 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic LoRA: Why and When to Tune Weights vs. Rewrite Prompts
Jan 19, 2026Large language models (LLMs) can be adapted either through numerical updates that alter model parameters or symbolic manipulations that work on discrete prompts or logical constraints. While numerical fine-tuning excels at injecting new factual knowledge, symbolic updates offer flexible control of style and alignment without retraining. We introduce a neurosymbolic LoRA framework that dynamically combines these two complementary strategies. Specifically, we present a unified monitoring signal and a reward-based classifier to decide when to employ LoRA for deeper factual reconstruction and when to apply TextGrad for token-level edits. Our approach remains memory-efficient by offloading the symbolic transformations to an external LLM only when needed. Additionally, the refined prompts produced during symbolic editing serve as high-quality, reusable training data, an important benefit in data-scarce domains like mathematical reasoning. Extensive experiments across multiple LLM backbones show that neurosymbolic LoRA consistently outperforms purely numerical or purely symbolic baselines, demonstrating superior adaptability and improved performance. Our findings highlight the value of interleaving numerical and symbolic updates to unlock a new level of versatility in language model fine-tuning.
RepV: Safety-Separable Latent Spaces for Scalable Neurosymbolic Plan Verification
Oct 30, 2025As AI systems migrate to safety-critical domains, verifying that their actions comply with well-defined rules remains a challenge. Formal methods provide provable guarantees but demand hand-crafted temporal-logic specifications, offering limited expressiveness and accessibility. Deep learning approaches enable evaluation of plans against natural-language constraints, yet their opaque decision process invites misclassifications with potentially severe consequences. We introduce RepV, a neurosymbolic verifier that unifies both views by learning a latent space where safe and unsafe plans are linearly separable. Starting from a modest seed set of plans labeled by an off-the-shelf model checker, RepV trains a lightweight projector that embeds each plan, together with a language model-generated rationale, into a low-dimensional space; a frozen linear boundary then verifies compliance for unseen natural-language rules in a single forward pass. Beyond binary classification, RepV provides a probabilistic guarantee on the likelihood of correct verification based on its position in the latent space. This guarantee enables a guarantee-driven refinement of the planner, improving rule compliance without human annotations. Empirical evaluations show that RepV improves compliance prediction accuracy by up to 15% compared to baseline methods while adding fewer than 0.2M parameters. Furthermore, our refinement framework outperforms ordinary fine-tuning baselines across various planning domains. These results show that safety-separable latent spaces offer a scalable, plug-and-play primitive for reliable neurosymbolic plan verification. Code and data are available at: https://repv-project.github.io/.
Foundation Models for Logistics: Toward Certifiable, Conversational Planning Interfaces
Jul 15, 2025Logistics operators, from battlefield coordinators rerouting airlifts ahead of a storm to warehouse managers juggling late trucks, often face life-critical decisions that demand both domain expertise and rapid and continuous replanning. While popular methods like integer programming yield logistics plans that satisfy user-defined logical constraints, they are slow and assume an idealized mathematical model of the environment that does not account for uncertainty. On the other hand, large language models (LLMs) can handle uncertainty and promise to accelerate replanning while lowering the barrier to entry by translating free-form utterances into executable plans, yet they remain prone to misinterpretations and hallucinations that jeopardize safety and cost. We introduce a neurosymbolic framework that pairs the accessibility of natural-language dialogue with verifiable guarantees on goal interpretation. It converts user requests into structured planning specifications, quantifies its own uncertainty at the field and token level, and invokes an interactive clarification loop whenever confidence falls below an adaptive threshold. A lightweight model, fine-tuned on just 100 uncertainty-filtered examples, surpasses the zero-shot performance of GPT-4.1 while cutting inference latency by nearly 50%. These preliminary results highlight a practical path toward certifiable, real-time, and user-aligned decision-making for complex logistics.
Real-Time Privacy Preservation for Robot Visual Perception
May 08, 2025



Many robots (e.g., iRobot's Roomba) operate based on visual observations from live video streams, and such observations may inadvertently include privacy-sensitive objects, such as personal identifiers. Existing approaches for preserving privacy rely on deep learning models, differential privacy, or cryptography. They lack guarantees for the complete concealment of all sensitive objects. Guaranteeing concealment requires post-processing techniques and thus is inadequate for real-time video streams. We develop a method for privacy-constrained video streaming, PCVS, that conceals sensitive objects within real-time video streams. PCVS takes a logical specification constraining the existence of privacy-sensitive objects, e.g., never show faces when a person exists. It uses a detection model to evaluate the existence of these objects in each incoming frame. Then, it blurs out a subset of objects such that the existence of the remaining objects satisfies the specification. We then propose a conformal prediction approach to (i) establish a theoretical lower bound on the probability of the existence of these objects in a sequence of frames satisfying the specification and (ii) update the bound with the arrival of each subsequent frame. Quantitative evaluations show that PCVS achieves over 95 percent specification satisfaction rate in multiple datasets, significantly outperforming other methods. The satisfaction rate is consistently above the theoretical bounds across all datasets, indicating that the established bounds hold. Additionally, we deploy PCVS on robots in real-time operation and show that the robots operate normally without being compromised when PCVS conceals objects.
Know Where You're Uncertain When Planning with Multimodal Foundation Models: A Formal Framework
Nov 03, 2024Multimodal foundation models offer a promising framework for robotic perception and planning by processing sensory inputs to generate actionable plans. However, addressing uncertainty in both perception (sensory interpretation) and decision-making (plan generation) remains a critical challenge for ensuring task reliability. We present a comprehensive framework to disentangle, quantify, and mitigate these two forms of uncertainty. We first introduce a framework for uncertainty disentanglement, isolating perception uncertainty arising from limitations in visual understanding and decision uncertainty relating to the robustness of generated plans. To quantify each type of uncertainty, we propose methods tailored to the unique properties of perception and decision-making: we use conformal prediction to calibrate perception uncertainty and introduce Formal-Methods-Driven Prediction (FMDP) to quantify decision uncertainty, leveraging formal verification techniques for theoretical guarantees. Building on this quantification, we implement two targeted intervention mechanisms: an active sensing process that dynamically re-observes high-uncertainty scenes to enhance visual input quality and an automated refinement procedure that fine-tunes the model on high-certainty data, improving its capability to meet task specifications. Empirical validation in real-world and simulated robotic tasks demonstrates that our uncertainty disentanglement framework reduces variability by up to 40% and enhances task success rates by 5% compared to baselines. These improvements are attributed to the combined effect of both interventions and highlight the importance of uncertainty disentanglement which facilitates targeted interventions that enhance the robustness and reliability of autonomous systems.
On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
Sep 30, 2024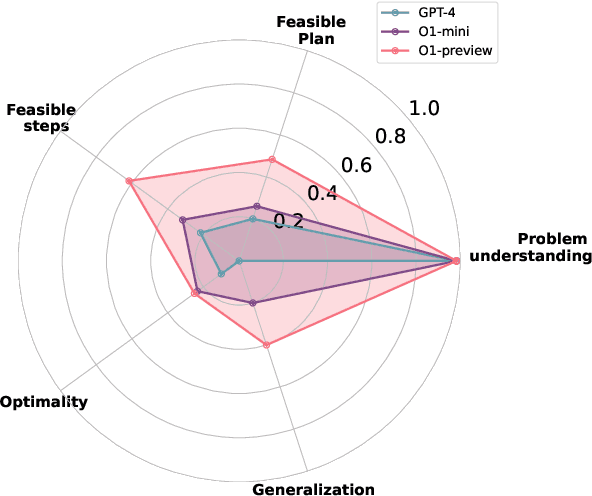
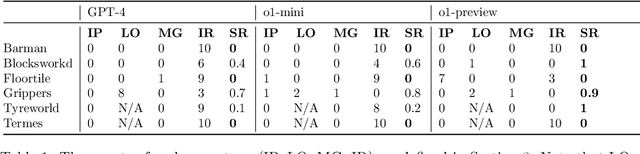
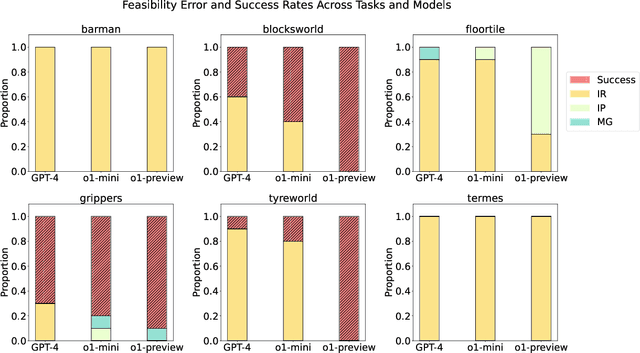
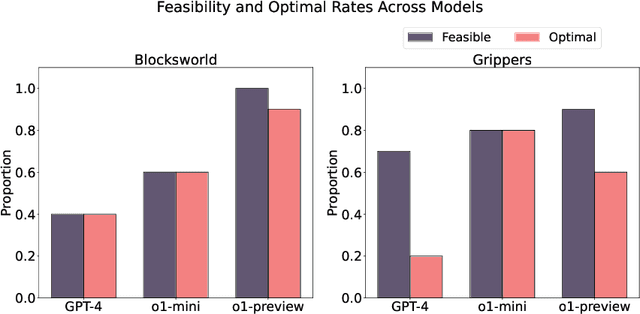
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $\textit{Barman}$, $\textit{Tyreworld}$) and spatially complex environments (e.g., $\textit{Termes}$, $\textit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning.
MM3DGS SLAM: Multi-modal 3D Gaussian Splatting for SLAM Using Vision, Depth, and Inertial Measurements
Apr 01, 2024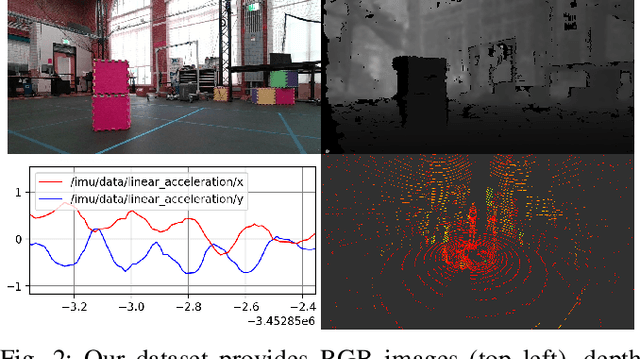


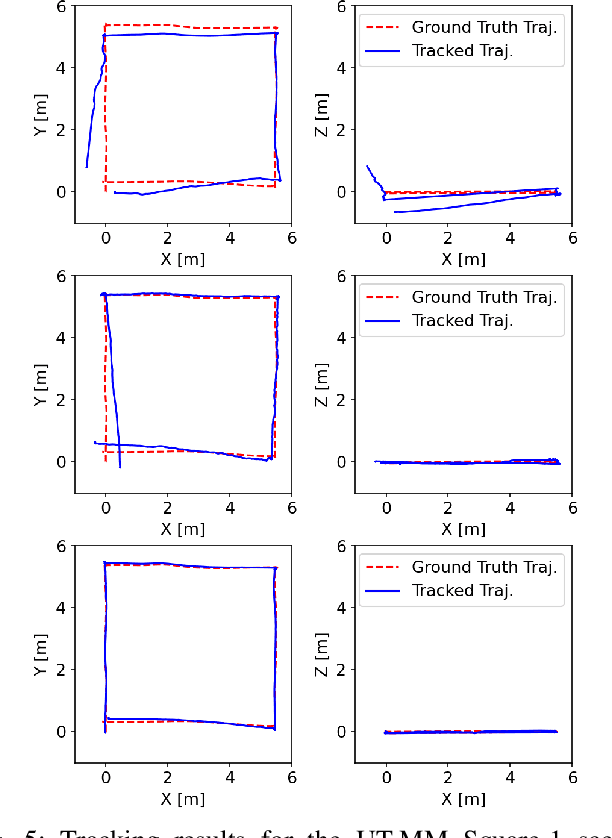
Simultaneous localization and mapping is essential for position tracking and scene understanding. 3D Gaussian-based map representations enable photorealistic reconstruction and real-time rendering of scenes using multiple posed cameras. We show for the first time that using 3D Gaussians for map representation with unposed camera images and inertial measurements can enable accurate SLAM. Our method, MM3DGS, addresses the limitations of prior neural radiance field-based representations by enabling faster rendering, scale awareness, and improved trajectory tracking. Our framework enables keyframe-based mapping and tracking utilizing loss functions that incorporate relative pose transformations from pre-integrated inertial measurements, depth estimates, and measures of photometric rendering quality. We also release a multi-modal dataset, UT-MM, collected from a mobile robot equipped with a camera and an inertial measurement unit. Experimental evaluation on several scenes from the dataset shows that MM3DGS achieves 3x improvement in tracking and 5% improvement in photometric rendering quality compared to the current 3DGS SLAM state-of-the-art, while allowing real-time rendering of a high-resolution dense 3D map. Project Webpage: https://vita-group.github.io/MM3DGS-SLAM
Comp4D: LLM-Guided Compositional 4D Scene Generation
Mar 25, 2024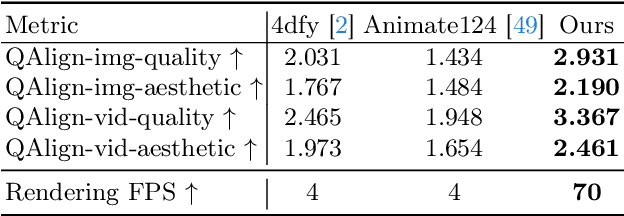
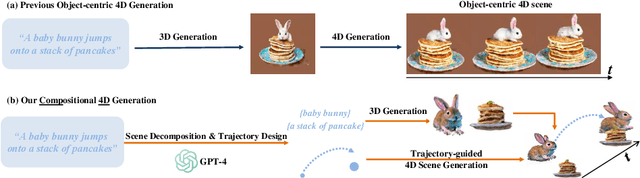

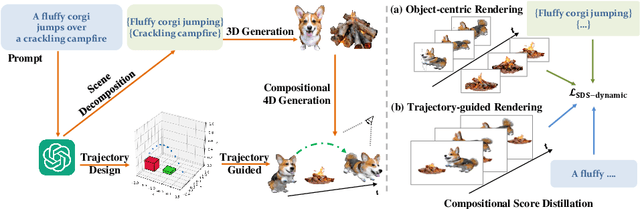
Recent advancements in diffusion models for 2D and 3D content creation have sparked a surge of interest in generating 4D content. However, the scarcity of 3D scene datasets constrains current methodologies to primarily object-centric generation. To overcome this limitation, we present Comp4D, a novel framework for Compositional 4D Generation. Unlike conventional methods that generate a singular 4D representation of the entire scene, Comp4D innovatively constructs each 4D object within the scene separately. Utilizing Large Language Models (LLMs), the framework begins by decomposing an input text prompt into distinct entities and maps out their trajectories. It then constructs the compositional 4D scene by accurately positioning these objects along their designated paths. To refine the scene, our method employs a compositional score distillation technique guided by the pre-defined trajectories, utilizing pre-trained diffusion models across text-to-image, text-to-video, and text-to-3D domains. Extensive experiments demonstrate our outstanding 4D content creation capability compared to prior arts, showcasing superior visual quality, motion fidelity, and enhanced object interactions.
WATonoBus: An All Weather Autonomous Shuttle
Dec 01, 2023



Autonomous vehicle all-weather operation poses significant challenges, encompassing modules from perception and decision-making to path planning and control. The complexity arises from the need to address adverse weather conditions like rain, snow, and fog across the autonomy stack. Conventional model-based and single-module approaches often lack holistic integration with upstream or downstream tasks. We tackle this problem by proposing a multi-module and modular system architecture with considerations for adverse weather across the perception level, through features such as snow covered curb detection, to decision-making and safety monitoring. Through daily weekday service on the WATonoBus platform for almost a year, we demonstrate that our proposed approach is capable of addressing adverse weather conditions and provide valuable learning from edge cases observed during operation.
Fine-Tuning Language Models Using Formal Methods Feedback
Oct 27, 2023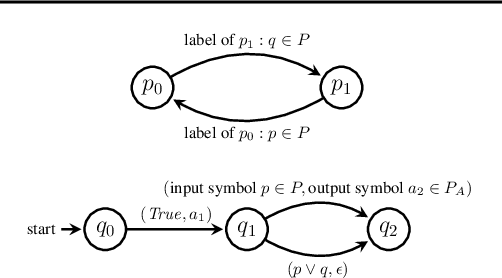
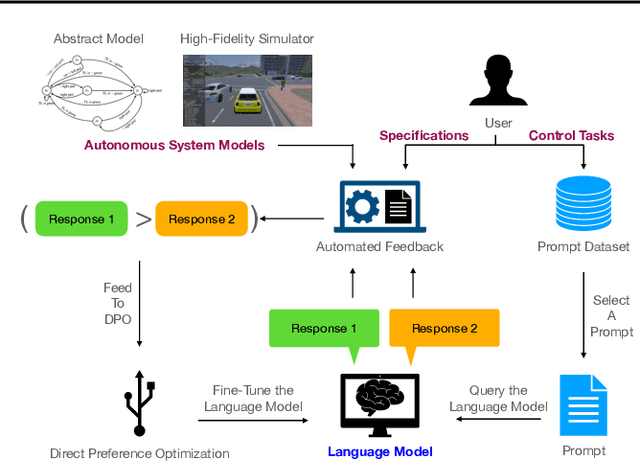

Although pre-trained language models encode generic knowledge beneficial for planning and control, they may fail to generate appropriate control policies for domain-specific tasks. Existing fine-tuning methods use human feedback to address this limitation, however, sourcing human feedback is labor intensive and costly. We present a fully automated approach to fine-tune pre-trained language models for applications in autonomous systems, bridging the gap between generic knowledge and domain-specific requirements while reducing cost. The method synthesizes automaton-based controllers from pre-trained models guided by natural language task descriptions. These controllers are verifiable against independently provided specifications within a world model, which can be abstract or obtained from a high-fidelity simulator. Controllers with high compliance with the desired specifications receive higher ranks, guiding the iterative fine-tuning process. We provide quantitative evidences, primarily in autonomous driving, to demonstrate the method's effectiveness across multiple tasks. The results indicate an improvement in percentage of specifications satisfied by the controller from 60% to 90%.