 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePessimistic Iterative Planning for Robust POMDPs
Aug 16, 2024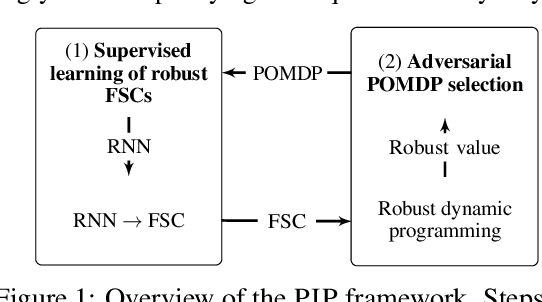
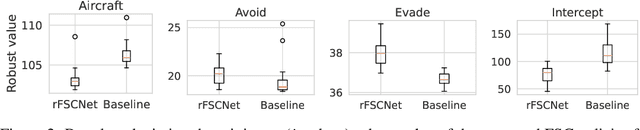
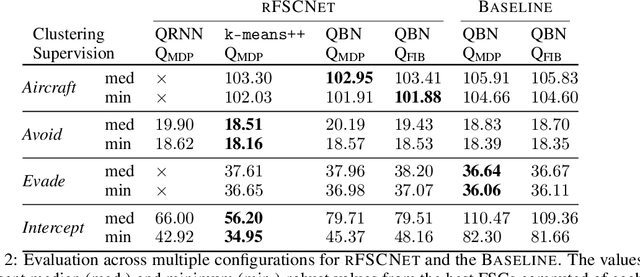
Robust partially observable Markov decision processes (robust POMDPs) extend classical POMDPs to handle additional uncertainty on the transition and observation probabilities via so-called uncertainty sets. Policies for robust POMDPs must not only be memory-based to account for partial observability but also robust against model uncertainty to account for the worst-case instances from the uncertainty sets. We propose the pessimistic iterative planning (PIP) framework, which finds robust memory-based policies for robust POMDPs. PIP alternates between two main steps: (1) selecting an adversarial (non-robust) POMDP via worst-case probability instances from the uncertainty sets; and (2) computing a finite-state controller (FSC) for this adversarial POMDP. We evaluate the performance of this FSC on the original robust POMDP and use this evaluation in step (1) to select the next adversarial POMDP. Within PIP, we propose the rFSCNet algorithm. In each iteration, rFSCNet finds an FSC through a recurrent neural network trained using supervision policies optimized for the adversarial POMDP. The empirical evaluation in four benchmark environments showcases improved robustness against a baseline method in an ablation study and competitive performance compared to a state-of-the-art robust POMDP solver.
Formal Methods for Autonomous Systems
Nov 02, 2023
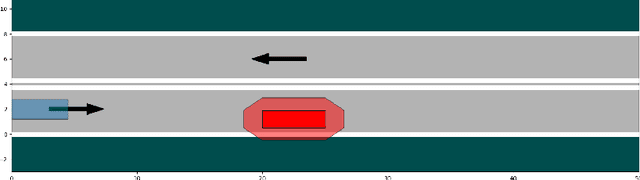
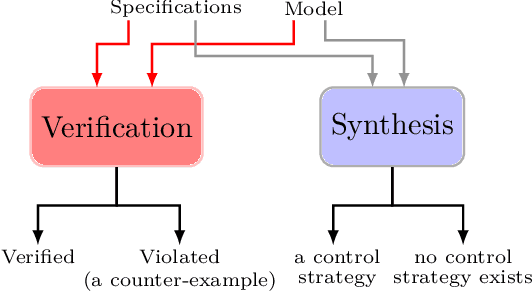
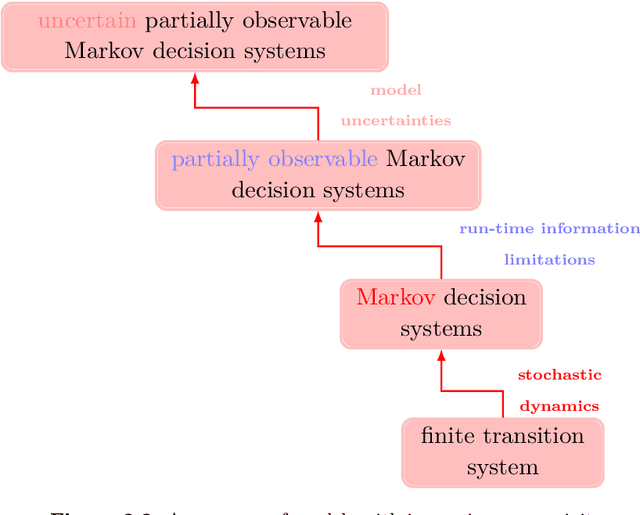
Formal methods refer to rigorous, mathematical approaches to system development and have played a key role in establishing the correctness of safety-critical systems. The main building blocks of formal methods are models and specifications, which are analogous to behaviors and requirements in system design and give us the means to verify and synthesize system behaviors with formal guarantees. This monograph provides a survey of the current state of the art on applications of formal methods in the autonomous systems domain. We consider correct-by-construction synthesis under various formulations, including closed systems, reactive, and probabilistic settings. Beyond synthesizing systems in known environments, we address the concept of uncertainty and bound the behavior of systems that employ learning using formal methods. Further, we examine the synthesis of systems with monitoring, a mitigation technique for ensuring that once a system deviates from expected behavior, it knows a way of returning to normalcy. We also show how to overcome some limitations of formal methods themselves with learning. We conclude with future directions for formal methods in reinforcement learning, uncertainty, privacy, explainability of formal methods, and regulation and certification.
Fine-Tuning Language Models Using Formal Methods Feedback
Oct 27, 2023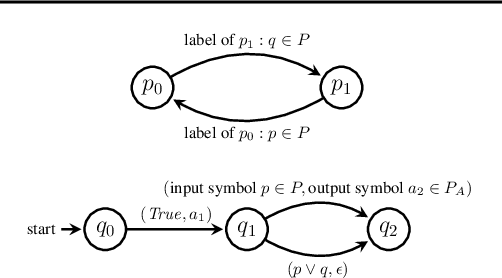
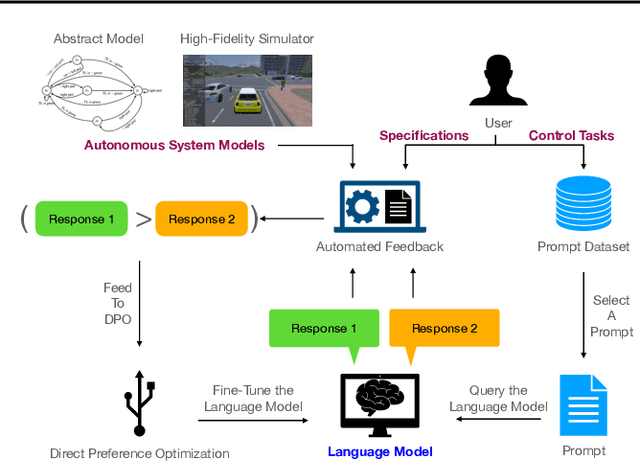

Although pre-trained language models encode generic knowledge beneficial for planning and control, they may fail to generate appropriate control policies for domain-specific tasks. Existing fine-tuning methods use human feedback to address this limitation, however, sourcing human feedback is labor intensive and costly. We present a fully automated approach to fine-tune pre-trained language models for applications in autonomous systems, bridging the gap between generic knowledge and domain-specific requirements while reducing cost. The method synthesizes automaton-based controllers from pre-trained models guided by natural language task descriptions. These controllers are verifiable against independently provided specifications within a world model, which can be abstract or obtained from a high-fidelity simulator. Controllers with high compliance with the desired specifications receive higher ranks, guiding the iterative fine-tuning process. We provide quantitative evidences, primarily in autonomous driving, to demonstrate the method's effectiveness across multiple tasks. The results indicate an improvement in percentage of specifications satisfied by the controller from 60% to 90%.
Safe Reinforcement Learning via Shielding for POMDPs
Apr 02, 2022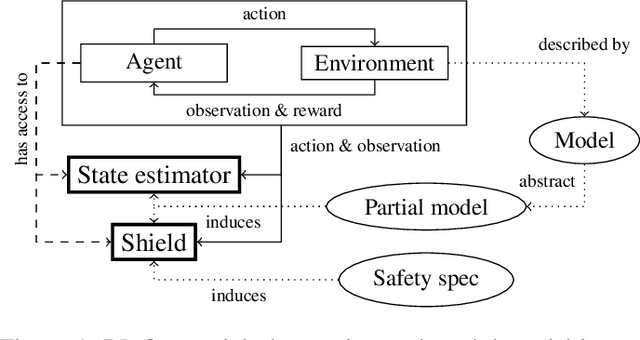
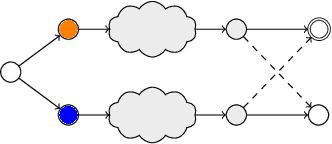

Reinforcement learning (RL) in safety-critical environments requires an agent to avoid decisions with catastrophic consequences. Various approaches addressing the safety of RL exist to mitigate this problem. In particular, so-called shields provide formal safety guarantees on the behavior of RL agents based on (partial) models of the agents' environment. Yet, the state-of-the-art generally assumes perfect sensing capabilities of the agents, which is unrealistic in real-life applications. The standard models to capture scenarios with limited sensing are partially observable Markov decision processes (POMDPs). Safe RL for these models remains an open problem so far. We propose and thoroughly evaluate a tight integration of formally-verified shields for POMDPs with state-of-the-art deep RL algorithms and create an efficacious method that safely learns policies under partial observability. We empirically demonstrate that an RL agent using a shield, beyond being safe, converges to higher values of expected reward. Moreover, shielded agents need an order of magnitude fewer training episodes than unshielded agents, especially in challenging sparse-reward settings.
Dynamic Certification for Autonomous Systems
Mar 21, 2022
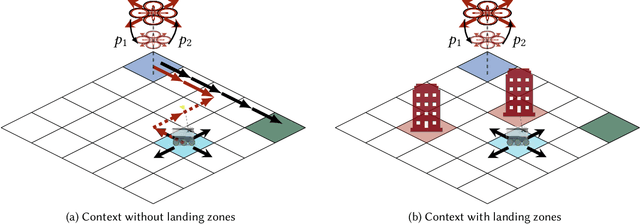
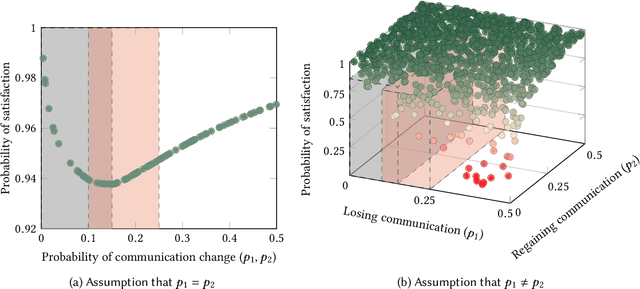
Autonomous systems are often deployed in complex sociotechnical environments, such as public roads, where they must behave safely and securely. Unlike many traditionally engineered systems, autonomous systems are expected to behave predictably in varying "open world" environmental contexts that cannot be fully specified formally. As a result, assurance about autonomous systems requires us to develop new certification methods and mathematical tools that can bound the uncertainty engendered by these diverse deployment scenarios, rather than relying on static tools.
Verifiable RNN-Based Policies for POMDPs Under Temporal Logic Constraints
Feb 13, 2020
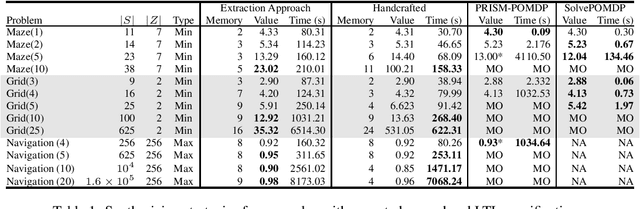
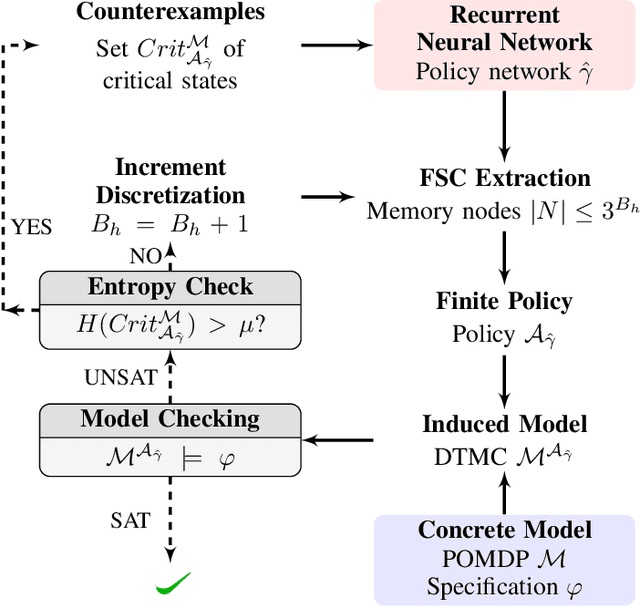
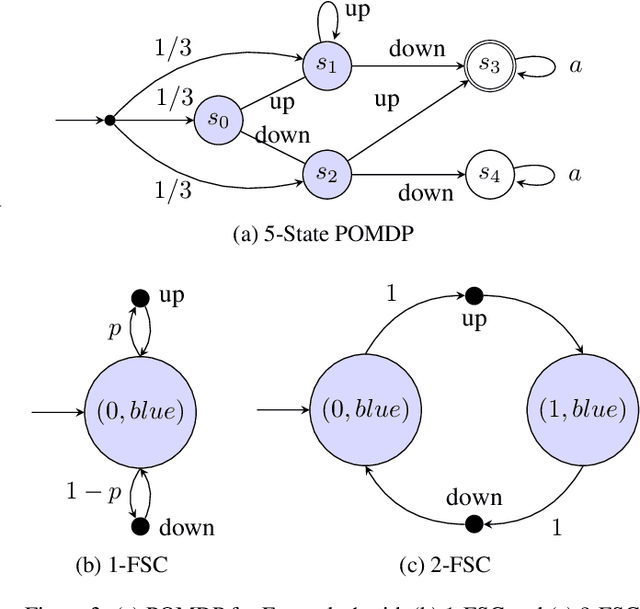
Recurrent neural networks (RNNs) have emerged as an effective representation of control policies in sequential decision-making problems. However, a major drawback in the application of RNN-based policies is the difficulty in providing formal guarantees on the satisfaction of behavioral specifications, e.g. safety and/or reachability. By integrating techniques from formal methods and machine learning, we propose an approach to automatically extract a finite-state controller (FSC) from an RNN, which, when composed with a finite-state system model, is amenable to existing formal verification tools. Specifically, we introduce an iterative modification to the so-called quantized bottleneck insertion technique to create an FSC as a randomized policy with memory. For the cases in which the resulting FSC fails to satisfy the specification, verification generates diagnostic information. We utilize this information to either adjust the amount of memory in the extracted FSC or perform focused retraining of the RNN. While generally applicable, we detail the resulting iterative procedure in the context of policy synthesis for partially observable Markov decision processes (POMDPs), which is known to be notoriously hard. The numerical experiments show that the proposed approach outperforms traditional POMDP synthesis methods by 3 orders of magnitude within 2% of optimal benchmark values.
Counterexample-Guided Strategy Improvement for POMDPs Using Recurrent Neural Networks
Mar 21, 2019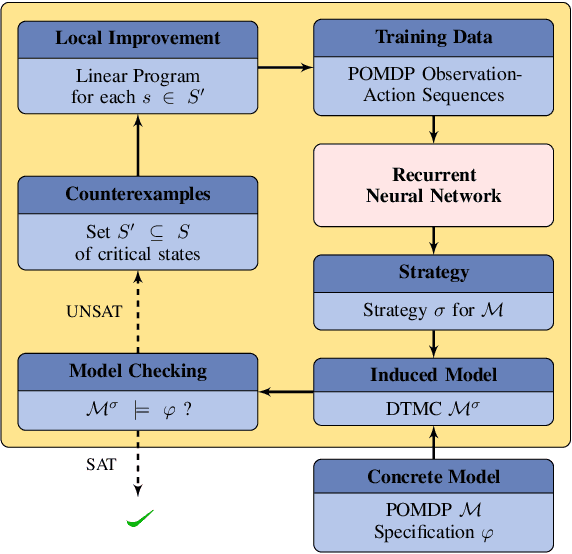
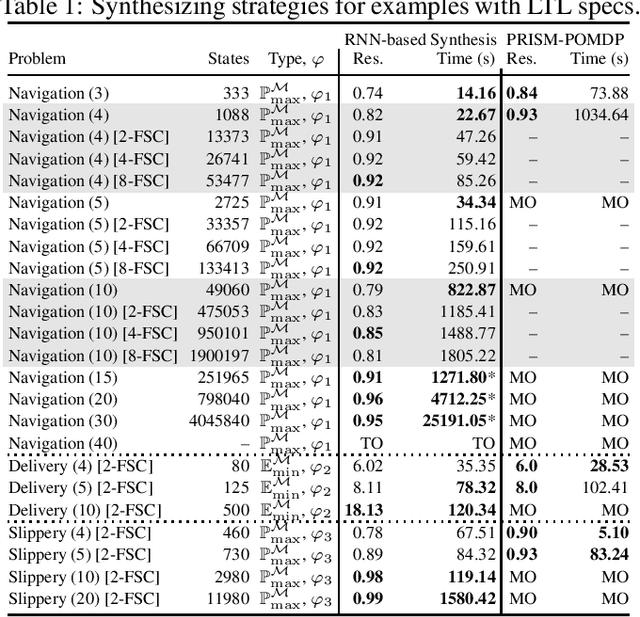
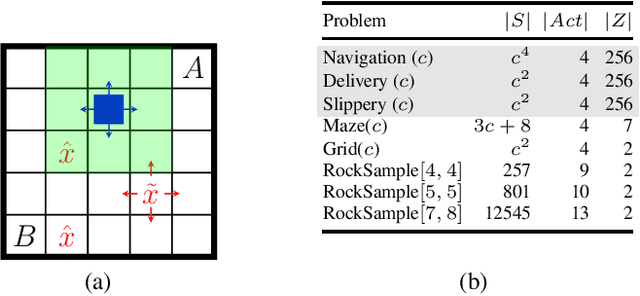
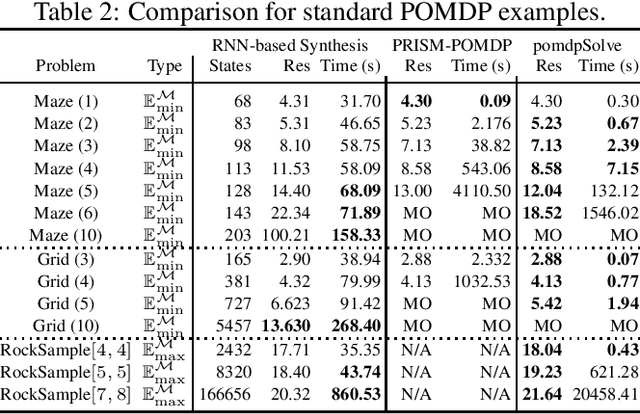
We study strategy synthesis for partially observable Markov decision processes (POMDPs). The particular problem is to determine strategies that provably adhere to (probabilistic) temporal logic constraints. This problem is computationally intractable and theoretically hard. We propose a novel method that combines techniques from machine learning and formal verification. First, we train a recurrent neural network (RNN) to encode POMDP strategies. The RNN accounts for memory-based decisions without the need to expand the full belief space of a POMDP. Secondly, we restrict the RNN-based strategy to represent a finite-memory strategy and implement it on a specific POMDP. For the resulting finite Markov chain, efficient formal verification techniques provide provable guarantees against temporal logic specifications. If the specification is not satisfied, counterexamples supply diagnostic information. We use this information to improve the strategy by iteratively training the RNN. Numerical experiments show that the proposed method elevates the state of the art in POMDP solving by up to three orders of magnitude in terms of solving times and model sizes.
Human-in-the-Loop Synthesis for Partially Observable Markov Decision Processes
Feb 27, 2018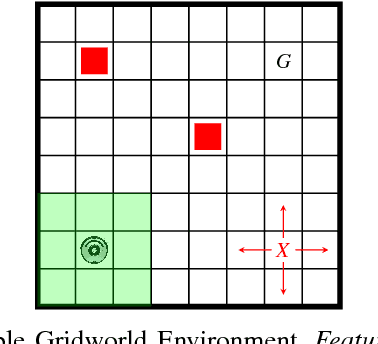
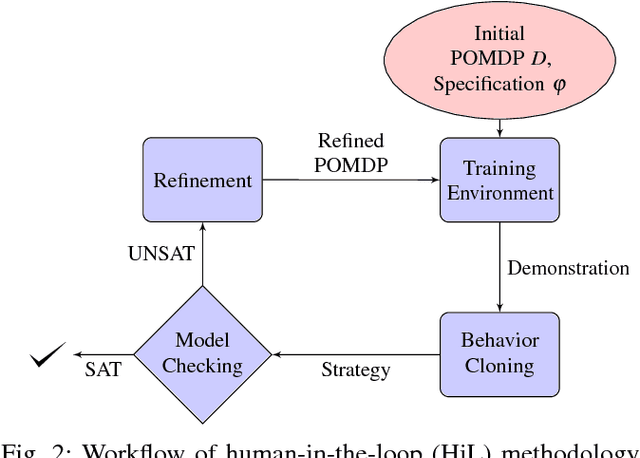
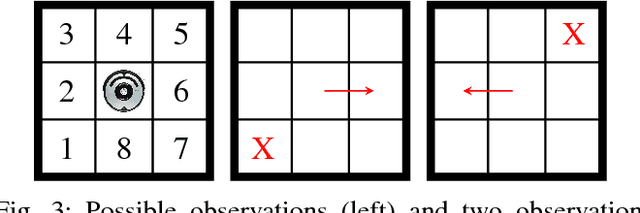
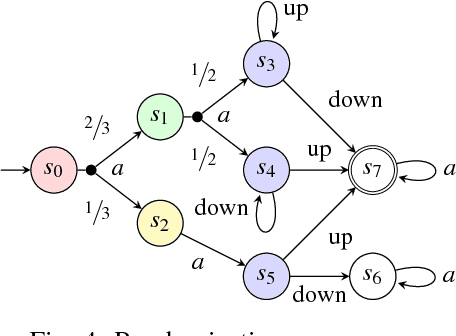
We study planning problems where autonomous agents operate inside environments that are subject to uncertainties and not fully observable. Partially observable Markov decision processes (POMDPs) are a natural formal model to capture such problems. Because of the potentially huge or even infinite belief space in POMDPs, synthesis with safety guarantees is, in general, computationally intractable. We propose an approach that aims to circumvent this difficulty: in scenarios that can be partially or fully simulated in a virtual environment, we actively integrate a human user to control an agent. While the user repeatedly tries to safely guide the agent in the simulation, we collect data from the human input. Via behavior cloning, we translate the data into a strategy for the POMDP. The strategy resolves all nondeterminism and non-observability of the POMDP, resulting in a discrete-time Markov chain (MC). The efficient verification of this MC gives quantitative insights into the quality of the inferred human strategy by proving or disproving given system specifications. For the case that the quality of the strategy is not sufficient, we propose a refinement method using counterexamples presented to the human. Experiments show that by including humans into the POMDP verification loop we improve the state of the art by orders of magnitude in terms of scalability.
Quantifying homologous proteins and proteoforms
Aug 05, 2017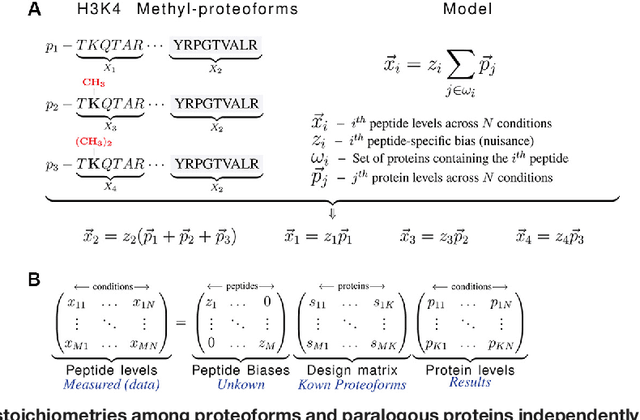
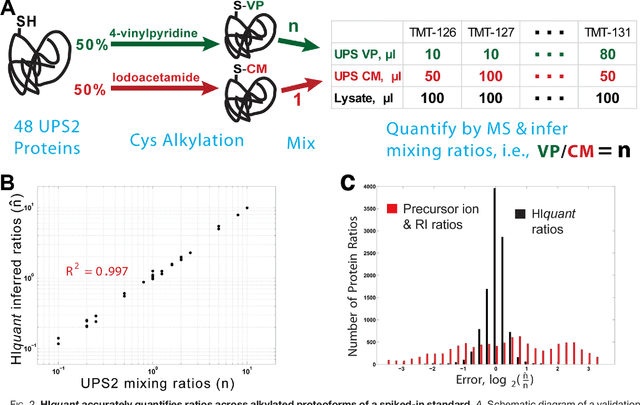
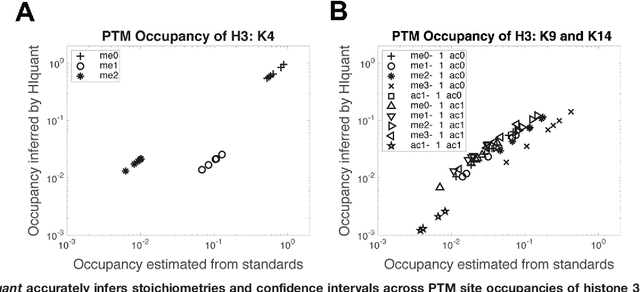

Many proteoforms - arising from alternative splicing, post-translational modifications (PTMs), or paralogous genes - have distinct biological functions, such as histone PTM proteoforms. However, their quantification by existing bottom-up mass-spectrometry (MS) methods is undermined by peptide-specific biases. To avoid these biases, we developed and implemented a first-principles model (HIquant) for quantifying proteoform stoichiometries. We characterized when MS data allow inferring proteoform stoichiometries by HIquant, derived an algorithm for optimal inference, and demonstrated experimentally high accuracy in quantifying fractional PTM occupancy without using external standards, even in the challenging case of the histone modification code. HIquant server is implemented at: https://web.northeastern.edu/slavov/2014_HIquant/