 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Blobs to Spokes: High-Fidelity Surface Reconstruction via Oriented Gaussians
Apr 08, 20263D Gaussian Splatting (3DGS) has revolutionized fast novel view synthesis, yet its opacity-based formulation makes surface extraction fundamentally difficult. Unlike implicit methods built on Signed Distance Fields or occupancy, 3DGS lacks a global geometric field, forcing existing approaches to resort to heuristics such as TSDF fusion of blended depth maps. Inspired by the Objects as Volumes framework, we derive a principled occupancy field for Gaussian Splatting and show how it can be used to extract highly accurate watertight meshes of complex scenes. Our key contribution is to introduce a learnable oriented normal at each Gaussian element and to define an adapted attenuation formulation, which leads to closed-form expressions for both the normal and occupancy fields at arbitrary locations in space. We further introduce a novel consistency loss and a dedicated densification strategy to enforce Gaussians to wrap the entire surface by closing geometric holes, ensuring a complete shell of oriented primitives. We modify the differentiable rasterizer to output depth as an isosurface of our continuous model, and introduce Primal Adaptive Meshing for Region-of-Interest meshing at arbitrary resolution. We additionally expose fundamental biases in standard surface evaluation protocols and propose two more rigorous alternatives. Overall, our method Gaussian Wrapping sets a new state-of-the-art on DTU and Tanks and Temples, producing complete, watertight meshes at a fraction of the size of concurrent work-recovering thin structures such as the notoriously elusive bicycle spokes.
PatchAlign3D: Local Feature Alignment for Dense 3D Shape understanding
Jan 05, 2026Current foundation models for 3D shapes excel at global tasks (retrieval, classification) but transfer poorly to local part-level reasoning. Recent approaches leverage vision and language foundation models to directly solve dense tasks through multi-view renderings and text queries. While promising, these pipelines require expensive inference over multiple renderings, depend heavily on large language-model (LLM) prompt engineering for captions, and fail to exploit the inherent 3D geometry of shapes. We address this gap by introducing an encoder-only 3D model that produces language-aligned patch-level features directly from point clouds. Our pre-training approach builds on existing data engines that generate part-annotated 3D shapes by pairing multi-view SAM regions with VLM captioning. Using this data, we train a point cloud transformer encoder in two stages: (1) distillation of dense 2D features from visual encoders such as DINOv2 into 3D patches, and (2) alignment of these patch embeddings with part-level text embeddings through a multi-positive contrastive objective. Our 3D encoder achieves zero-shot 3D part segmentation with fast single-pass inference without any test-time multi-view rendering, while significantly outperforming previous rendering-based and feed-forward approaches across several 3D part segmentation benchmarks. Project website: https://souhail-hadgi.github.io/patchalign3dsite/
FourieRF: Few-Shot NeRFs via Progressive Fourier Frequency Control
Feb 03, 2025In this work, we introduce FourieRF, a novel approach for achieving fast and high-quality reconstruction in the few-shot setting. Our method effectively parameterizes features through an explicit curriculum training procedure, incrementally increasing scene complexity during optimization. Experimental results show that the prior induced by our approach is both robust and adaptable across a wide variety of scenes, establishing FourieRF as a strong and versatile baseline for the few-shot rendering problem. While our approach significantly reduces artifacts, it may still lead to reconstruction errors in severely under-constrained scenarios, particularly where view occlusion leaves parts of the shape uncovered. In the future, our method could be enhanced by integrating foundation models to complete missing parts using large data-driven priors.
ZeroKey: Point-Level Reasoning and Zero-Shot 3D Keypoint Detection from Large Language Models
Dec 09, 2024



We propose a novel zero-shot approach for keypoint detection on 3D shapes. Point-level reasoning on visual data is challenging as it requires precise localization capability, posing problems even for powerful models like DINO or CLIP. Traditional methods for 3D keypoint detection rely heavily on annotated 3D datasets and extensive supervised training, limiting their scalability and applicability to new categories or domains. In contrast, our method utilizes the rich knowledge embedded within Multi-Modal Large Language Models (MLLMs). Specifically, we demonstrate, for the first time, that pixel-level annotations used to train recent MLLMs can be exploited for both extracting and naming salient keypoints on 3D models without any ground truth labels or supervision. Experimental evaluations demonstrate that our approach achieves competitive performance on standard benchmarks compared to supervised methods, despite not requiring any 3D keypoint annotations during training. Our results highlight the potential of integrating language models for localized 3D shape understanding. This work opens new avenues for cross-modal learning and underscores the effectiveness of MLLMs in contributing to 3D computer vision challenges.
Towards Realistic Example-based Modeling via 3D Gaussian Stitching
Aug 28, 2024Using parts of existing models to rebuild new models, commonly termed as example-based modeling, is a classical methodology in the realm of computer graphics. Previous works mostly focus on shape composition, making them very hard to use for realistic composition of 3D objects captured from real-world scenes. This leads to combining multiple NeRFs into a single 3D scene to achieve seamless appearance blending. However, the current SeamlessNeRF method struggles to achieve interactive editing and harmonious stitching for real-world scenes due to its gradient-based strategy and grid-based representation. To this end, we present an example-based modeling method that combines multiple Gaussian fields in a point-based representation using sample-guided synthesis. Specifically, as for composition, we create a GUI to segment and transform multiple fields in real time, easily obtaining a semantically meaningful composition of models represented by 3D Gaussian Splatting (3DGS). For texture blending, due to the discrete and irregular nature of 3DGS, straightforwardly applying gradient propagation as SeamlssNeRF is not supported. Thus, a novel sampling-based cloning method is proposed to harmonize the blending while preserving the original rich texture and content. Our workflow consists of three steps: 1) real-time segmentation and transformation of a Gaussian model using a well-tailored GUI, 2) KNN analysis to identify boundary points in the intersecting area between the source and target models, and 3) two-phase optimization of the target model using sampling-based cloning and gradient constraints. Extensive experimental results validate that our approach significantly outperforms previous works in terms of realistic synthesis, demonstrating its practicality. More demos are available at https://ingra14m.github.io/gs_stitching_website.
Bilateral Guided Radiance Field Processing
Jun 01, 2024
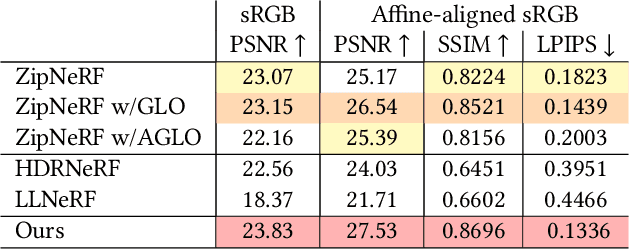

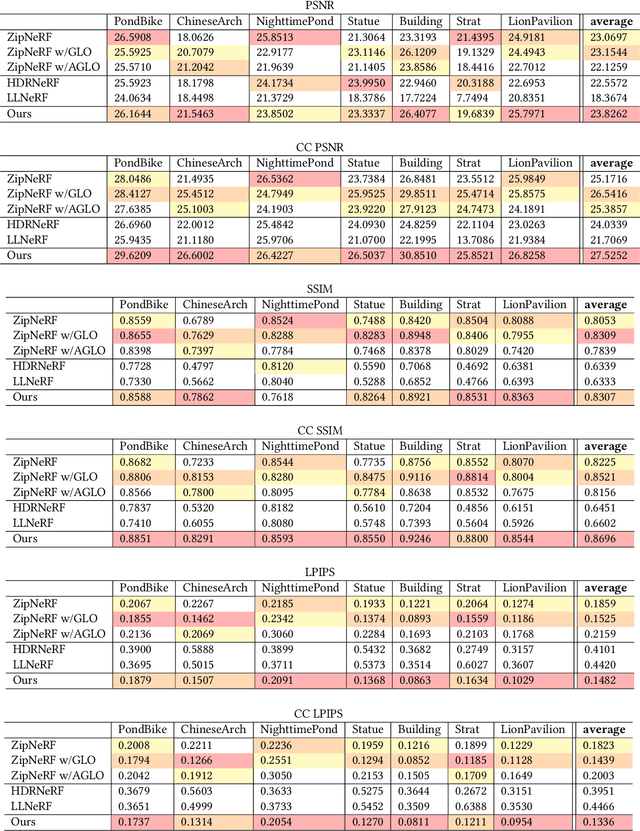
Neural Radiance Fields (NeRF) achieves unprecedented performance in synthesizing novel view synthesis, utilizing multi-view consistency. When capturing multiple inputs, image signal processing (ISP) in modern cameras will independently enhance them, including exposure adjustment, color correction, local tone mapping, etc. While these processings greatly improve image quality, they often break the multi-view consistency assumption, leading to "floaters" in the reconstructed radiance fields. To address this concern without compromising visual aesthetics, we aim to first disentangle the enhancement by ISP at the NeRF training stage and re-apply user-desired enhancements to the reconstructed radiance fields at the finishing stage. Furthermore, to make the re-applied enhancements consistent between novel views, we need to perform imaging signal processing in 3D space (i.e. "3D ISP"). For this goal, we adopt the bilateral grid, a locally-affine model, as a generalized representation of ISP processing. Specifically, we optimize per-view 3D bilateral grids with radiance fields to approximate the effects of camera pipelines for each input view. To achieve user-adjustable 3D finishing, we propose to learn a low-rank 4D bilateral grid from a given single view edit, lifting photo enhancements to the whole 3D scene. We demonstrate our approach can boost the visual quality of novel view synthesis by effectively removing floaters and performing enhancements from user retouching. The source code and our data are available at: https://bilarfpro.github.io.
Deform3DGS: Flexible Deformation for Fast Surgical Scene Reconstruction with Gaussian Splatting
May 29, 2024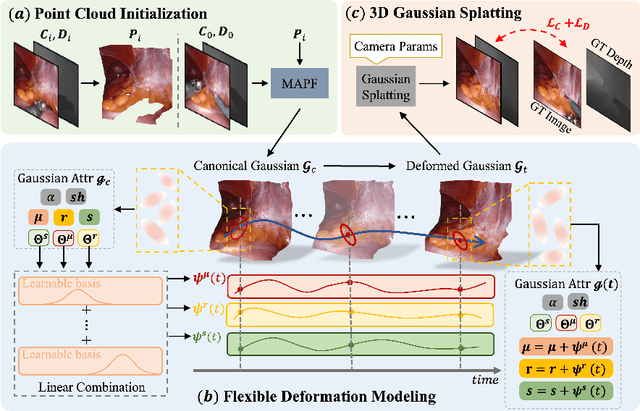
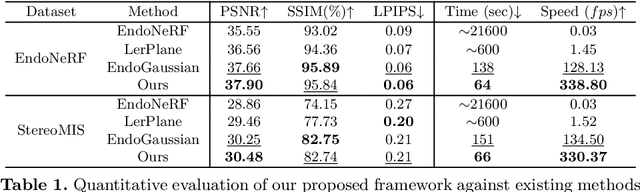

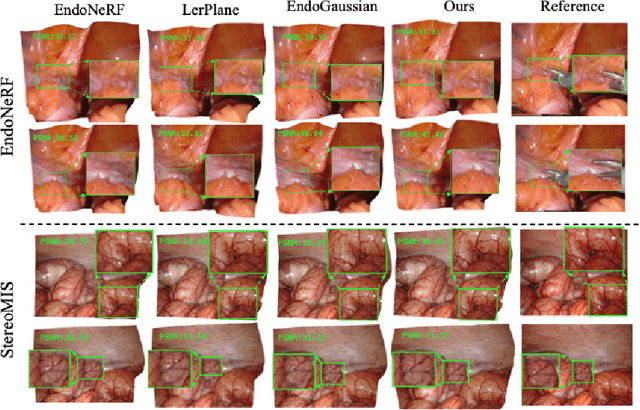
Tissue deformation poses a key challenge for accurate surgical scene reconstruction. Despite yielding high reconstruction quality, existing methods suffer from slow rendering speeds and long training times, limiting their intraoperative applicability. Motivated by recent progress in 3D Gaussian Splatting, an emerging technology in real-time 3D rendering, this work presents a novel fast reconstruction framework, termed Deform3DGS, for deformable tissues during endoscopic surgery. Specifically, we introduce 3D GS into surgical scenes by integrating a point cloud initialization to improve reconstruction. Furthermore, we propose a novel flexible deformation modeling scheme (FDM) to learn tissue deformation dynamics at the level of individual Gaussians. Our FDM can model the surface deformation with efficient representations, allowing for real-time rendering performance. More importantly, FDM significantly accelerates surgical scene reconstruction, demonstrating considerable clinical values, particularly in intraoperative settings where time efficiency is crucial. Experiments on DaVinci robotic surgery videos indicate the efficacy of our approach, showcasing superior reconstruction fidelity PSNR: (37.90) and rendering speed (338.8 FPS) while substantially reducing training time to only 1 minute/scene.
RecolorNeRF: Layer Decomposed Radiance Field for Efficient Color Editing of 3D Scenes
Jan 19, 2023



Radiance fields have gradually become a main representation of media. Although its appearance editing has been studied, how to achieve view-consistent recoloring in an efficient manner is still under explored. We present RecolorNeRF, a novel user-friendly color editing approach for the neural radiance field. Our key idea is to decompose the scene into a set of pure-colored layers, forming a palette. Thus, color manipulation can be conducted by altering the color components of the palette directly. To support efficient palette-based editing, the color of each layer needs to be as representative as possible. In the end, the problem is formulated as in an optimization formula, where the layers and their blending way are jointly optimized with the NeRF itself. Extensive experiments show that our jointly-optimized layer decomposition can be used against multiple backbones and produce photo-realistic recolored novel-view renderings. We demonstrate that RecolorNeRF outperforms baseline methods both quantitatively and qualitatively for color editing even in complex real-world scenes.
ME-PCN: Point Completion Conditioned on Mask Emptiness
Aug 18, 2021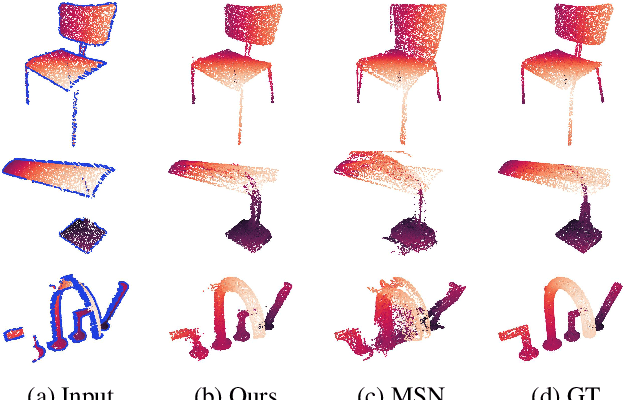
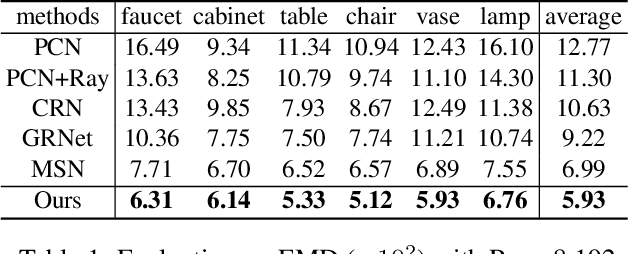
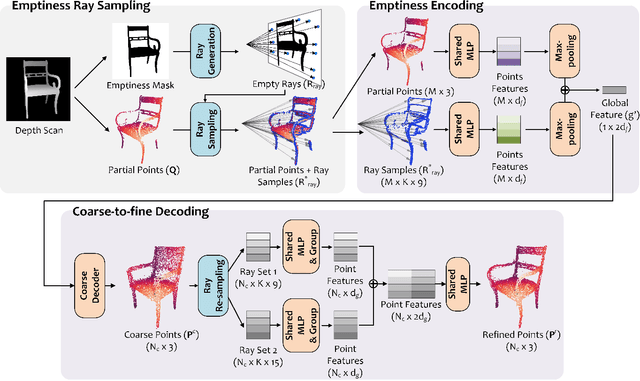
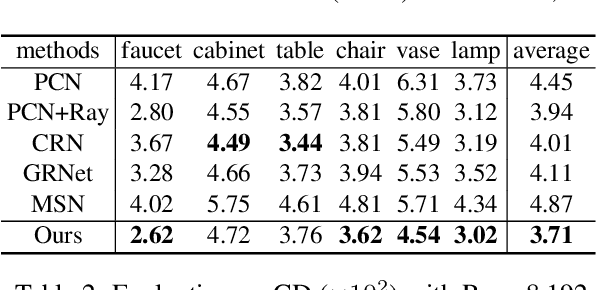
Point completion refers to completing the missing geometries of an object from incomplete observations. Main-stream methods predict the missing shapes by decoding a global feature learned from the input point cloud, which often leads to deficient results in preserving topology consistency and surface details. In this work, we present ME-PCN, a point completion network that leverages `emptiness' in 3D shape space. Given a single depth scan, previous methods often encode the occupied partial shapes while ignoring the empty regions (e.g. holes) in depth maps. In contrast, we argue that these `emptiness' clues indicate shape boundaries that can be used to improve topology representation and detail granularity on surfaces. Specifically, our ME-PCN encodes both the occupied point cloud and the neighboring `empty points'. It estimates coarse-grained but complete and reasonable surface points in the first stage, followed by a refinement stage to produce fine-grained surface details. Comprehensive experiments verify that our ME-PCN presents better qualitative and quantitative performance against the state-of-the-art. Besides, we further prove that our `emptiness' design is lightweight and easy to embed in existing methods, which shows consistent effectiveness in improving the CD and EMD scores.
Image Super-Resolution via Deterministic-Stochastic Synthesis and Local Statistical Rectification
Sep 18, 2018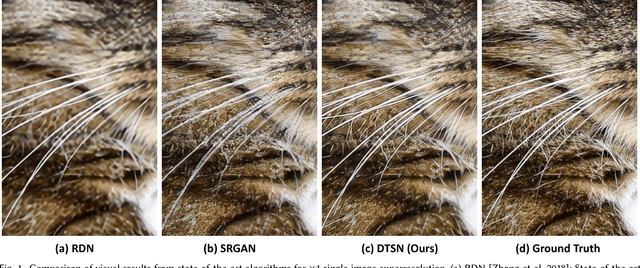
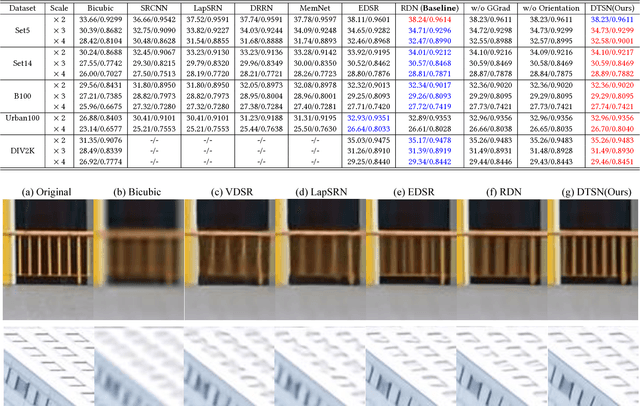

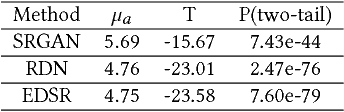
Single image superresolution has been a popular research topic in the last two decades and has recently received a new wave of interest due to deep neural networks. In this paper, we approach this problem from a different perspective. With respect to a downsampled low resolution image, we model a high resolution image as a combination of two components, a deterministic component and a stochastic component. The deterministic component can be recovered from the low-frequency signals in the downsampled image. The stochastic component, on the other hand, contains the signals that have little correlation with the low resolution image. We adopt two complementary methods for generating these two components. While generative adversarial networks are used for the stochastic component, deterministic component reconstruction is formulated as a regression problem solved using deep neural networks. Since the deterministic component exhibits clearer local orientations, we design novel loss functions tailored for such properties for training the deep regression network. These two methods are first applied to the entire input image to produce two distinct high-resolution images. Afterwards, these two images are fused together using another deep neural network that also performs local statistical rectification, which tries to make the local statistics of the fused image match the same local statistics of the groundtruth image. Quantitative results and a user study indicate that the proposed method outperforms existing state-of-the-art algorithms with a clear margin.