and our data are available at: https://bilarfpro.github.io.
EndoGSLAM: Real-Time Dense Reconstruction and Tracking in Endoscopic Surgeries using Gaussian Splatting
Mar 22, 2024Precise camera tracking, high-fidelity 3D tissue reconstruction, and real-time online visualization are critical for intrabody medical imaging devices such as endoscopes and capsule robots. However, existing SLAM (Simultaneous Localization and Mapping) methods often struggle to achieve both complete high-quality surgical field reconstruction and efficient computation, restricting their intraoperative applications among endoscopic surgeries. In this paper, we introduce EndoGSLAM, an efficient SLAM approach for endoscopic surgeries, which integrates streamlined Gaussian representation and differentiable rasterization to facilitate over 100 fps rendering speed during online camera tracking and tissue reconstructing. Extensive experiments show that EndoGSLAM achieves a better trade-off between intraoperative availability and reconstruction quality than traditional or neural SLAM approaches, showing tremendous potential for endoscopic surgeries. The project page is at https://EndoGSLAM.loping151.com
Efficient Deformable Tissue Reconstruction via Orthogonal Neural Plane
Dec 23, 2023Intraoperative imaging techniques for reconstructing deformable tissues in vivo are pivotal for advanced surgical systems. Existing methods either compromise on rendering quality or are excessively computationally intensive, often demanding dozens of hours to perform, which significantly hinders their practical application. In this paper, we introduce Fast Orthogonal Plane (Forplane), a novel, efficient framework based on neural radiance fields (NeRF) for the reconstruction of deformable tissues. We conceptualize surgical procedures as 4D volumes, and break them down into static and dynamic fields comprised of orthogonal neural planes. This factorization iscretizes the four-dimensional space, leading to a decreased memory usage and faster optimization. A spatiotemporal importance sampling scheme is introduced to improve performance in regions with tool occlusion as well as large motions and accelerate training. An efficient ray marching method is applied to skip sampling among empty regions, significantly improving inference speed. Forplane accommodates both binocular and monocular endoscopy videos, demonstrating its extensive applicability and flexibility. Our experiments, carried out on two in vivo datasets, the EndoNeRF and Hamlyn datasets, demonstrate the effectiveness of our framework. In all cases, Forplane substantially accelerates both the optimization process (by over 100 times) and the inference process (by over 15 times) while maintaining or even improving the quality across a variety of non-rigid deformations. This significant performance improvement promises to be a valuable asset for future intraoperative surgical applications. The code of our project is now available at https://github.com/Loping151/ForPlane.
Neural LerPlane Representations for Fast 4D Reconstruction of Deformable Tissues
May 31, 2023Reconstructing deformable tissues from endoscopic stereo videos in robotic surgery is crucial for various clinical applications. However, existing methods relying only on implicit representations are computationally expensive and require dozens of hours, which limits further practical applications. To address this challenge, we introduce LerPlane, a novel method for fast and accurate reconstruction of surgical scenes under a single-viewpoint setting. LerPlane treats surgical procedures as 4D volumes and factorizes them into explicit 2D planes of static and dynamic fields, leading to a compact memory footprint and significantly accelerated optimization. The efficient factorization is accomplished by fusing features obtained through linear interpolation of each plane and enables using lightweight neural networks to model surgical scenes. Besides, LerPlane shares static fields, significantly reducing the workload of dynamic tissue modeling. We also propose a novel sample scheme to boost optimization and improve performance in regions with tool occlusion and large motions. Experiments on DaVinci robotic surgery videos demonstrate that LerPlane accelerates optimization by over 100$\times$ while maintaining high quality across various non-rigid deformations, showing significant promise for future intraoperative surgery applications.