 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Vision-Language-Action Planning & Search
Jan 02, 2026Vision-Language-Action (VLA) models have emerged as powerful generalist policies for robotic manipulation, yet they remain fundamentally limited by their reliance on behavior cloning, leading to brittleness under distribution shift. While augmenting pretrained models with test-time search algorithms like Monte Carlo Tree Search (MCTS) can mitigate these failures, existing formulations rely solely on the VLA prior for guidance, lacking a grounded estimate of expected future return. Consequently, when the prior is inaccurate, the planner can only correct action selection via the exploration term, which requires extensive simulation to become effective. To address this limitation, we introduce Value Vision-Language-Action Planning and Search (V-VLAPS), a framework that augments MCTS with a lightweight, learnable value function. By training a simple multilayer perceptron (MLP) on the latent representations of a fixed VLA backbone (Octo), we provide the search with an explicit success signal that biases action selection toward high-value regions. We evaluate V-VLAPS on the LIBERO robotic manipulation suite, demonstrating that our value-guided search improves success rates by over 5 percentage points while reducing the average number of MCTS simulations by 5-15 percent compared to baselines that rely only on the VLA prior.
ARM-FM: Automated Reward Machines via Foundation Models for Compositional Reinforcement Learning
Oct 16, 2025Reinforcement learning (RL) algorithms are highly sensitive to reward function specification, which remains a central challenge limiting their broad applicability. We present ARM-FM: Automated Reward Machines via Foundation Models, a framework for automated, compositional reward design in RL that leverages the high-level reasoning capabilities of foundation models (FMs). Reward machines (RMs) -- an automata-based formalism for reward specification -- are used as the mechanism for RL objective specification, and are automatically constructed via the use of FMs. The structured formalism of RMs yields effective task decompositions, while the use of FMs enables objective specifications in natural language. Concretely, we (i) use FMs to automatically generate RMs from natural language specifications; (ii) associate language embeddings with each RM automata-state to enable generalization across tasks; and (iii) provide empirical evidence of ARM-FM's effectiveness in a diverse suite of challenging environments, including evidence of zero-shot generalization.
Multi-Fidelity Policy Gradient Algorithms
Mar 07, 2025Many reinforcement learning (RL) algorithms require large amounts of data, prohibiting their use in applications where frequent interactions with operational systems are infeasible, or high-fidelity simulations are expensive or unavailable. Meanwhile, low-fidelity simulators--such as reduced-order models, heuristic reward functions, or generative world models--can cheaply provide useful data for RL training, even if they are too coarse for direct sim-to-real transfer. We propose multi-fidelity policy gradients (MFPGs), an RL framework that mixes a small amount of data from the target environment with a large volume of low-fidelity simulation data to form unbiased, reduced-variance estimators (control variates) for on-policy policy gradients. We instantiate the framework by developing multi-fidelity variants of two policy gradient algorithms: REINFORCE and proximal policy optimization. Experimental results across a suite of simulated robotics benchmark problems demonstrate that when target-environment samples are limited, MFPG achieves up to 3.9x higher reward and improves training stability when compared to baselines that only use high-fidelity data. Moreover, even when the baselines are given more high-fidelity samples--up to 10x as many interactions with the target environment--MFPG continues to match or outperform them. Finally, we observe that MFPG is capable of training effective policies even when the low-fidelity environment is drastically different from the target environment. MFPG thus not only offers a novel paradigm for efficient sim-to-real transfer but also provides a principled approach to managing the trade-off between policy performance and data collection costs.
Neural Port-Hamiltonian Differential Algebraic Equations for Compositional Learning of Electrical Networks
Dec 15, 2024We develop compositional learning algorithms for coupled dynamical systems. While deep learning has proven effective at modeling complex relationships from data, compositional couplings between system components typically introduce algebraic constraints on state variables, posing challenges to many existing data-driven approaches to modeling dynamical systems. Towards developing deep learning models for constrained dynamical systems, we introduce neural port-Hamiltonian differential algebraic equations (N-PHDAEs), which use neural networks to parametrize unknown terms in both the differential and algebraic components of a port-Hamiltonian DAE. To train these models, we propose an algorithm that uses automatic differentiation to perform index reduction, automatically transforming the neural DAE into an equivalent system of neural ordinary differential equations (N-ODEs), for which established model inference and backpropagation methods exist. The proposed compositional modeling framework and learning algorithms may be applied broadly to learn control-oriented models of dynamical systems in a variety of application areas, however, in this work, we focus on their application to the modeling of electrical networks. Experiments simulating the dynamics of nonlinear circuits exemplify the benefits of our approach: the proposed N-PHDAE model achieves an order of magnitude improvement in prediction accuracy and constraint satisfaction when compared to a baseline N-ODE over long prediction time horizons. We also validate the compositional capabilities of our approach through experiments on a simulated D.C. microgrid: we train individual N-PHDAE models for separate grid components, before coupling them to accurately predict the behavior of larger-scale networks.
A Multifidelity Sim-to-Real Pipeline for Verifiable and Compositional Reinforcement Learning
Dec 02, 2023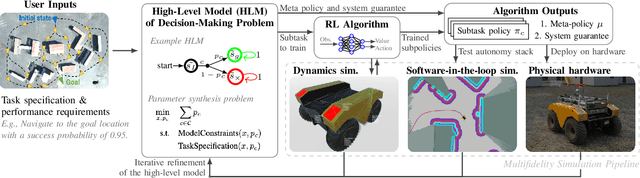



We propose and demonstrate a compositional framework for training and verifying reinforcement learning (RL) systems within a multifidelity sim-to-real pipeline, in order to deploy reliable and adaptable RL policies on physical hardware. By decomposing complex robotic tasks into component subtasks and defining mathematical interfaces between them, the framework allows for the independent training and testing of the corresponding subtask policies, while simultaneously providing guarantees on the overall behavior that results from their composition. By verifying the performance of these subtask policies using a multifidelity simulation pipeline, the framework not only allows for efficient RL training, but also for a refinement of the subtasks and their interfaces in response to challenges arising from discrepancies between simulation and reality. In an experimental case study we apply the framework to train and deploy a compositional RL system that successfully pilots a Warthog unmanned ground robot.
Formal Methods for Autonomous Systems
Nov 02, 2023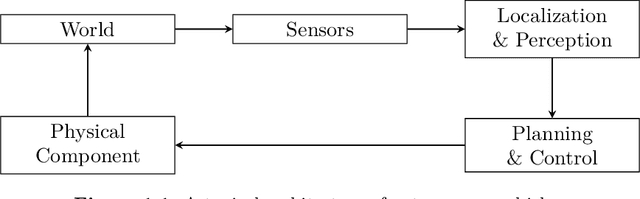
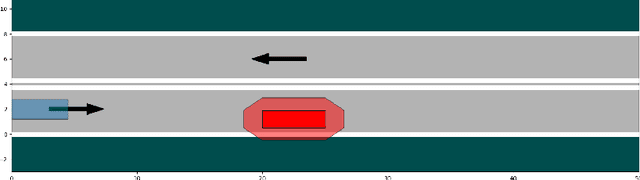
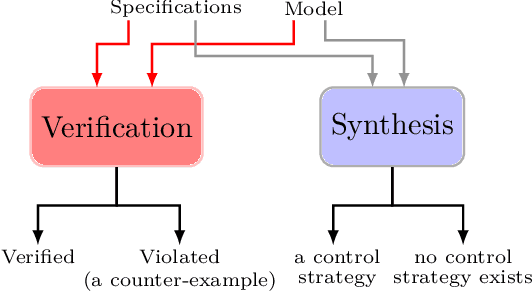
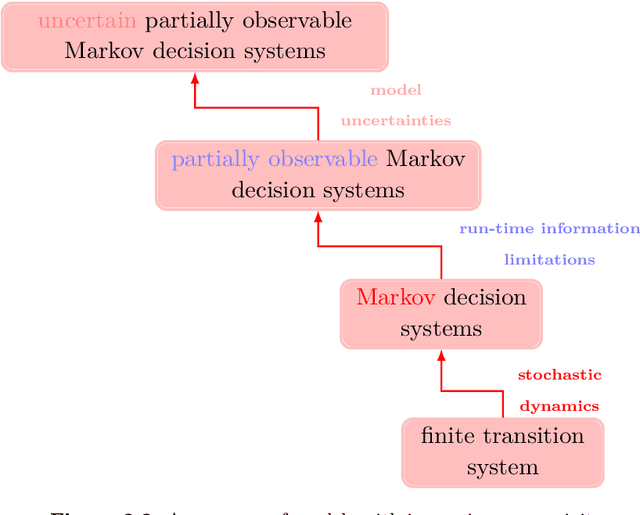
Formal methods refer to rigorous, mathematical approaches to system development and have played a key role in establishing the correctness of safety-critical systems. The main building blocks of formal methods are models and specifications, which are analogous to behaviors and requirements in system design and give us the means to verify and synthesize system behaviors with formal guarantees. This monograph provides a survey of the current state of the art on applications of formal methods in the autonomous systems domain. We consider correct-by-construction synthesis under various formulations, including closed systems, reactive, and probabilistic settings. Beyond synthesizing systems in known environments, we address the concept of uncertainty and bound the behavior of systems that employ learning using formal methods. Further, we examine the synthesis of systems with monitoring, a mitigation technique for ensuring that once a system deviates from expected behavior, it knows a way of returning to normalcy. We also show how to overcome some limitations of formal methods themselves with learning. We conclude with future directions for formal methods in reinforcement learning, uncertainty, privacy, explainability of formal methods, and regulation and certification.
Verifiable Reinforcement Learning Systems via Compositionality
Sep 09, 2023We propose a framework for verifiable and compositional reinforcement learning (RL) in which a collection of RL subsystems, each of which learns to accomplish a separate subtask, are composed to achieve an overall task. The framework consists of a high-level model, represented as a parametric Markov decision process, which is used to plan and analyze compositions of subsystems, and of the collection of low-level subsystems themselves. The subsystems are implemented as deep RL agents operating under partial observability. By defining interfaces between the subsystems, the framework enables automatic decompositions of task specifications, e.g., reach a target set of states with a probability of at least 0.95, into individual subtask specifications, i.e. achieve the subsystem's exit conditions with at least some minimum probability, given that its entry conditions are met. This in turn allows for the independent training and testing of the subsystems. We present theoretical results guaranteeing that if each subsystem learns a policy satisfying its subtask specification, then their composition is guaranteed to satisfy the overall task specification. Conversely, if the subtask specifications cannot all be satisfied by the learned policies, we present a method, formulated as the problem of finding an optimal set of parameters in the high-level model, to automatically update the subtask specifications to account for the observed shortcomings. The result is an iterative procedure for defining subtask specifications, and for training the subsystems to meet them. Experimental results demonstrate the presented framework's novel capabilities in environments with both full and partial observability, discrete and continuous state and action spaces, as well as deterministic and stochastic dynamics.
Multimodal Pretrained Models for Sequential Decision-Making: Synthesis, Verification, Grounding, and Perception
Aug 10, 2023Recently developed pretrained models can encode rich world knowledge expressed in multiple modalities, such as text and images. However, the outputs of these models cannot be integrated into algorithms to solve sequential decision-making tasks. We develop an algorithm that utilizes the knowledge from pretrained models to construct and verify controllers for sequential decision-making tasks, and to ground these controllers to task environments through visual observations. In particular, the algorithm queries a pretrained model with a user-provided, text-based task description and uses the model's output to construct an automaton-based controller that encodes the model's task-relevant knowledge. It then verifies whether the knowledge encoded in the controller is consistent with other independently available knowledge, which may include abstract information on the environment or user-provided specifications. If this verification step discovers any inconsistency, the algorithm automatically refines the controller to resolve the inconsistency. Next, the algorithm leverages the vision and language capabilities of pretrained models to ground the controller to the task environment. It collects image-based observations from the task environment and uses the pretrained model to link these observations to the text-based control logic encoded in the controller (e.g., actions and conditions that trigger the actions). We propose a mechanism to ensure the controller satisfies the user-provided specification even when perceptual uncertainties are present. We demonstrate the algorithm's ability to construct, verify, and ground automaton-based controllers through a suite of real-world tasks, including daily life and robot manipulation tasks.
How to Learn and Generalize From Three Minutes of Data: Physics-Constrained and Uncertainty-Aware Neural Stochastic Differential Equations
Jun 10, 2023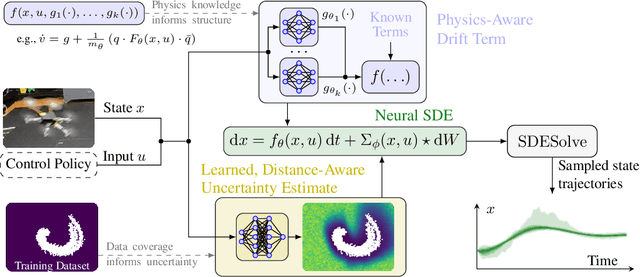
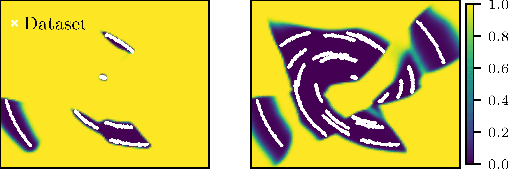
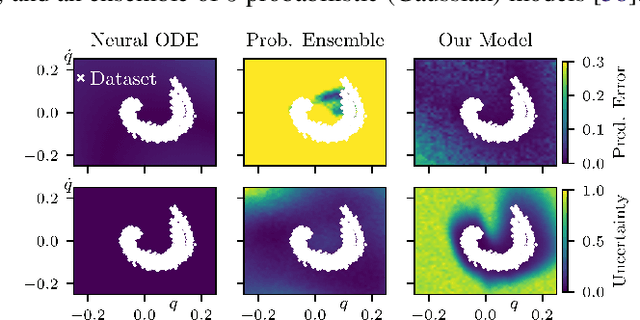
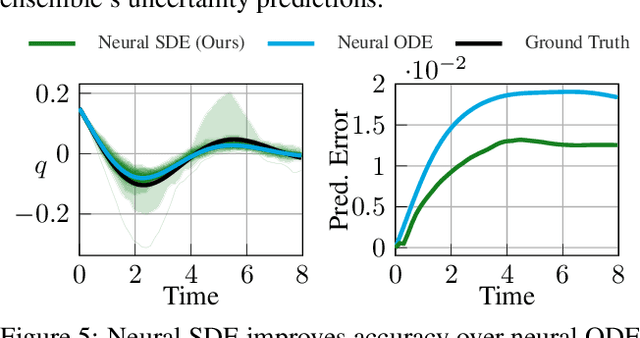
We present a framework and algorithms to learn controlled dynamics models using neural stochastic differential equations (SDEs) -- SDEs whose drift and diffusion terms are both parametrized by neural networks. We construct the drift term to leverage a priori physics knowledge as inductive bias, and we design the diffusion term to represent a distance-aware estimate of the uncertainty in the learned model's predictions -- it matches the system's underlying stochasticity when evaluated on states near those from the training dataset, and it predicts highly stochastic dynamics when evaluated on states beyond the training regime. The proposed neural SDEs can be evaluated quickly enough for use in model predictive control algorithms, or they can be used as simulators for model-based reinforcement learning. Furthermore, they make accurate predictions over long time horizons, even when trained on small datasets that cover limited regions of the state space. We demonstrate these capabilities through experiments on simulated robotic systems, as well as by using them to model and control a hexacopter's flight dynamics: A neural SDE trained using only three minutes of manually collected flight data results in a model-based control policy that accurately tracks aggressive trajectories that push the hexacopter's velocity and Euler angles to nearly double the maximum values observed in the training dataset.
Differential Privacy in Cooperative Multiagent Planning
Jan 20, 2023



Privacy-aware multiagent systems must protect agents' sensitive data while simultaneously ensuring that agents accomplish their shared objectives. Towards this goal, we propose a framework to privatize inter-agent communications in cooperative multiagent decision-making problems. We study sequential decision-making problems formulated as cooperative Markov games with reach-avoid objectives. We apply a differential privacy mechanism to privatize agents' communicated symbolic state trajectories, and then we analyze tradeoffs between the strength of privacy and the team's performance. For a given level of privacy, this tradeoff is shown to depend critically upon the total correlation among agents' state-action processes. We synthesize policies that are robust to privacy by reducing the value of the total correlation. Numerical experiments demonstrate that the team's performance under these policies decreases by only 3 percent when comparing private versus non-private implementations of communication. By contrast, the team's performance decreases by roughly 86 percent when using baseline policies that ignore total correlation and only optimize team performance.