 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Reinforcement Learning via Shielding for POMDPs
Paper and Code
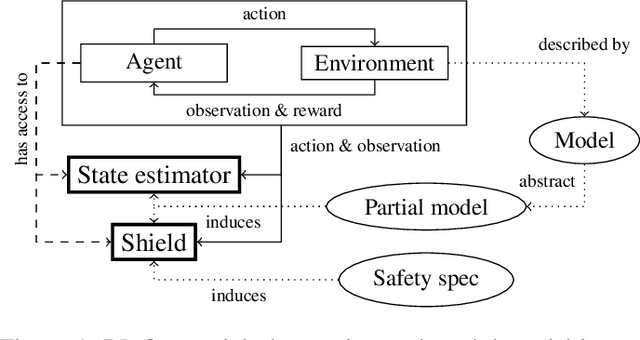
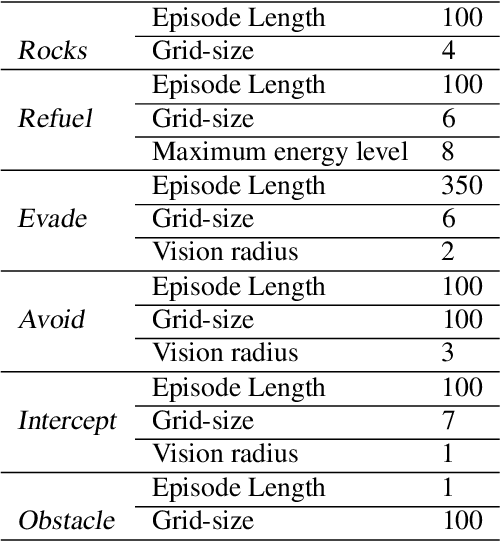

Reinforcement learning (RL) in safety-critical environments requires an agent to avoid decisions with catastrophic consequences. Various approaches addressing the safety of RL exist to mitigate this problem. In particular, so-called shields provide formal safety guarantees on the behavior of RL agents based on (partial) models of the agents' environment. Yet, the state-of-the-art generally assumes perfect sensing capabilities of the agents, which is unrealistic in real-life applications. The standard models to capture scenarios with limited sensing are partially observable Markov decision processes (POMDPs). Safe RL for these models remains an open problem so far. We propose and thoroughly evaluate a tight integration of formally-verified shields for POMDPs with state-of-the-art deep RL algorithms and create an efficacious method that safely learns policies under partial observability. We empirically demonstrate that an RL agent using a shield, beyond being safe, converges to higher values of expected reward. Moreover, shielded agents need an order of magnitude fewer training episodes than unshielded agents, especially in challenging sparse-reward settings.